1. 一眼概览
MambaVision 提出一种混合 Mamba-Transformer 视觉骨干网络,首次将状态空间模型(SSM)与自注意力机制融合,显著提升图像分类、检测和分割任务的准确率与效率,达到新一代性能-速度最优前沿。
2. 核心问题
虽然 Mamba 模型在语言任务中展现了优秀的长序列建模能力,但其自回归结构难以高效捕捉图像中的全局空间依赖,限制了在计算机视觉中的表现。如何在保持高吞吐和低复杂度的前提下建模图像中的长程依赖,是本研究要解决的核心问题。
3. 技术亮点
- 视觉友好的 Mamba 重设计:引入对称非 SSM 分支,替换因果卷积,有效增强对空间信息的建模能力;
- Mamba + Transformer 的混合架构:在模型末端引入多层自注意力块,显著提升对长程依赖的捕捉能力;
- SOTA 性能-效率平衡:在 ImageNet-1K 上实现新的准确率-吞吐率最优曲线,并在下游任务上超越主流主干模型。
4. 方法框架
 图片
图片
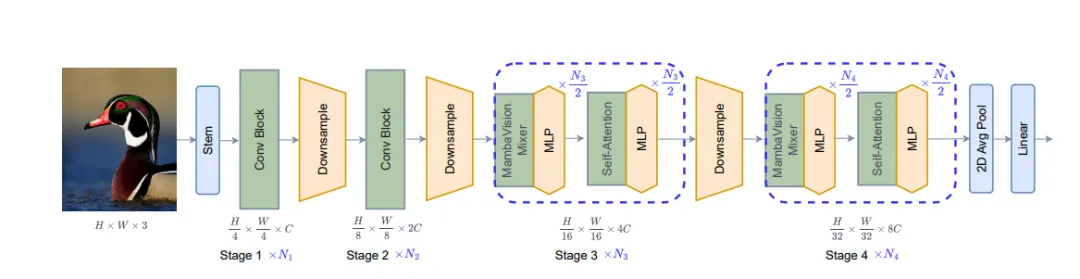
MambaVision 使用四阶段层次化架构:
• Stage 1–2:采用 CNN 残差块快速提取高分辨率特征;
• Stage 3–4:前半使用 MambaVision Mixer,后半加入 Transformer 自注意力模块,结合局部与全局建模能力;
• Mixer 模块:SSM 分支建模序列依赖,新增对称卷积分支增强空间特征,最终拼接融合;
• 下采样和线性投影贯穿各阶段,形成统一的视觉表示。
5. 实验结果速览
📌 图像分类(ImageNet-1K):
• MambaVision-B 实现 84.2% Top-1 准确率,超过 ConvNeXt-B(83.8%)和 Swin-B(83.5%);
• 同时吞吐率远高于 VMamba 和 Swin 系列;
• GFLOPs 显著减少(如比 MaxViT-B 少 56%)。
📌 目标检测与实例分割(MS COCO):
• MambaVision-T/S/B 在 Mask-RCNN 和 Cascade-RCNN 中整体超过 Swin 和 ConvNeXt 同级模型;
• 如 MambaVision-B 达到 52.8 box AP / 45.7 mask AP。
📌 语义分割(ADE20K):
• MambaVision-B 实现 49.1% mIoU,优于 Swin-B(48.1%)和 Focal-B(49.0%)等。
6. 实用价值与应用
MambaVision 为部署在算力受限设备上的高性能视觉任务提供新方案,尤其适用于:
• 实时图像分类与检测;
• 高分辨率语义分割(如城市交通感知);
• 视觉感知系统中的轻量级嵌入式应用。
其优异的性能-效率权衡使其成为 Transformer 替代方案的新候选。
7. 开放问题
• 如果在更复杂的跨尺度视觉任务(如多模态融合)中,MambaVision 的表现是否仍具优势?
• 是否能将 MambaVision 的混合模式推广至视频理解或时序图像分析中?
• MambaVision 能否进一步压缩为移动端模型以适应边缘计算?


