视觉

英伟达港大联手革新视觉注意力机制!GSPN高分辨率生成加速超84倍
视觉注意力机制,又有新突破,来自香港大学和英伟达。 Transformer的自注意力在NLP和计算机视觉领域表现出色——它能捕捉远距离依赖,构建深度上下文。 然而,面对高分辨率图像时,传统自注意力有两个大难题:计算量巨大:O(N²) 的复杂度让处理长上下文变得非常耗时。

李飞飞自曝详细创业经历:五年前因眼睛受伤,坚定要做世界模型
因为眼睛受伤暂时失去立体视觉,李飞飞更加坚定了做世界模型的决心。 在a16z的最新播客节目中,“AI教母”李飞飞讲述了五年前因为一次角膜损伤暂时失去立体视觉的经历:尽管凭借多年经验能想象出三维世界,但一只眼睛看东西时,我开始害怕开车。 但作为一名科学家,她也把这次经历当成一次宝贵的“实验”机会。

2025年,Mamba“联姻”Transformer,打造史上最强视觉骨干网络!
一眼概览MambaVision 提出一种混合 Mamba-Transformer 视觉骨干网络,首次将状态空间模型(SSM)与自注意力机制融合,显著提升图像分类、检测和分割任务的准确率与效率,达到新一代性能-速度最优前沿。 核心问题虽然 Mamba 模型在语言任务中展现了优秀的长序列建模能力,但其自回归结构难以高效捕捉图像中的全局空间依赖,限制了在计算机视觉中的表现。 如何在保持高吞吐和低复杂度的前提下建模图像中的长程依赖,是本研究要解决的核心问题。

视觉感知驱动的多模态推理,阿里通义提出VRAG,定义下一代检索增强生成
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。 然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。 一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。

ETT:打破原生多模态学习视觉瓶颈,重塑视觉tokenizer优化范式
本文由北京智源研究院多模态大模型研究中心(团队负责人王鑫龙,团队代表作 EMU 系列、EVA 系列、Painter & SegGPT)、中科院自动化所和大连理工大学联合完成。 在多模态学习蓬勃发展的当下,视觉 tokenizer 作为连接视觉信息与下游任务的关键桥梁,其性能优劣直接决定了多模态模型的表现。 然而,传统的视觉 tokenization 方法存在一个致命缺陷:视觉 tokenizer 的优化与下游任务的训练是相互割裂的。

One RL to See Them All?一个强化学习统一视觉-语言任务!
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。 然而,RL 在推理任务之外的应用,尤其是在目标检测和目标定位等感知密集型任务中的应用,仍有待深入探索。 近日,国内初创公司 MiniMax 提出了 V-Triune,一个视觉三重统一强化学习系统,它能使 VLM 在单一的训练流程中同时学习视觉推理和感知任务。

ICML 2025 Spotlight | 多模态大模型暴露短板?EMMA基准深度揭秘多模态推理能力
「三个点电荷 Q、-2Q 和 3Q 等距放置,哪个向量最能描述作用在 Q 电荷上的净电力方向? 」在解这道题时,我们可以通过绘制受力分析草图轻松解决。 但即使是先进的多模态大语言模型,如 GPT-4o,也可能在理解「同性相斥」的基本物理原则时,错误地判断斥力的方向(例如,错误地将 3Q 对 Q 的斥力方向判断为右下方而非正确的左上方)。

腾讯宣布混元图像2.0将于5月16日全新发布
今日, 腾讯混元大模型团队今日正式宣布,其新一代多模态图像生成工具——混元图像2.0将于5月16日上午11时通过全球直播发布。 这是继去年混元大模型升级后,腾讯在AI视觉领域的又一次重大突破,以“更智能、更开放、更中国”为核心理念,赋能创作者与企业用户迈向AI驱动的视觉生产新阶段。

仅20B参数!字节推出Seed1.5-VL多模态模型,实现38项SOTA
在上海举办的火山引擎 FORCE LINK AI 创新巡展上,字节跳动正式发布了最新的视觉 - 语言多模态模型 ——Seed1.5-VL。 该模型凭借其出色的通用多模态理解和推理能力,成为此次活动的焦点,吸引了众多业界专家和开发者的关注。 Seed1.5-VL 的显著特点是其增强的多模态理解与推理能力。

腾讯混元携手科研机构推出首个多模态统一CoT奖励模型并开源
近日,腾讯混元在与上海 AI Lab、复旦大学及上海创智学院的合作下,正式推出了全新研究成果 —— 统一多模态奖励模型(Unified Reward-Think),并宣布全面开源。 这一创新模型不仅具备了强大的长链推理能力,还首次实现了在视觉任务中 “思考” 的能力,使得奖励模型能够更准确地评估复杂的视觉生成与理解任务。 统一多模态奖励模型的推出,标志着奖励模型在各类视觉任务中的应用达到了新的高度。
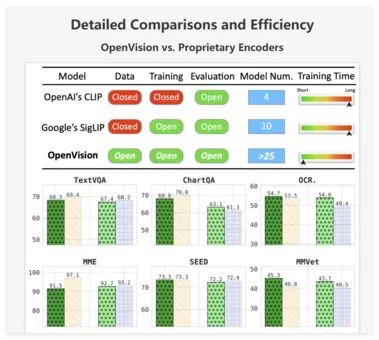
新一代开源视觉编码器 OpenVision 发布:超越 CLIP 与 SigLIP 的强大选择
加州大学圣克鲁兹分校近日宣布推出 OpenVision,这是一个全新的视觉编码器系列,旨在为 OpenAI 的 CLIP 和谷歌的 SigLIP 等模型提供替代方案。 OpenVision 的发布为开发者和企业带来了更多灵活性和选择,使得图像处理和理解变得更加高效。 什么是视觉编码器?视觉编码器是一种人工智能模型,它将视觉材料(通常是上传的静态图像)转化为可被其他非视觉模型(如大型语言模型)理解的数值数据。

Pinterest 凭借 AI 驱动个性化推荐实现 16% 收入增长
在刚刚过去的第一季度,Pinterest 发布了强劲的财报,收入达到了8.55亿美元,同比增长了16%。 与此同时,活跃用户数也稳步增长,达到5.7亿,较去年同期增加了10%。 Pinterest 首席执行官比尔・瑞迪在电话会议上表示,这一增长的主要原因在于公司对人工智能(AI)的持续投资,尤其是在吸引 Z 世代用户方面取得了显著成效。

字体控狂喜!Liblib AI 黑科技 RepText:无需理解文字,AI就能 1:1 复刻多国语言视觉效果
Liblib AI提出了 RepText,可以使预训练的单语文本转图像生成模型能够以用户指定的字体准确渲染,或者更准确地说,复制多语种视觉文本,而无需真正理解这些字体。 这样不管是中文、日文、韩文还是其他语言都可以精准的生成! 从某种意义上说也算是打破了AI图文生成语言的壁垒!

字节跳动携手港大与华中科技大学推出UniTok,革新视觉分词技术
近日,字节跳动联合香港大学和华中科技大学共同推出了全新的视觉分词器 UniTok。 这款工具不仅能在视觉生成和理解任务中发挥作用,还在技术上进行了重要创新,解决了传统分词器在细节捕捉与语义理解之间的矛盾。 UniTok 采用了多码本量化技术,能够将图像特征分割成多个小块,并用独立的子码本进行量化。

Gemini 2.5 Pro登顶三冠王!AI最强编程屠榜,全面碾压Claude 3.7
AI编程王座,一夜易主。 昨晚,谷歌放出全新升级的Gemini 2.5 Pro Preview(I/O版),一举拿下三连冠,登顶LMeana。 Image图片它成为首个横扫文本、视觉、WebDev Arena基准的SOTA模型,编码性能碾压Claude 3.7 Sonnet。

用多模态LLM超越YOLOv3!强化学习突破多模态感知极限|开源
超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦! 华中科技大学、北京邮电大学等多所高校研究团队共同推出的Perception-R1(PR1),在视觉推理中最基础的感知层面,探究rule-based RL能给模型感知pattern带来的增益。 PR1重点关注当下主流的纯视觉(计数,通用目标检测)以及视觉语言(grounding,OCR)任务,实验结果展现出在模型感知策略上的巨大潜力。

AAAI2025 | ICLR 2025爆款!CHiP创新引入视觉偏好,幻觉率腰斩
一眼概览CHiP 提出了一种跨模态分层偏好优化方法,通过视觉与文本偏好双重引导,显著提升多模态大模型(MLLMs)在幻觉检测任务中的表现,最高减少55.5%的幻觉率。 核心问题多模态大模型(如GPT-4V、LLaVA)虽具强大能力,但常产生“幻觉”——即图文语义不一致、生成不符合图像内容的描述。 现有DPO方法仅基于文本偏好,难以有效对齐图像和文本的表示,也无法细粒度定位幻觉段落,限制了模型可信度与实用性。

OpenAI没说的秘密,Meta全揭了?华人一作GPT-4o同款技术,爆打扩散王者
GPT-4o生成的第一视角机器人打字图这次,来自Meta等机构的研究者,发现在多模态大语言模型(MLLMs)中,视觉词表存在维度冗余:视觉编码器输出的低维视觉特征,被直接映射到高维语言词表空间。 研究者提出了一种简单而新颖的Transformer图像token压缩方法:Token-Shuffle。 他们设计了两项关键操作:token混洗(token-shuffle):沿通道维度合并空间局部token,用来减少输入token数;token解混(token-unshuffle):在Transformer块后解构推断token,用来恢复输出空间结构。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉