模型

八个数据集全面胜出!思维链推理刷新图学习表现上限
思维链提示学习来了! 由于图数据拥有复杂的非线性结构和缺少文本信息,语言模型中的思维链(Chain-of-Thought,CoT)提示学习方法难以简单直接地应用于图数据。 基于此,来自新加坡管理大学和中国科学技术大学的研究者们提出了GCoT——首个应用于无文本图数据的类思维链提示学习框架。

你永远叫不醒装睡的大模型!多轮对话全军覆没,性能暴跌39%
ChatGPT将大模型技术推动到「对话」场景,直接引发了AI技术的爆炸式增长。 用户可以先提出一个粗糙的、不明确的问题,再根据模型的回答逐步完善指令、补充细节,多轮对话也催生出「跟AI打电话」等有趣的应用设计。 不过,现有的大模型性能评估基准仍然是基于单轮对话机制,输入的指令也更长,信息更完善,其在真实场景中多轮对话的性能仍然没有得到很好地评估。

苹果炮轰推理模型全是假思考!4个游戏戳破神话,o3/DeepSeek高难度全崩溃
苹果最新大模型论文,在AI圈炸开了锅。 有人总结到:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。 这篇论文称推理模型全都没在真正思考,无论DeepSeek、o3-mini还是Claude 3.7都只是另一种形式的“模式匹配”,所谓思考只是一种假象。
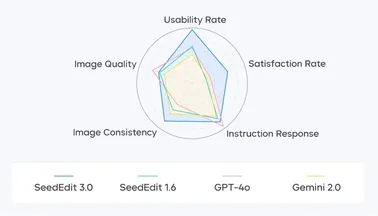
字节跳动发布图像编辑模型SeedEdit 3.0 细节保持能力进一步提升
6月6日,字节跳动Seed团队正式发布了图像编辑模型SeedEdit3.0。 这一全新版本的图像编辑模型在图像主体保持、背景细节处理以及指令遵循等方面取得了显著进步,极大地提升了图像编辑的可用率和效率。 SeedEdit3.0是基于文生图模型Seedream3.0开发的,通过引入多样化的数据融合方法和特定奖励模型,解决了以往图像编辑模型在主体与背景保持、指令遵循等方面的不足。

12.1万高难度数学题让模型性能大涨,覆盖FIMO/Putnam等顶级赛事难度,腾讯上海交大出品
12.1万道IMO级难度数学“特训题”,让AI学会像人类一样推导数学证明! “特训”过后,模型定理证明性能大涨,7B模型性能比肩或超越现有的开源模型和Claude3.7等商业模型。 “特训题”为DeepTheorem,是首个基于自然语言的数学定理证明框架与数据集,由腾讯AI Lab与上海交大团队联合推出。

Gemini新版蝉联竞技场榜一,但刚发布就被越狱了
没等来o3 Pro和GPT-5,隔壁谷歌的Gemini先更新了。 深夜,谷歌通过等多个账号同时官宣,Gemini 2.5 Pro再次推出新版本(0605)。 新版本在代码、推理等任务上的表现更上一层楼,在超难数据集“人类最后的考试”中以21.6%的成绩超过了o3。

阿里智能体多轮推理超越GPT-4o,开源模型也能做Deep Research
能够完成多步信息检索任务,涵盖多轮推理与连续动作执行的智能体来了。 通义实验室推出WebWalker(ACL2025)续作自主信息检索智能体WebDancer。 WebDancer 通过系统化的训练范式——涵盖从数据构建到算法设计的全流程——为构建具备长期信息检索能力的智能体提供了明确路径。

清华给电子显微镜加上Agent,DeepSeek V3全程调度,数天流程缩短至几分钟
AI Agent又解锁了一个领域! 清华大学牵头,与西北工业大学以及上海AI lab等机构推出了电镜领域的AI agent——AutoMat。 它相当于一位精准的“地图翻译官”,把原子级 STEM 图像自动转成标准 CIF 结构,并一步到位给出形成能等关键物性。

苹果拆解AI大脑,推理模型全是「装」的?Bengio兄弟合著
AI「思考」只是假象? 刚刚,一项来自苹果的重磅研究揭示了「大推理模型(LRM)」背后的惊人真相——这些看似聪明的模型,在面对稍复杂点的题目时,准确率居然会全面崩溃! 随着问题变难,推理模型初始会延长思考,但随后思考深度反而下降,尽管仍有充足token预算——它们恰在最需要深入思考时选择了放弃!

危险?OpenAI 模型行为负责人:人类很快会进入「AI意识」,当前最重要是控制人机关系的影响
AI是否真的有意识? ChatGPT最近越来越懂你了? OpenAI模型行为与政策负责人Joanne Jang刚刚写了一篇长文,她并未纠缠于“AI是否真的有意识”这个哲学难题,而是提出了一个更具现实意义和紧迫性的视角:与其争论AI的“本体”,不如关注它对人类“情感福祉”的实际影响。

精准调控大模型生成与推理!浙大&腾讯新方法尝试为其注入“行为定向剂”
如果你面前有两个AI助手:一个能力超强却总爱“离经叛道”,另一个规规矩矩却经常“答非所问”,你会怎么选? 这正是当前大模型控制面临的两难困境:要么模型聪明却难以约束,要么守规矩却缺乏实用性。 但我们真正追求的,并不是在“聪明但难控”与“听话但愚钝”之间二选一,而是打造既强又好的AI助手——既具备强大的智能能力,又能始终按照人类意图行事。

Qwen&清华团队颠覆常识:大模型强化学习仅用20%关键token,比用全部token训练还好
近期arxiv最热门论文,Qwen&清华LeapLab团队最新成果:在强化学习训练大模型推理能力时,仅仅20%的高熵token就能撑起整个训练效果,甚至比用全部token训练还要好。 团队用这个发现在Qwen3-32B上创造了新的SOTA记录:AIME’24上达到63.5分,AIME’25上达到56.7分,这是600B参数以下直接从base模型训练的最高分。 最大响应长度从20k延长到29k,AIME’24的分数更是飙升到了68.1分。

性能大涨!阿里开源新版Qwen3模型,霸榜文本表征
今天凌晨,阿里巴巴开源了两款Qwen3系列新模型,Qwen3-Embedding和Qwen3-Reranker。 这两个模型是专为文本表征、检索与排序任务设计,基于 Qwen3基础模型训练,充分继承了Qwen 3在多语言文本理解方面的优势,支持119种语言。 根据测试数据显示,在多语言文本表征基准测试中,Qwen3 Embedding的性能非常出色。

让GPU不再摸鱼!清华蚂蚁联合开源首个全异步RL,一夜击穿14B SOTA
还记得今年初DeepSeek‑R1系列把纯强化学习(RL)训练开源,点燃社区对于RL的热情吗? 不久后,来自清华蚂蚁联合开源项目AReaL(v0.1)也通过在DeepSeek-R1-Distill-Qwen-1.5B上进行RL训练,观察到模型性能的持续提升。 AReaL(v0.1)在40小时内,使用RL训练的一个1.5B参数模型,在数学推理方面就超越了o1-Preview版本。

真实联网搜索Agent,7B媲美满血R1,华为盘古DeepDiver给出开域信息获取新解法
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。 如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略? 华为诺亚方舟实验室研究团队提出了 Pangu DeepDiver 模型,通过 Search Intensity Scaling 实现了 LLM 搜索引擎自主交互的全新范式,使得 Pangu 7B 模型在开域信息获取能力上可以接近百倍参数的 DeepSeek-R1,并优于 DeepResearcher、R1-Searcher 等业界同期工作!

推理时间减少70%!前馈3DGS「压缩神器」来了,浙大Monash联合出品
在增强现实(AR)和虚拟现实(VR)等前沿应用领域,新视角合成(Novel View Synthesis,NVS)正扮演着越来越关键的角色。 3D高斯泼溅(3D Gaussian Splatting,3DGS)凭借其革命性的实时渲染能力和卓越的视觉质量,迅速成为NVS领域备受关注的技术方案。 现有的前馈3D高斯泼溅(Feed-Forward 3D Gaussian Splatting,3DGS)模型,虽然在实时渲染和高效生成3D场景方面取得了显著进展,但仍存在一些关键缺陷。

DeepMind揭惊人答案:智能体就是世界模型!跟Ilya 2年前预言竟不谋而合
就在刚刚,DeepMind科学家Jon Richens在ICML 2025上发表的论文,一石激起千层浪。 实现人类水平的智能体(即AGI),是否需要世界模型,还是存在无模型的捷径? 他们从第一性原理出发,揭示了一个令人惊讶的答案——智能体就是世界模型!

大模型结构化推理优势难复制到垂直领域!最新法律AI评估标准来了,抱抱脸评测集趋势第一
大模型推理,无疑是当下最受热议的科技话题之一。 但在数学和物理等STEM之外,当LLM落到更多实际应用领域之中,大模型的推理能力又有多大的潜能和局限? 比如,如何评估大模型的推理能力在法律领域的应用,就在当前备受关注。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉