GPU
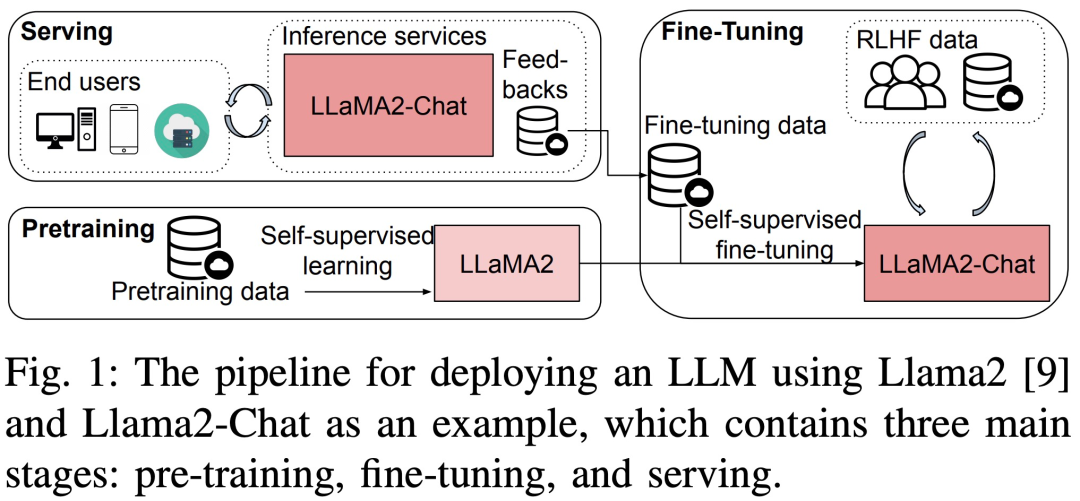
Llama2推理RTX3090胜过4090,延迟吞吐量占优,但被A800远远甩开
这是为数不多深入比较使用消费级 GPU(RTX 3090、4090)和服务器显卡(A800)进行大模型预训练、微调和推理的论文。大型语言模型 (LLM) 在学界和业界都取得了巨大的进展。但训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的开源框架和方法。然而,不同硬件和软件堆栈的运行时性能可能存在很大差异,这使得选择最佳配置变得困难。最近,一篇题为《Dissecting the Runtime Performance of the Training,
4090成A100平替?上交大推出推理引擎PowerInfer,token生成速率只比A100低18%
机器之心报道机器之心编辑部PowerInfer 使得在消费级硬件上运行 AI 更加高效。上海交大团队,刚刚推出超强 CPU/GPU LLM 高速推理引擎 PowerInfer。项目地址::?在运行 Falcon (ReLU)-40B-FP16 的单个 RTX 4090 (24G) 上,PowerInfer 对比 llama.cpp 实现了 11 倍加速!PowerInfer 和 llama.cpp 都在相同的硬件上运行,并充分利用了 RTX 4090 上的 VRAM。在单个 NVIDIA RTX 4090 GPU
你的GPU能跑Llama 2等大模型吗?用这个开源项目上手测一测
你的 GPU 内存够用吗?这有一个项目,可以提前帮你查看。在算力为王的时代,你的 GPU 可以顺畅的运行大模型(LLM)吗?对于这一问题,很多人都难以给出确切的回答,不知该如何计算 GPU 内存。因为查看 GPU 可以处理哪些 LLM 并不像查看模型大小那么容易,在推理期间(KV 缓存)模型会占用大量内存,例如,llama-2-7b 的序列长度为 1000,需要 1GB 的额外内存。不仅如此,模型在训练期间,KV 缓存、激活和量化都会占用大量内存。我们不禁要问,能不能提前了解上述内存的占用情况。近几日,GitHub
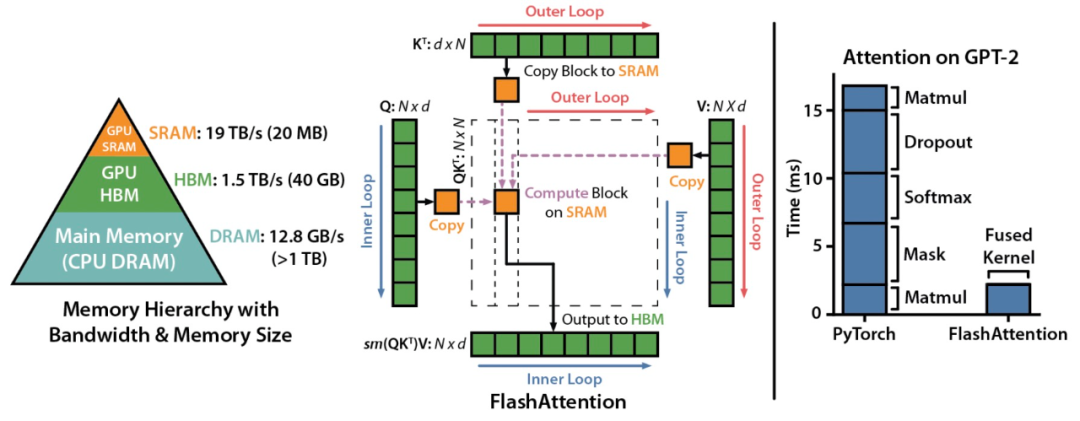
比标准Attention提速5-9倍,大模型都在用的FlashAttention v2来了
一年时间,斯坦福大学提出的新型 Attention 算法 ——FlashAttention 完成了进化。这次在算法、并行化和工作分区等方面都有了显著改进,对大模型的适用性也更强了。
思考一下,联邦学习可以训练大语言模型吗?
满足在垂直领域中的应用需求,能用联邦学习训练LLM吗?
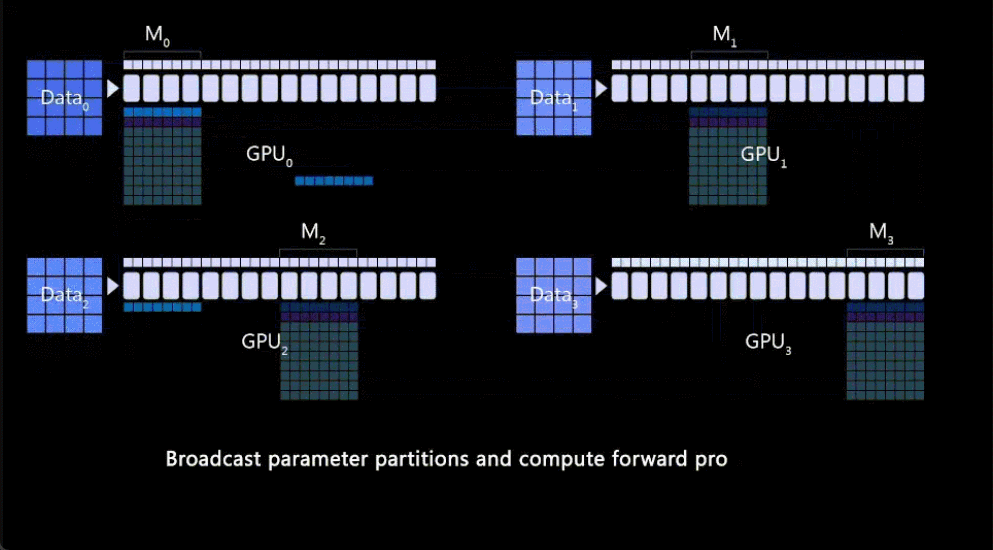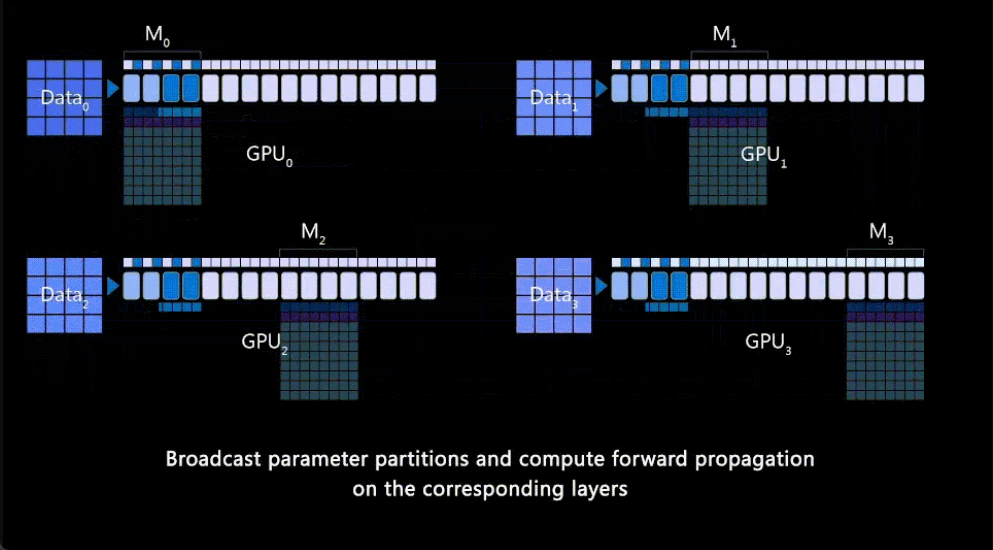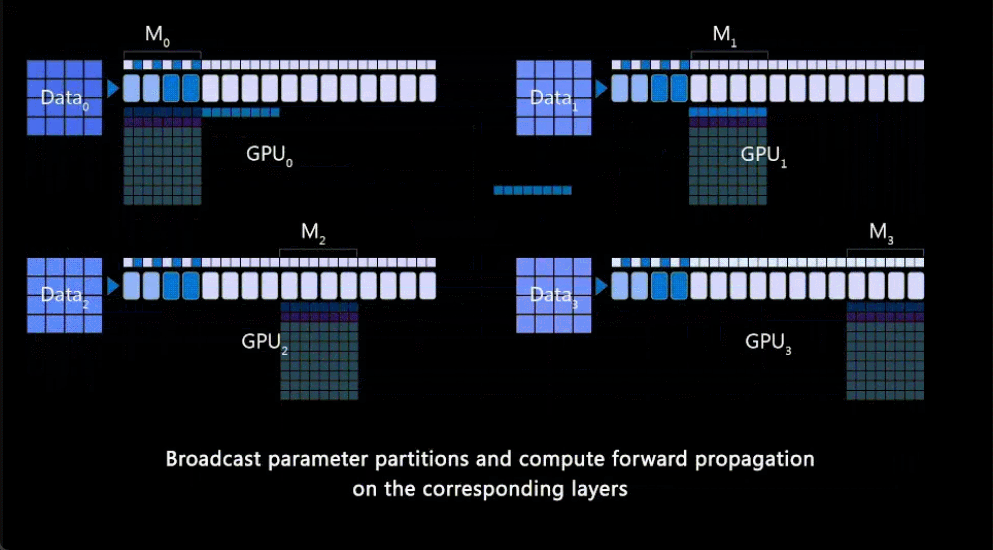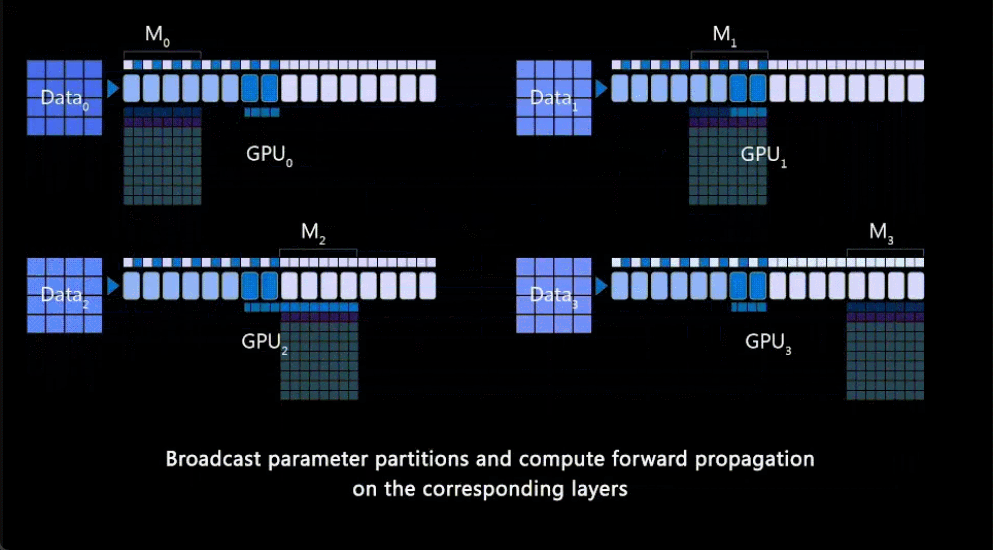
DeepSpeed ZeRO++:降低4倍网络通信,显著提高大模型及类ChatGPT模型训练效率
。ZeRO++ 相比 ZeRO 将总通信量减少了 4 倍,而不会影响模型质量。
参会抽RTX 4090,GTC23 China AI Day定档3月22日,嘉宾阵容公布
面向全球 AI 开发者的 GTC 2023 将于3月20 – 23日在线上举办,这场被 NVIDIA 创始人兼首席执行官黄仁勋描述为 「迄今为止最重要的一次 GTC」,将带来650多场演讲、专家座谈会和特别活动,几乎涵盖了计算领域的所有热门内容,预计将有超过25万人报名参加。本届 GTC 设有专门为中国 AI 从业者举办的特别活动 — China AI Day。活动将于3月22日下午1点开始,邀您一同探讨互联网、数字孪生、元宇宙领域的前沿的 AI 应用。来自阿里巴巴、百度、快手、腾讯、网易、字节跳动等领先 AI 智
跑ChatGPT体量模型,从此只需一块GPU:加速百倍的方法来了
1750 亿参数,只需要一块 RTX 3090,ChatGPT 终于不再是大厂专属的游戏?
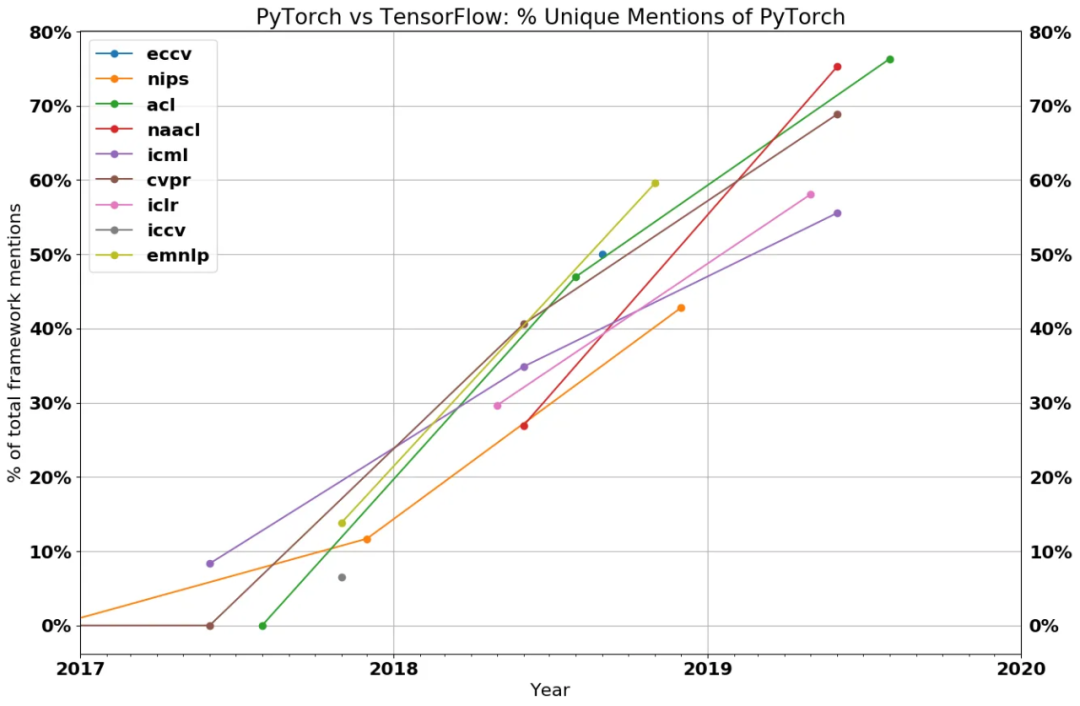
和TensorFlow一样,英伟达CUDA的垄断格局将被打破?
CUDA 闭源库将和 TensorFlow 一样逐渐式微。

用什么tricks能让模型训练得更快?先了解下这个问题的第一性原理
深度学习是门玄学?也不完全是。
详解AI加速器(一):2012年的AlexNet到底做对了什么?
AI、机器学习、深度学习的概念可以追溯到几十年前,然而,它们在过去的十几年里才真正流行起来,这是为什么呢?AlexNet 的基本结构和之前的 CNN 架构也没有本质区别,为什么就能一鸣惊人?在这一系列文章中,前苹果、飞利浦、Mellanox(现属英伟达)工程师、普林斯顿大学博士 Adi Fuchs 尝试从 AI 加速器的角度为我们寻找这些问题的答案。当代世界正在经历一场革命,人类的体验从未与科技如此紧密地结合在一起。过去,科技公司通过观察用户行为、研究市场趋势,在一个通常需要数月甚至数年时间的周期中优化产品线来改进

一块V100运行上千个智能体、数千个环境,这个「曲率引擎」框架实现RL百倍提速
在强化学习研究中,一个实验就要跑数天或数周,有没有更快的方法?近日,来自 SalesForce 的研究者提出了一种名为 WarpDrive(曲率引擎)的开源框架,它可以在一个 V100 GPU 上并行运行、训练数千个强化学习环境和上千个智能体。实验结果表明,与 CPU+GPU 的 RL 实现相比,WarpDrive 靠一个 GPU 实现的 RL 要快几个数量级。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉