图像生成

GPT-4o图像生成能力集成GPTs,开启个性化图像机器人新篇章
OpenAI宣布GPT-4o的图像生成能力正式集成到GPTs(自定义GPT)平台,为开发者与创作者提供了构建个性化图像生成机器人的强大工具。 据AIbase了解,这一更新允许用户通过GPTs打造专属图像生成应用,如海报设计机器人或特定艺术风格生成器,极大地提升了创作灵活性与共享性。 社交平台上的热烈讨论凸显了其广泛影响力,相关功能已向ChatGPT Plus、Pro及Team用户开放。
GPT-4o图像生成功能现已集成至自定义GPTs
2025年4月26日 AIbase报道:OpenAI近日宣布,其旗舰多模态模型GPT-4o的图像生成功能现已正式集成至ChatGPT的自定义GPTs功能中。 这一更新标志着用户创建的定制化AI助手能够直接生成和编辑图像,为内容创作、设计和教育等领域带来更多可能性。 无缝集成的图像生成体验GPT-4o的图像生成功能此前已于2025年3月25日起在ChatGPT和Sora平台向免费、Plus、Pro和Team用户逐步开放。

UniToken:多模态AI的“全能选手”,一次编码搞定图文理解与图像生成!
首次在统一框架内实现理解与生成的“双优表现”,打破了多模态统一建模的僵局! 复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。 UniToken通过融合连续和离散视觉表征,有效缓解了以往方法中“任务干扰”和“表示割裂”的问题,为多模态统一建模提供了新的范式。

三星研究院推出新型自回归 Transformer,助力高分辨率图像生成
在图像生成领域,技术的进步不断推动着虚拟现实等应用的发展。 最近,三星研究院提出了一种基于自回归建模的新方法,旨在提升图像生成的保真度和可扩展性。 与传统的一次性生成整个场景的方法不同,该方法采用了逐步添加细节的策略,使图像的生成过程更符合人类的创作习惯。

AI大模型看手相!图片视频加持深度思考,阿里QVQ-Max“神了神了”
阿里又发了个有意思的大模型——QVQ-Max,第一版视觉推理模型,对任意图像或视频都可以进行深度思考。 举个有趣的例子,上传一张你的手掌,再点击Thinking,QVQ-Max就可以给你看手相:可以看到,在深度思考过后,QVQ-Max就开始逐步分析手掌上的线条和其他特征。 包括心线、头线、生命线等主要线条的分析,以及戒指手指上的金戒指的象征意义。

ChatGPT 的新 AI 图像功能延迟对免费用户开放
OpenAI 首席执行官萨姆・阿尔特曼在社交媒体上宣布,ChatGPT 新推出的图像功能的上线时间将推迟,原因是用户的需求远远超出了公司的预期。 阿尔特曼表示:“ChatGPT 中的图像功能比我们想象的要受欢迎得多(而且我们的预期已经很高了)。 ”本周二,OpenAI 刚刚推出了 GPT-4o 的原生图像生成功能,允许用户上传和修改图像,并表示该功能将很快向所有用户开放。

OpenAI发布最新图像生成模型:GPT-4o内置多轮对话编辑功能
2025年3月25日,OpenAI宣布其最新图像生成模型正式内置于GPT-4o中,这一突破性升级为用户带来了更强大的图像生成与编辑体验。 据悉,该功能已于今日开始向ChatGPT和Sora的所有Plus、Pro、Team以及免费用户逐步推出。 这一消息迅速引发了科技界的广泛关注。

LuminaBrush 在图像上绘制照明效果的构建交互式工具
LuminaBrushLuminaBrush 是一个构建交互式工具以在图像上绘制照明效果的项目。 该框架采用两阶段方法:第一阶段将图像转换为“均匀照明”的外观,第二阶段利用用户涂鸦生成照明效果。 相关链接HF 演示:: 目前基于 Flux。

腾讯优图提出首个基于DiT的高保真虚拟试衣算法FitDiT
今天介绍的文章来自公众号粉丝投稿,腾讯优图提出首个基于DiT的高保真虚拟试衣算法FitDiT,给定一个人像图像和一个衣物图像,就可以生成一个展示人物穿着所提供衣物的图像。 FitDiT 在虚拟试穿中表现出色,解决了各种场景中与纹理感知保存和尺寸感知试穿相关的挑战。 引言基于图像的虚拟试穿是当前电商场景流行且前景看好的图像合成技术,能够显著改善消费者的购物体验并降低服装商家的广告成本。

李飞飞看中的万亿赛道,中国首个自研空间智能AI登场!单张图即生3D世界
就在刚刚,昆仑万维正式发布了一款全新自研的Matrix-Zero世界模型。 Matrix-Zero世界模型包含两款子模型:昆仑万维自研的3D场景生成大模型与昆仑万维自研的可交互视频生成大模型。 包括两部分功能:支持将用户输入的图片转化为可自由探索的真实合理的3D场景;支持根据用户输入实时生成互动视频效果。
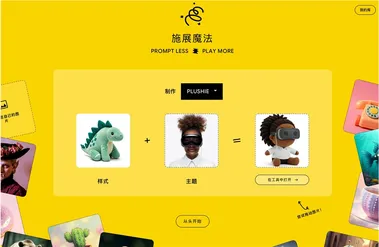
谷歌AI图像混合工具Google Whisk全球上线,覆盖100多个国家
谷歌近日宣布,其基于人工智能的图像混合工具Google Whisk已在全球100多个国家/地区正式推出。 这款工具最初于去年在美国发布,旨在通过创新的图像混合技术,为用户提供更简单、更具创意的图像生成体验。 与传统的图像生成工具不同,Google Whisk允许用户上传三张图像,分别代表主题、场景和风格。

IC-Portrait:打造逼真个性化肖像的新纪元
在数字内容创作、虚拟形象、游戏和增强现实等领域,肖像生成已成为计算机图形学研究的热点。 尽管近年来肖像生成模型取得了显著进展,能够生成越来越逼真和吸引人的肖像,但仍面临诸多挑战。 今天,给大家介绍一种个性化肖像生成框架IC-Portrait,该框架引入了一种创建逼真肖像图像的创新方法。

OpenAI新项目Sora内测图像生成器,或将推出DALL-E 4?
近日,OpenAI 发布了一则引人注目的消息:在其内部测试的项目 Sora 中,除了已经推出的视频生成功能外,图像生成功能也在紧锣密鼓地研发中。 这个新功能让用户能够在视频和图像生成之间快速切换,提升创作的灵活性。 根据内部消息,Sora 将会增加一个隐藏的切换按钮,用户只需在提示栏中选择即可在两种模式之间切换。

谷歌推出Imagen 3图像生成 API,每张仅需0.03美元
谷歌近日宣布,旗下最新的图像生成模型 ——Imagen3,现已通过 Gemini API 向开发者开放。 这个模型不仅具备强大的图像生成能力,还能根据输入的文本提示创造出多种艺术风格的图像,涵盖从超现实主义到动漫角色的广泛范畴。 Imagen3的使用非常简单,开发者只需通过 API 提交文本描述,模型便会迅速生成高质量图像。

阿里通义实验室提出AnyStory:开启个性化文本到图像生成的新篇章!
在这个数字化时代,生成式AI技术正以前所未有的速度改变着我们的创作方式。 近期,阿里通义实验室发表了一篇题为《AnyStory: Towards Unified Single and Multi-Subject Personalization in Text-to-Image Generation》的论文,该论文提出了一种创新的框架,旨在通过统一的路径实现单个及多个主体的个性化文本到图像生成,为故事可视化、艺术创作乃至更多领域带来了革命性的突破。 论文中深入探讨了当前文本到图像生成技术面临的挑战,如主体一致性、细节保留以及多主体个性化等方面的不足。

你要跳舞么?复旦&微软提出StableAnimator:可实现高质量和高保真的ID一致性人类视频生成
本文经AIGC Studio公众号授权转载,转载请联系出处。 由复旦、微软、虎牙、CMU的研究团队提出的StableAnimator框架,实现了高质量和高保真的ID一致性人类视频生成。 StableAnimator 生成的姿势驱动的人体图像动画展示了其合成高保真和 ID 保留视频的能力。

OminiControl:一个新的FLUX通用控制模型,单个模型实现图像主题控制和深度控制
OminiControl 也开源了其可控生成模型。 OminiControl 是一个最小但功能强大的FLUX通用控制框架,可以一个模型实现图像主题控制和深度控制。 比如一个提示词加一个服装图片就能让生成的人物穿上服装。

港大&Adobe提出通用生成框架UniReal:通过学习真实世界动态实现通用图像生成和编辑
本文经AIGC Studio公众号授权转载,转载请联系出处。 今天给大家介绍的文章来自公众号粉丝投稿,由香港大学,Adobe提出的统一图像生产与编辑方法UniReal,将多种图像任务统一成视频生成的范式,并且在大规模视频中学习真实的动态与变化,在指令编辑、图像定制化、图像组合等多种任务达到最佳水准。 上图为UniReal多功能性的展示。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉