数据

DPG-Bench榜首!智谱开源文生图模型CogView4:支持中英文输入和生成,免费商用授权!
在图像生成技术的浪潮中,智谱开源再次引领潮流,推出了全新的文生图模型——CogView4。 这款模型不仅支持中英双语提示词输入,更擅长理解和遵循中文指令,让创意表达无界限。 尤为值得一提的是,CogView4开创了先河,成为首个能在画面中直接生成汉字的开源文生图模型,让文字与图像的融合更加自然流畅。

哥大本科生靠AI横扫硅谷大厂offer,学校震怒!预言码农两年内淘汰准备退学
硅谷大型科技公司FAANG的面试,对不少人来说都是一场噩梦。 结果,哥大的一位大二学生Roy Lee,居然利用AI,顺利斩获了亚马逊、Meta和TikTok的offer,获得了直通梦中情厂的实习机会! 这个消息一出,震惊了不少人。

一次搭建完胜1亿次编码,MCP硅谷疯传!Anthropic协议解锁智能体「万能手」
上一周,智能体迎来里程碑式的一周。 从Manus及其开源复现,到Opera的浏览器操作AI智能体、AI工作伴侣Archer,再到多种个人项目,将Agent推向热议风口。 在处理动辄需要十几甚至几十分钟的复杂任务时,涉及到3个核心能力:规划工具使用记忆其中,第二趴是让智能体「动起来」的关键,真正与现实世界进行交互。

1.5B硬刚GPT-4o,CMU祭出LCPO提示可控思考!每token性能较S1暴涨2倍
一个只有15亿参数的小模型,竟然能在相同token预算下挑战GPT-4o的性能! 最近,CMU团队推出了「长度控制策略优化」(LCPO),它让AI的推理过程不再是「一刀切」,而是像个聪明管家,能根据任务需求灵活调整「思考」长度。 无论是啃下复杂的数学难题,还是快速解答简单问题,这个名叫L1的模型都游刃有余。

Ilya错了?Scaling另有他用,ViT大佬力挺谷歌1000亿数据新发现
预训练Scaling Law到尽头了? ViT大佬翟晓华(Xiaohua Zhai)并不这样认为,至少在多模态模型上并非如此。 他公布了最新的关于多模态Scaling的最新见解,而训练数据达到了1000亿的规模!

DeepSeek占比升至9.6%,稳居全球第二!「全球生成式AI行业趋势」发布
近日,SimilarWeb发布了最新的「全球生成式AI行业趋势」报告。 报告中详细分析了截至2月28日,全球生成式AI工具在各个领域的趋势和表现。 报告链接:,AI工具在过去12周的增速约为20%,其中代码自动补全与DevOps增长高达72%。

Anthropic预测26年AI智力堪比诺奖得主!美国AI行动计划发布在即,五角大楼紧急布局
截止到2026-2027年,AI智力水平将达到诺奖级得主。 Anthropic最新长文,再次宣告,人类离超级智能体近在咫尺。 报告地址:,CEO Dario Amodei在「Machines of Loving Grace」一文中,曾大胆预测——2026年底-2027年初,人类将见证强大AI系统诞生。

智源BGE-VL拍照提问即可精准搜,1/70数据击穿多模态检索天花板!
BGE系列模型自发布以来广受社区好评。 近日,智源研究院联合多所高校开发了多模态向量模型BGE-VL,进一步扩充了原有生态体系。 BGE-VL在图文检索、组合图像检索等主要多模态检索任务中均取得了最佳效果。

全球首款通用AI助手发布 中国AI产品Manus一夜刷屏
近日,全球首款通用Agent(自主智能体)产品Manus正式开启了部分内测,这标志着AI自主智能领域迈出了关键性的一步。 Manus以其强大的独立思考、规划并执行复杂任务的能力,直接交付完整成果,展现了前所未有的通用性和执行能力。 与现有的AI助手相比,Manus不仅具备多任务操作能力,如Claude的Computer use等,更能在多个领域实现更高的执行质量。
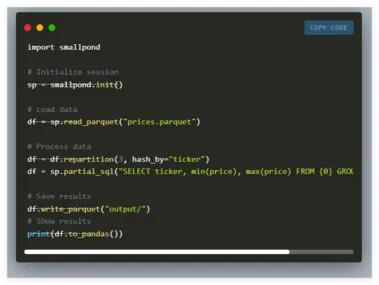
DeepSeek AI推出Smallpond:基于DuckDB与3FS的轻量级数据处理框架
随着数据集的不断扩大和分布式处理的复杂性加剧,现代数据工作流面临越来越大的挑战。 许多组织发现,传统的数据处理系统在处理时间、内存限制和分布式任务管理方面存在显著的短板。 在这样的背景下,数据科学家和工程师往往需要花费大量时间在系统维护上,而非从数据中提取有价值的见解。

重磅!阿里深夜推出全新推理模型,仅1/20参数媲美DeepSeek R1
就在刚刚,阿里Qwen 团队 正式发布了他们最新的研究成果 —— QwQ-32B 大语言模型! 这款模型不仅名字萌萌哒 (QwQ),实力更是不容小觑! 😎相信关注大模型领域的朋友们都知道,模型参数量的大小往往与性能成正比。

MegaSynth:用70万合成数据突破3D场景重建瓶颈,PSNR提升1.8dB!
一眼概览MegaSynth 提出了一种基于非语义合成数据的大规模 3D 场景重建方法,生成 70 万个合成场景数据集,训练大型重建模型(LRMs),相比使用真实数据训练的模型,PSNR 提升 1.2~1.8 dB,显著增强 3D 场景重建的广覆盖能力。 核心问题当前 3D 场景重建方法受限于:数据规模受限:现有真实数据集 DL3DV 仅 10K 场景,远小于物体级数据集(如 Objaverse 80 万个实例)。 数据分布不理想:现有数据集多为人工采集,难以确保场景多样性,摄像机运动范围受限,且可能包含噪声和不精确标注。

GPT-4.5登顶6小时即失守!Grok-3上演1分逆袭
基础模型竞争又紧张刺激起来了! GPT-4.5刚登顶竞技场且全任务分类第一名,6小时后总榜就被马斯克的新版Grok-3反超。 两者都是获得3000 票数,总分1412:1411只差一分。

DeepSeek全面开源V3/R1推理系统!成本利润率高达545%
就在刚刚,当大家以为开源周已经结束的时候,真「Open AI」DeepSeek带来了压轴大戏——DeepSeek-V3/R1推理系统,全面揭秘! 吞吐量和延迟优化:跨节点高效并行(EP)驱动的批处理扩展计算与通信并行处理智能负载均衡在线服务性能数据:每个H800节点每秒处理73,700/14,800输入/输出token成本利润率高达545�epSeek表示,希望本周分享的技术见解能为开源社区带来价值,共同推进通用人工智能的发展目标。 看到这里,网友都惊了!

Nature独家爆料:全球机构撤稿率大排行,医学领域成重灾区
撤稿,是对科研人员诚信的巨大打击,不仅是一篇论文,此前的研究成果都可能遭到同行质疑。 中国在保障学术道德诚信方面的力度非常大,一经发现,即全国通报批评,取消申报课题资格5年,基本就断送了自己的学术生涯。 通报链接::,仍然有大量的科研人员为了一己私利,在论文撰写中捏造数据、伪造实验结果,甚至雇佣写手,从论文工厂中购买。

大模型训练或无需“纯净数据”!北大团队新研究:随机噪声影响有限,新方法让模型更抗噪
传统的大语言模型训练需要依赖”纯净数据”——那些经过仔细筛选、符合标准语法且逻辑严密的文本。 但如果这种严格的数据过滤,并不像我们想象中那般重要呢? 这就像教孩子学语言:传统观点认为他们应该只听语法完美的标准发音。

不要自回归!扩散模型作者创业,首个商业级扩散LLM来了,编程秒出结果
当前的 AI 领域,可以说 Transformer 与扩散模型是最热门的模型架构。 也因此,有不少研究团队都在尝试将这两种架构融合到一起,以两者之长探索新一代的模型范式,比如我们之前报道过的 LLaDA。 不过,之前这些成果都还只是研究探索,并未真正实现大规模应用。

微软Phi-4家族新增两位成员,5.6B多模态单任务超GPT-4o,3.8B小模型媲美千问7B
动辄百亿、千亿参数的大模型正在一路狂奔,但「小而美」的模型也在闪闪发光。 2024 年底,微软正式发布了 Phi-4—— 在同类产品中表现卓越的小型语言模型(SLM)。 仅用了 40% 合成数据,140 亿参数的 Phi-4 就在数学性能上击败了 GPT-4o。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉