图像生成

只需150k数据,多图融合效果超越Qwen-2509,至多支持10图输入!
背景随着图像生成模型的迅速发展,越来越多的condition被加入到生成过程中,开源模型和闭源模型的差距也不断缩小。 然而有一种condition却是最难也最综合的:直接输入多张图像,让模型同时整合来自多张图像的语义信息。 例如结合人物、场景、物体等多种视觉输入,生成ID一致性好又语义丰富的合成结果。
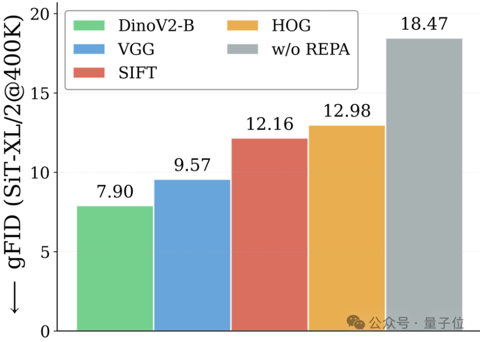
推特吵架吵出篇论文!谢赛宁团队新作iREPA只要3行代码
henry 发自 凹非寺. 量子位 | 公众号 QbitAI要说真学术,还得看推特。 刚刚,谢赛宁自曝团队新作iREPA其实来自4个多月前的,一次与网友的辩论。

锁定角色,「多主体」也可控!个性化文生图,给你PS般交互体验
大型扩散模型(如 Stable Diffusion)让我们能够从文字生成高保真的图像。 但当用户希望「生成我和我的朋友们在不同场景中的照片」时,现有的个性化生成方法(如 DreamBooth、IP-Adapter)仍面临两个根本问题:缺乏交互性:无法自由控制人物的空间位置、大小与关系。 难以扩展到多主体:每多一个人,内存和算力就线性增长。

超越谷歌Banana,字节联合香港中文大学等高校开源最强图像编辑生成系统DreamOmni2
AI图像编辑与生成,正迎来一场体验革命。 香港中文大学,香港科技大学,香港大学和字节跳动共同研发的系统DreamOmni2,实现图像编辑与生成领域最新SOTA。 指令遵循能力全面领先,真正做到指哪打哪。

一图胜千言被实现了!DeepSeek-OCR用图片压缩文本,10倍压缩率
DeepSeek开源了DeepSeek-OCR,用1张图片的信息,还原10页书的文字,10倍的压缩率,可以做到几乎不丢失信息。 视觉编码器走了不少弯路大型语言模型记性不好,或者说,能记住的东西太有限。 你给它一篇长长的文章,它的计算量呈二次方往上飙。

斯坦福与Adobe新研究,模仿蒸馏技术轻松让200亿参数图像生成高质量大模型
高质量图像生成又加速了! 斯坦福大学和 Adobe 研究院联手,用 pi-Flow(基于策略的流模型)技术,让 200 亿参数的文本到图像大模型,在 4 步之内就生成了媲美教师模型的高质量、高多样性图片。 让图像生成模型少走几步所有玩过 AI 绘画的人都有一个共同的体验,未蒸馏的原版大模型,点击生成,看着进度条一点点爬升,从一个模糊的噪声,慢慢变得清晰。

Nano Banana不及格,开源模型一分难求!上海AI Lab新基准直击文生图模型痛点
从GPT-4o到Nano Banana、Seedream 4.0,今年的大模型想要出圈,“画得好”俨然成了必杀技。 不过,在比拼真实感、艺术性方面,生图模型是神仙打架,在“做题”上,现如今的模型们又到底能力几何? 比如,当指令变成画出1-甲基环己烯酸催化水合的反应机理、根据给定的边集画出图的最小生成树,模型能否像相关专业的人类考生一样,真正把知识理解、推理和作图结合在一起?

刚刚,字节登顶世界最强图像AI!一手实测原生4K、10图融合,全网玩疯
谷歌Nano Banana一夜爆火之后,各种邪修玩法儿,至今让全网意犹未尽。 等距视角、多图合成、老照片修复、3D手办.......创意脑洞大开,全网玩疯。 谁曾想,短短半个月后,大洋彼岸就杀出来了一个最强逆袭者!

腾讯开源混元Image 2.1:2K高清+完美文字嵌入,图文天花板来了
今天凌晨,腾讯开源最新图像模型混元Image 2.1。 混元Image 2.1支持原生2K分辨率图像和1000 token的超长篇复杂提示词,并且在文本语义理解和文字嵌入方面非常强几乎完美,能将中英文无缝写入到图像中,很适用于产品封面、插画、海报设计等专业场景此外,腾讯还开源了基于MeanFlow的加速版模型权重,该版本可将推理步数从100步大幅缩减至仅8步,以及业内首个工业级提示词改写模型 PromptEnhancer,能对提示词进行优化,帮助用户生成更细腻、富有表现力的图像。 开源地址: 2.1Github: 2.1?tab=readme-ov-file在线体验: 2.1案例目前,混元Image 2.1已经可以使用,下面给大家展示一下它的生成效果。

设计师大解放!清华发布「建筑平面图」自动生成模型 | ACL'25
建筑平面图是AEC(建筑、工程、施工)领域的核心 「语言」,贯穿设计思想草绘、方案交流与落地执行全流程。 而住宅作为人们日常生活的基本空间载体,其平面图更是在建筑设计早期发挥着核心作用。 然而,传统平面图设计流程高度依赖建筑师个人经验,存在效率低、反馈慢、缺乏智能辅助等问题。

字节开源图像生成“六边形战士”,一个模型搞定人物/主体/风格保持
图像生成中的多指标一致性问题,被字节团队解决了! 字节UXO团队设计并开源了统一框架USO,让看上去不关联的任务相互促进,实现风格迁移和主体保持单任务和组合任务的SOTA。 USO通过单一框架能统一之前那些看似孤立的任务包括主体、身份保持和风格化编辑,参考图风格迁移,同时保持主体和风格参考,甚至更抽象复杂的多风格迁移,是实打实的六边形战士。

谷歌「最强图像模型」横扫一切!3毛钱P图打懵OpenAI,PS要不存在了
刚刚,谷歌正式发布最先进的图像模型,Gemini 2.5 Flash Image。 如果说它的另一个名字,nano-banana,你就一定知道了! 「最强图像模型」这个称号可以说是被全球网友亲自认定。

一张图0.1秒生成上半身3D化身!清华IDEA新框架入选ICCV 2025
一张图就能创建上半身动作视频,方法还入选了ICCV 2025! 来自清华大学、IDEA(粤港澳大湾区数字经济研究院)的研究人员提出新框架GUAVA,不需要多视角视频、不需要针对不同个体单人训练,仅需0.1秒就能从单图创建一个上半身3D化身。 通常来说,创建逼真且富有表现力的上半身人体化身(如包含细致面部表情和丰富手势),在电影、游戏和虚拟会议等领域具有重要价值。

从捍卫者到引路人,上交&上海AI Lab提出LEGION:不仅是AI图像伪造克星,还能反哺生成模型进化?
本文由上海交通大学,上海人工智能实验室、北京航空航天大学、中山大学和商汤科技联合完成。 主要作者包括上海交通大学与上海人工智能实验室联培博士生康恒锐、温子辰,上海人工智能实验室实习生文思为等。 通讯作者为中山大学副教授李唯嘉和上海人工智能实验室青年科学家何聪辉。

实测谷歌AI故事书,我实现漫画和绘本自由了
谷歌Gemini又双叒叕出新工具了,只需要30s左右,就能让AI帮你生成一篇10页的故事书,还是免费的。 并且支持中文,生成的内容也相当有趣。 这一次带来的是能够一键生成故事书的StoryBook:只需描述你想要的故事,如果喜欢的话还可以添加文件和图片,Gemni将会创造一本独特的10页故事书。

联合理解生成的关键拼图?腾讯发布X-Omini:强化学习让离散自回归生成方法重焕生机,轻松渲染长文本图像
本论文作者团队来自腾讯混元X组,共同一作为耿子钢和王逸冰,项目Lead为张小松,通讯作者为腾讯混元团队杰出科学家胡瀚,Swin Transformer作者。 在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。 大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。

谷歌深夜放出「创世引擎」Genie 3!一句话秒生宇宙,终极模拟器觉醒
全球最强「世界AI模拟器」今夜诞生! 刚刚,谷歌DeepMind祭出新一代通用世界模型——Genie 3,能模拟出史无前例的丰富交互环境。 一句话,Genie 3即可生成一个动态世界。

深入探索 GPT-4o:图像生成的多面手
大家好,我是肆〇柒。 图像生成技术正以前所未有的速度演进,从早期的 GANs(生成对抗网络)到如今的扩散模型,每一次技术迭代都为视觉创作领域注入了新的活力。 而近期,GPT-4o 发布的生图能力,真是火出圈,甚至带火了吉卜力风格。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉