
来自哥伦比亚大学、Vector人工智能研究所以及南洋理工大学的一个联合研究团队发现:人工智能模型在处理意外事件时的推理能力存在严重缺陷。
即便是如GPT-4o和Gemini 1.5 Pro这样的顶尖视觉语言模型(VLM),其表现也远逊于人类,差距最高可达32%。

论文地址:https://arxiv.org/pdf/2412.05725
这篇名为《黑天鹅》的研究指出,当前主流的AI评估方式普遍存在一个根本性问题:大多数基准测试围绕“常规模式”构建,也就是说,它们聚焦于可预测、规律清晰的视觉场景。
但现实世界不按套路出牌。意外、突变和违反常识的“黑天鹅事件”无处不在。而人类之所以能处理这些状况,依靠的是两种核心推理能力。
第一种是溯因推理(abductive reasoning),即从有限的观察中推断出最可能的解释。 例如,观察到路口有两辆撞坏的汽车,人们会推测是一名司机闯了红灯。

第二种是可废止推理(defeasible reasoning),即在新证据出现时修正最初的结论。 比如,当发现路口的交通信号灯发生故障时,人们会放弃“司机闯红灯”的假设,转而认为是信号灯的问题。
如果AI要成为自动驾驶汽车等领域的可靠决策者,这两种推理能力至关重要。
“黑天鹅套件”:一个专为意外设计的考场

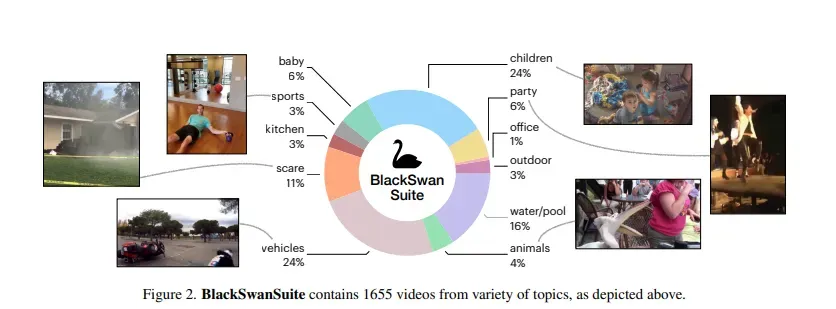
为了准确评估AI在意外情况下的推理能力,研究团队构建了一个全新的基准测试,名为“BlackSwanSuite”(黑天鹅套件)。
这个基准测试包含1655个视频,内容涵盖了各种打破常规的真实场景,例如这些视频涵盖了交通事故、儿童失误、泳池滑倒等。
研究者将每个视频精心划分为三个部分:事发前 (Vpre)、事发时 (Vmain)和事发后 (Vpost)。
这种结构化的处理方式,为设计针对性的推理任务奠定了基础。 基于此,团队设计了三大核心任务,共计超过15000个问题。
第一个任务是“预测者”(Forecaster),模型仅观看视频的开头,然后被要求预测接下来会发生什么。
第二个任务是“侦探”(Detective),模型会看到事件的开头和结尾,但中间的关键部分被隐藏,模型需要推断出中间发生了什么。 这项任务直接考验模型的溯因推理能力。
第三个任务是“报告者”(Reporter),模型可以观看完整的视频,然后需要描述整个事件的来龙去脉。 同时,模型还需要重新评估之前基于不完整信息做出的判断是否依然成立。这直接测试了模型的可废止推理能力。
严峻的现实:顶尖模型的显著短板
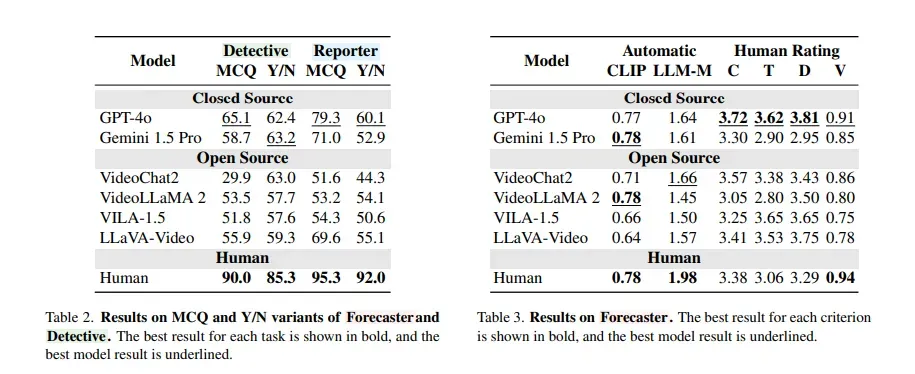
所有顶尖的AI模型,包括GPT-4o、Gemini 1.5 Pro,以及多种开源系统(如LLaVA-Video、VILA、VideoLLaMA 2),在三类任务中全面落后于人类。
在多项选择题上,最好的模型落后人类多达25%。 在是非判断题上,这个差距进一步扩大到了32%。
具体来看,在考验溯因推理的“侦探”任务中,表现最好的GPT-4o,其准确率也比人类低了24.9%。
而在考验可废止推理的“报告者”任务中,GPT-4o与人类的差距更是达到了惊人的32%。
32个百分点的差距说明一个问题:AI不仅“看错”,更“改不了”。
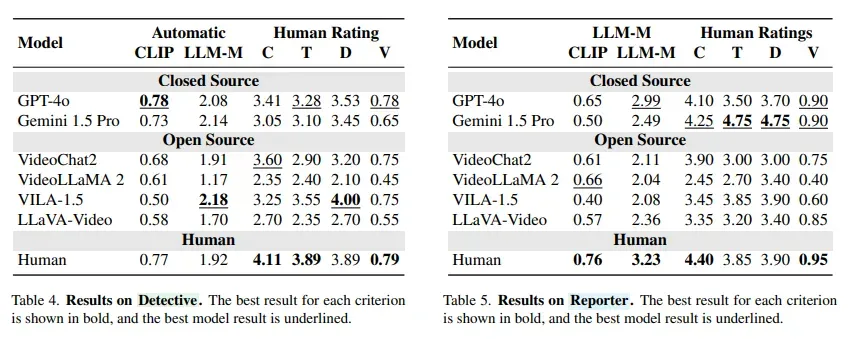
模型往往会在最初判断后“锁定思路”,拒绝基于新证据进行推理更新。这在自动驾驶等领域,可能带来致命后果。
例如,论文中展示:垃圾车应该是“装垃圾”的,但当视频中垃圾车却“掉下了一棵树”,AI模型当场宕机。
再例如:一段视频中,一名男子手持枕头在圣诞树旁挥舞。
GPT-4o判断他想攻击身边的人。但实际情况是:枕头碰到了圣诞树,装饰物从树上掉落,砸中了旁边的女性。
视频结尾已清晰展示全过程,但GPT-4o依然坚持“男子攻击他人”的原始判断。
即便事实已推翻原猜测,模型也不做修正。这种“第一印象即终审判”的僵化思维,成了AI在现实世界中的最大隐患。
因为它找不到这个“异常行为”的参考模式。根源在于,AI模型依赖的是海量训练样本的“统计模式”。
它们在训练中学习的是“什么事发生过很多次”,而不是“这事的因果关系是什么”。
所以,只要场景偏离了“常规轨迹”,它们就无法处理。为了进一步探究问题的根源,研究团队进行了一项关键实验。
他们直接向AI模型提供由人类撰写的、对视频内容的文字描述,从而绕过模型自身的视觉感知环节。
结果显示,在获得了人类级别的感知和理解输入后,模型的推理准确率提升了高达10%。
这一发现表明,当前AI的核心短板不仅在于高级推理,更在于基础的感知和理解能力。
注:头图AI生成


