视觉语言模型

英伟达发布首个自动驾驶推理模型,押注下一代 AI 大脑
芯片巨头英伟达周一在加州圣地亚哥举行的 NeurIPS 人工智能大会上宣布了新的基础设施和人工智能模型,此举旨在加速构建物理人工智能(Physical AI)的基础技术,该领域包括能够感知现实世界并与之互动的机器人和自动驾驶汽车。 首个自动驾驶推理视觉语言模型亮相英伟达发布了 Alpamayo-R1,这是一款专用于自动驾驶研究的开放式推理视觉语言模型(VLAM)。 该公司声称,这是首个专注于自动驾驶的视觉语言动作模型。

“我没错!”GPT-4o嘴硬翻车,AI在黑天鹅事件面前集体宕机
来自哥伦比亚大学、Vector人工智能研究所以及南洋理工大学的一个联合研究团队发现:人工智能模型在处理意外事件时的推理能力存在严重缺陷。 即便是如GPT-4o和Gemini 1.5 Pro这样的顶尖视觉语言模型(VLM),其表现也远逊于人类,差距最高可达32%。 论文地址:《黑天鹅》的研究指出,当前主流的AI评估方式普遍存在一个根本性问题:大多数基准测试围绕“常规模式”构建,也就是说,它们聚焦于可预测、规律清晰的视觉场景。

9B“小”模型干了票“大”的:性能超8倍参数模型,拿下23项SOTA | 智谱开源
如果一个视觉语言模型(VLM)只会“看”,那真的是已经不够看的了。 因为现在真实世界的任务简直不要太复杂,要想让AI干点实事儿,光有多模态还不够,必须还得有深度思考的强推理能力。 而就在刚刚,智谱发布并开源了一个仅9B大小的模型——GLM-4.1V-9B-Thinking,在28项评测中一举拿下23个SOTA!

AI为何读不懂钟表?模拟时钟暴露的认知短板与AI进化隐忧
译者 | 朱先忠审校 | 重楼中国和西班牙研究人员发表的一篇新论文发现,即使是像GPT-4.1这样的先进多模态人工智能模型,也难以从模拟时钟图像中识别时间。 时钟中细微的视觉变化都可能导致严重的解读错误,而微调也只对熟悉的示例有效。 这一结果引发了人们对这些模型在现实世界任务中处理不熟悉图像时的可靠性的担忧。

kimi开源视觉语言模型 Kimi-VL 与 Kimi-VL-Thinking,多项基准超越 GPT-4o
备受瞩目的国内人工智能公司 Moonshot AI (月之暗面) 近日宣布,正式开源发布了两款全新的视觉语言模型——Kimi-VL 与 Kimi-VL-Thinking。 这两款模型以其轻量级的架构和卓越的多模态理解与推理能力,在多个关键基准测试中超越了包括 GPT-4o 在内的众多大型模型,引发行业广泛关注。 轻巧身躯,蕴藏澎湃动力与动辄拥有数百亿甚至千亿参数的主流大模型不同,Kimi-VL 和 Kimi-VL-Thinking 均采用了 MoE(Mixture-of-Experts,混合专家)架构,其激活参数仅约 30亿。

模态编码器 | ALIGN,通过大规模嘈杂数据集训练的视觉语言模型
简单看一下Google早期的一篇工作ALIGN,发表在2021 ICML上。 研究动机:传统的视觉语言表示学习通常在手动标注的大规模数据集上进行训练,需要大量的预先处理和成本。 ALIGN利用网络上摘取的HTML页面和alt-text标签,构建了一个18亿对图像-文本的嘈杂数据集,从而在不需要昂贵的数据过滤的情况下,实现高效的学习。
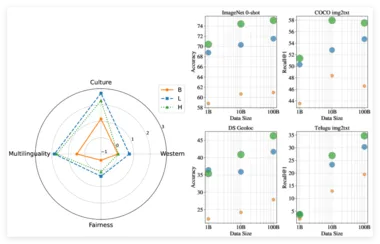
谷歌 DeepMind 推出千亿级视觉语言数据集 WebLI-100B
谷歌 DeepMind 团队正式推出了 WebLI-100B 数据集,这是一个包含1000亿个图像 - 文本对的庞大数据集,旨在增强人工智能视觉语言模型的文化多样性和多语言性。 通过这一数据集,研究人员希望改善视觉语言模型在不同文化和语言环境下的表现,同时减少各个子组之间的性能差异,从而提升人工智能的包容性。 视觉语言模型(VLMs)依赖于大量数据集来学习如何连接图像与文本,从而执行如图像字幕生成和视觉问答等任务。

IBM发布视觉语言模型Granite-Vision-3.1-2B,轻松解析复杂文档
随着人工智能技术的不断发展,视觉与文本数据的融合成为了一项复杂的挑战。 传统的模型往往难以准确解析表格、图表、信息图和图示等结构化视觉文档,这一限制影响了自动内容提取和理解能力,进而影响了数据分析、信息检索和决策等应用。 面对这一需求,IBM 近期发布了 Granite-Vision-3.1-2B,一款专为文档理解设计的小型视觉语言模型。

VLA 技术引领智驾竞赛,英伟达助力黑马企业迅速抢占市场份额
在智能驾驶行业,2025年被视为 “VLA 上车元年”,这标志着一种全新的技术范式正在崭露头角。 VLA,即视觉语言动作模型(Vision-Language-Action Model),最初由 DeepMind 于2023年提出,旨在提升机器人对环境的理解和反应能力。 近年来,这一技术在自动驾驶领域受到了极大的关注。
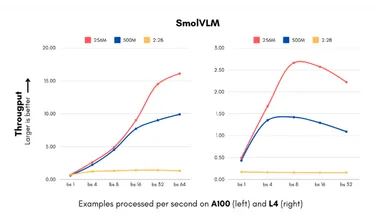
300倍体积缩减!Hugging Face推SmolVLM模型:小巧智能,手机也能跑AI
Hugging Face 推出了一款令人瞩目的 AI 模型 ——SmolVLM。 这款视觉语言模型的体积小到可以在手机等小型设备上运行,且性能超越了那些需要大型数据中心支持的前辈模型。 SmolVLM-256M 模型的 GPU 内存需求不足1GB,性能却超过了其前代 Idefics80B 模型,这一后者的规模是其300倍,标志着实用 AI 部署的一个重大进展。

使用Pytorch构建视觉语言模型(VLM)
视觉语言模型(Vision Language Model,VLM)正在改变计算机对视觉和文本信息的理解与交互方式。 本文将介绍 VLM 的核心组件和实现细节,可以让你全面掌握这项前沿技术。 我们的目标是理解并实现能够通过指令微调来执行有用任务的视觉语言模型。

让视觉语言模型搞空间推理,谷歌又整新活了
视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。视觉语言模型 (VLM) 已经在广泛的任务上取得了显著进展,包括图像描述、视觉问答 (VQA)、具身规划、动作识别等等。然而大多数视觉语言模型在空间推理方面仍然存在一些困难,比如需要理解目标在三维空间中的位置或空间关系的任务。关于这一问题,研究者们常常从「人类」身上获得启发:通过具身体验和进化发展,人类拥有固有的空间推理技能,可以毫不费力地确定空间关系,比如目标相对位置或估算距离和大小,而
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉