图神经网络还能更聪明?思维链提示学习来了!
由于图数据拥有复杂的非线性结构和缺少文本信息,语言模型中的思维链(Chain-of-Thought,CoT)提示学习方法难以简单直接地应用于图数据。
基于此,来自新加坡管理大学和中国科学技术大学的研究者们提出了GCoT——首个应用于无文本图数据的类思维链提示学习框架。
实验结果表明,GCoT在八个图数据集上的少样本节点分类与图分类任务全面超越现有SOTA方法,尤其在1-5样本的极少样本设置下表现最为显著。

GCoT方法解析
GCoT的核心思想是将下游的推断过程拆分为多个推断步骤。具体包含:
- 将图和提示一并输入到预训练图编码器中进行推断;
- 通过聚合各层隐藏表示来生成“思维”,以学习当前步骤每个节点的表示;
- 基于该思维学习节点专属提示,引导下一步的推断。
研究者们在八个公开数据集上进行了全面实验以评估和分析GCoT。
整体框架
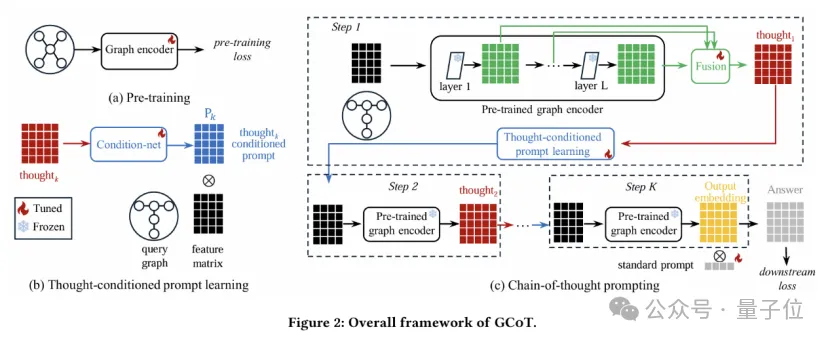
研究者们将思维链提示学习分为三个部分:
1.基于提示的推断
第步推断中,研究者将查询图及其使用提示作用后的特征矩阵输入预训练图编码器以得到各层嵌入表示。
2.思维构建
为有效利用多层结构信息,研究人员将每一层的嵌入表示做加权求和得到融合后的“思维”。
3.基于思维的提示学习Thought conditioned prompt learning
研究人员设计的“思维” 捕获了图中节点的结构知识并用于指导下一步推断。由于每个节点可能具有不同的特质,他们设计了一个条件网络(Condition Net),将上一轮思维作为输入,生成节点的专属性提示矩阵,并将其用于下一步输入特征调整。
标准提示学习
同时研究人员也采用了标准图提示学习方法来进一步对齐上下游任务。参考GPF+,他们训练得到了个偏置项提示并通过注意力机制融合提示向量。
与GPF+方法不同的是,他们将融合得到的提示作用于最终输出的嵌入表示而不是最初始的特征矩阵上。
提示的微调
针对下游任务研究人员设计了损失以便微调模型学习的提示:
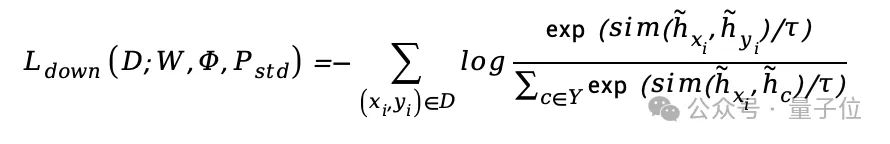
其中,是最终提示后的节点或图的嵌入,是类别的原型向量(所有标签样本嵌入的平均),是温度系数。
实验结果
研究者们在八个基准数据集上进行了全面的实验,评估他们所提出的GCoT在少样本节点分类和图分类任务上的有效性。
少样本学习表现
1-shot节点与整图分类
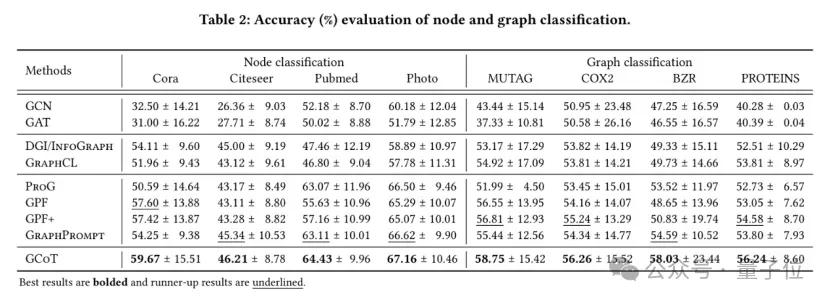
通过上表研究者们得到以下结论:
- GCoT在节点分类以及图分类任务中都超越了其他的基准,展现了其性能的优势和鲁棒性。
- 预训练方法通常优于有监督学习方法,因为前者组利用了预训练模型。这些结果突显了从无标签图中获得通用知识的重要性。
- 图提示学习模型(GPF/GPF+,ProG,GraphPrompt)通常优于基于微调的预训练方法,这源于这些模型通过提示缩小了预训练与下游任务的区别。但是这一些模型都是单步提示,因此表现劣于多步思考提示的GCoT模型。
k-shot节点与整图分类
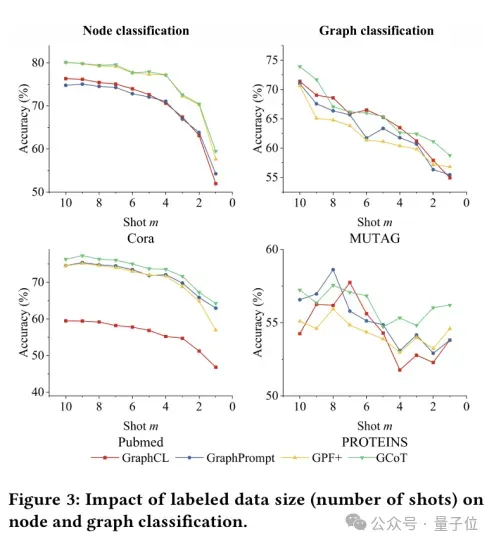
研究者们进一步进行了下游1-10样本数目的实验,具体结果呈现在上图中,他们发现GCoT几乎在所有少样本分类任务中都超越了其他基准,尤其是在1-5少样本数目中。
消融实验
为全面了解GCoT模型中各层的作用,研究者们进一步设计了两项消融实验:
- 逐层研究GCoT各个部分的单独作用
- 研究CoT作用于其它基准模型上的影响
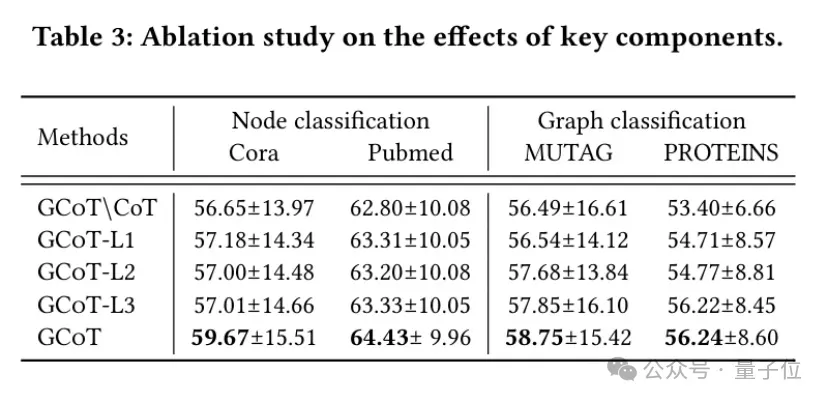
首先他们对GCoT的四种变体做了对比实验。毫无疑问,完整的GCoT依然是最优,去除了所有推断的GCoT\CoT结果凸显了分步推断机制的重要性,使用了单步推断的GCoT\L1,L2,L3则验证了多步推断融合各层级的信息的有效性。
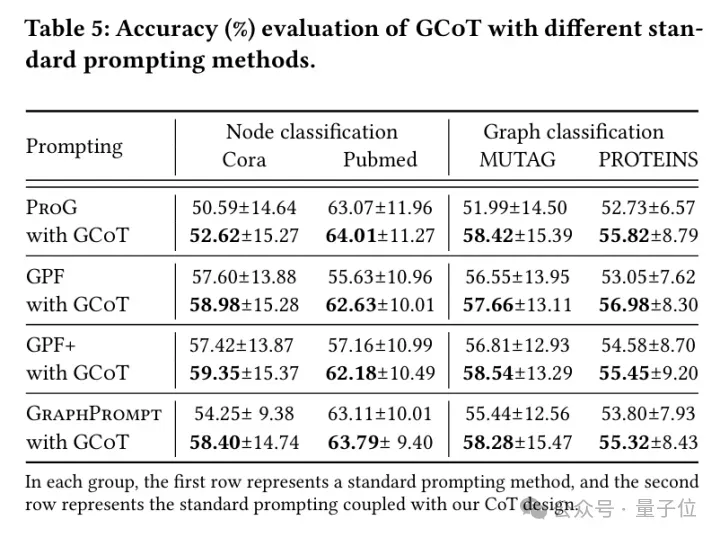
其次研究者们将CoT设计加入图提示学习的其它基准模型中(GPF,GPF+,ProG,GraphPrompt),并再次研究这些模型的性能,结果呈现在上表中。
他们观察到对于所有的模型加入了CoT后效果都有提升,这进一步表明了他们设计的GCoT可以广泛适用于各种图提示学习模型,并在节点分类与图分类上有通用性。
总结
本文中研究者提出的GCoT是首次将思维链提示学习框架扩展到无文本图数据上的尝试,具体而言他们做了如下设计:
逐步推断机制通过逐步推断将思维链提示学习引入图学习中,每步推断包含“基于提示的推断”、“思维构建”以及“基于思维的提示学习”过程。
融合生成思维提示首先将经过提示修改的查询图输入预训练图编码器,随后通过融合编码器所有层的隐藏嵌入来构建思维向量,以捕获层次化结构知识。
节点特定提示基于每步思维生成的提示向量,生成一系列节点特定提示来引导下一步推断。
他们在八个图数据集上进行了广泛实验,涵盖节点分类与图分类两类任务,结果表明GCoT在少样本学习中相较现有SOTA方法具有显著优势。
作为一种面向无文本图的尝试性框架,GCoT在一定程度上拓展了现有图学习方法的推理方式,也为后续相关研究提供了新的思路。
论文链接:https://arxiv.org/pdf/2502.08092代码链接:https://github.com/Eric-Kuai/GCoT


