
2023年成立的中国AI初创公司月之暗面,刚刚发布了其最新重量级产品Kimi-K2。
这是一款参数规模高达一万亿的开源大模型,以挑战GPT-4.1和Claude Sonnet 4为目标。
Kimi-K2没有配备专门的“推理模块”,却依然在多个关键领域打破性能壁垒,这一策略让人想起早前Deepseek的发布。
该模型采用“专家混合”(Mixture-of-Experts)架构,每次推理时动态激活320亿参数。
Kimi-K2的权重完全开放,允许研究者和开发者进行自定义微调与本地部署。
击穿基准:没有“推理模块”的强者
Kimi-K2在多个通用语言模型评测中与闭源顶级模型并肩而立,甚至在编程与数学领域表现出压倒性优势。
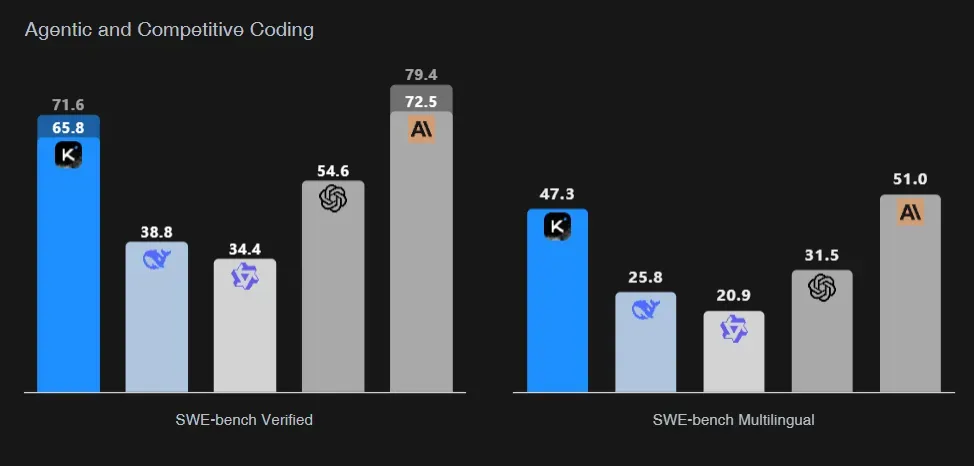
在被广泛采用的SWE-bench Verified测试中,Kimi-K2-Instruct在“Agent模式”下获得65.8%的得分,仅次于Claude Sonnet 4,远超GPT-4.1的54.6%。
这个测试评估的是模型在真实开源项目中识别与修复代码错误的能力,难度极高。
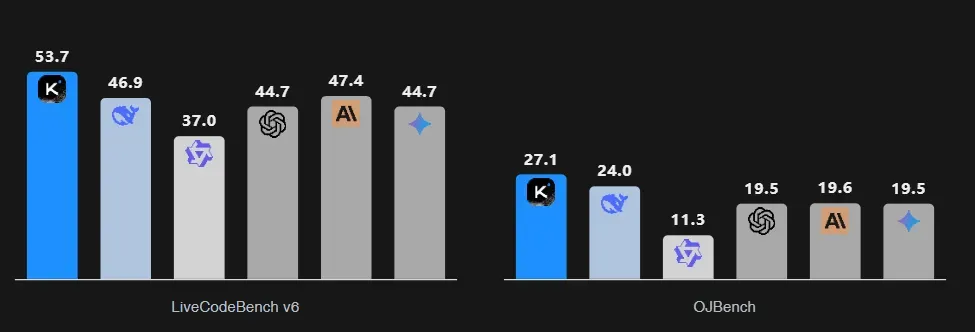
在LiveCodeBench测试中,Kimi-K2以53.7%的得分领跑所有模型,OJBench的得分也达到了27.1%。
这两个评测分别模拟互动式编程任务与传统竞赛题,进一步证明了Kimi-K2在软件工程场景中的适配能力。
更重要的是,官方强调“non-thinking”,意味着在无需显式推理的基础上,完成这些高复杂度任务。这对“推理模块”至上的传统语言模型设计提出了深刻反思。
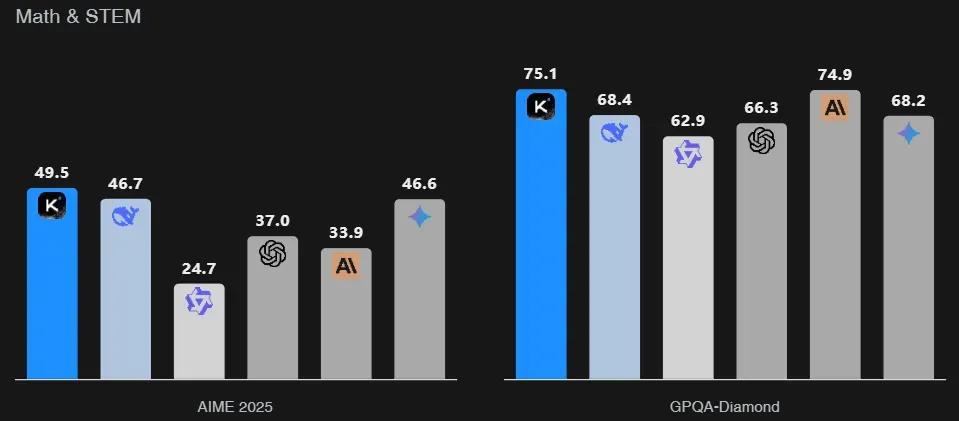
在数学和科学领域,Kimi-K2在AIME、GPQA-Diamond和MATH-500等测评中稳定优于主要对手,展示出深度数学建模的潜力。
在多语言测试如MMLU-Pro中,它同样进入领先梯队,兼具多语言与跨学科能力。
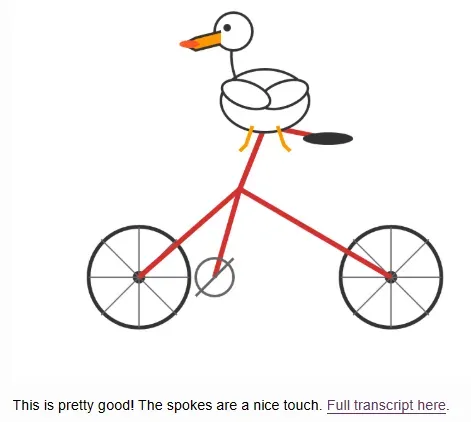
值得一提的是,在一项非正式评测中,Kimi-K2能完整生成骑自行车的鹈鹕SVG图像,而其他主流模型常常只画出模糊形状。
图像生成的正确性在众多模型中极为罕见,这也印证了Kimi-K2的空间理解与复杂结构表达能力。
月之暗面强调,Kimi-K2专为Agent工作流而非日常对话而设计。
它能自主调用工具、执行命令、生成与调试代码,甚至完成复杂的多步骤流程。
在一场演示中,Kimi-K2完成了一整套薪资数据分析任务,包括:数据抓取、统计建模、并生成交互式HTML页面,内嵌可定制的推荐工具,全流程无需人工干预。
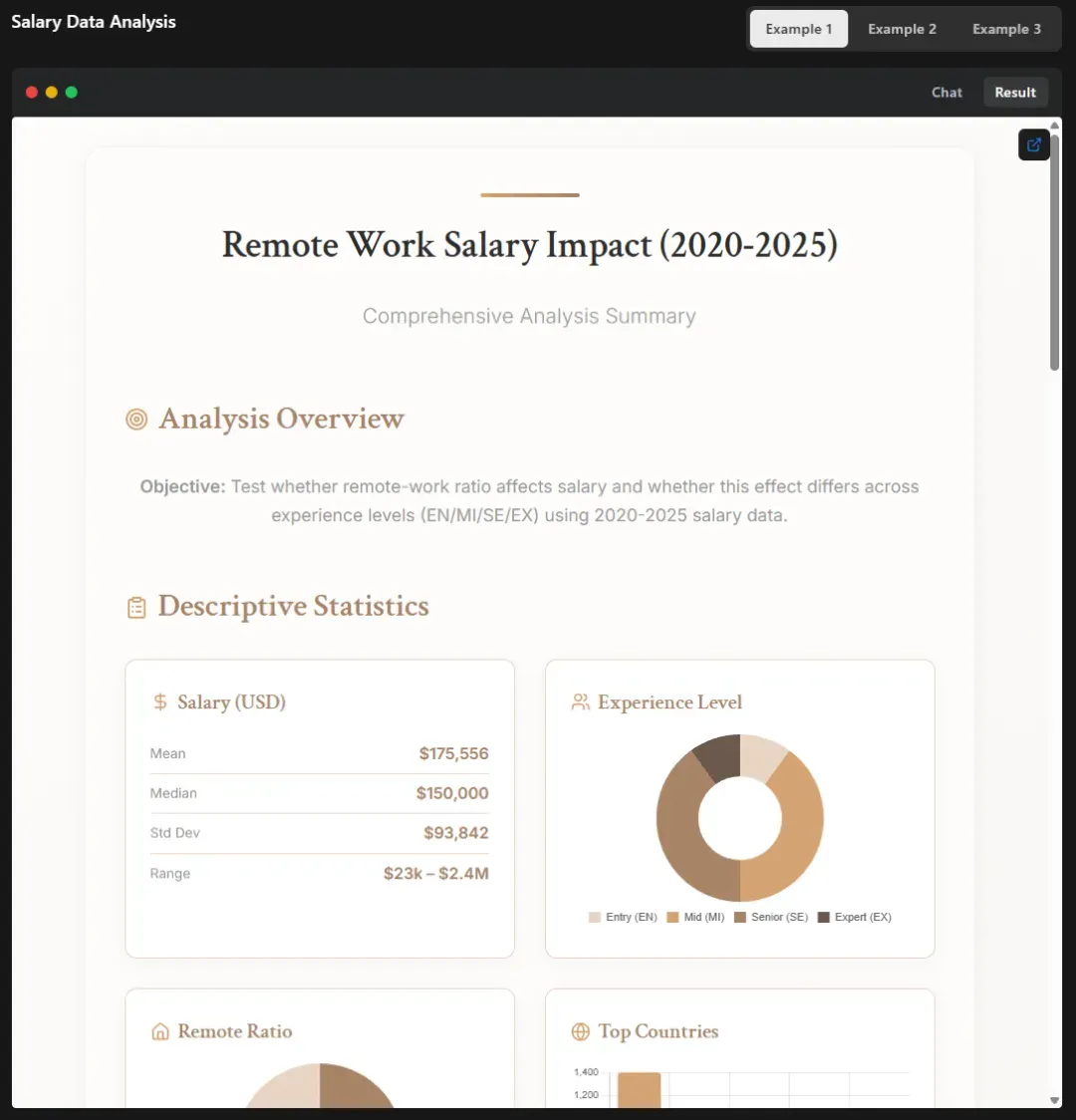
它不仅仅能“理解指令”,还能构建复杂流程,从想法到产品,Kimi-K2一次完成。
媒体报道称,这一切并非依赖庞大的推理系统,而是源于其在Agent环境中进行的强化学习训练,重点在于“工具协作”而非“逻辑演绎”。
分析认为,这种以“任务完成”为核心的训练方向,可能比传统的“思考过程训练”更适用于实际场景。尽管如此,Kimi-K2仍有局限:如果任务本身不明确,或者工具调用链条过长,模型可能输出拖沓或不完整。
此外,Kimi-K2在持续对话中的表现远优于单轮问答,这更加印证了其Agent化定位。

意思是:自研的 Muon 优化器,在训练大模型时表现明显好于主流的 AdamW。如果预训练语料是有限的,模型结构也不变,那么“更省 token 的优化器”能训练出“更聪明的模型”
Kimi-K2使用名为MuonClip的新训练算法,在规模达到15.5万亿tokens的训练中保持稳定。该算法通过定期调整注意力机制中的关键参数,成功避免了大模型常见的“训练崩溃”问题。
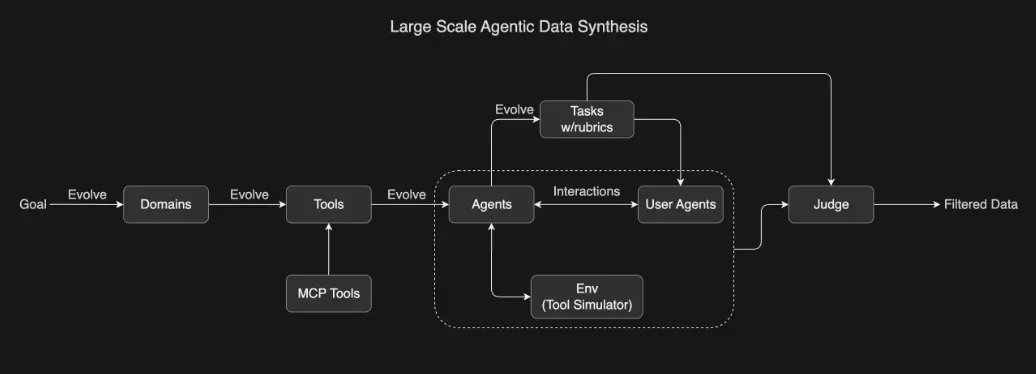
one more thing
Kimi-K2目前提供两个版本:Kimi-K2-Base用于研究与微调,Kimi-K2-Instruct适用于通用任务与Agent部署。
两者均可通过月之暗面的OpenAI兼容API调用,价格分级明确。
缓存命中输入每百万tokens仅需$0.15,未命中为$0.60,输出为$2.50,符合商业化预期。
月之暗面还允许开发者使用vLLM、SGLang、KTransformers或TensorRT-LLM在本地部署。
在GitHub上可查阅完整的部署说明。
模型遵循MIT开源协议,但对超大规模部署有附加条款:若产品用户超过1亿,或月营收超2000万美元,需在界面明确展示“Kimi-K2”名称。
这对于大多数初创公司或开发者来说不构成障碍,反而是品牌信用的体现。
不过,Kimi-K2并非轻装上阵:推理需调用320亿参数,高效推理通常需多卡Hopper或同级GPU。
据苹果开发者Awni Hannun透露,其4-bit量化版本可在两台配备512GB内存的Apple M3 Ultra机器上运行,但门槛依然显著。


