GPU

微软用「光」跑AI登上Nature!100倍能效颠覆GPU,华人首席研究员扛鼎
过去的几十年,各大公司都在芯片上暗暗较劲:芯片涨价、GPU短缺、AI算力焦虑...就在大家盯着芯片迭代升级时,微软在悄悄做另一件事:用光重新定义计算。 他们花了四年,用手机摄像头、Micro LED和透镜,拼出了一台模拟光学计算机(AOC)。 如今,这个实验已经登上Nature,带来了一个足以颠覆GPU的未来想象。

报道称:OpenAI 与博通合作开发自家 AI 芯片,明年开始量产
OpenAI 正在与美国芯片制造商博通合作,计划在明年推出自家的人工智能(AI)芯片。 这一举动是 OpenAI 在行业内寻求独立于第三方半导体公司的重要一步。 根据《金融时报》的报道,这款新型图形处理单元(GPU)将专门用于 OpenAI 的内部用途,而不会对外销售。

一文带你开启 SmartNotebook 的 GPU 支持(PyTorch 实测)
在数据科学与深度学习的日常工作中,GPU 已经成为不可或缺的计算加速工具。 无论是训练大规模 Transformer 模型,还是运行复杂的图像处理与科学计算任务,GPU 都能显著提升性能。 SmartNotebook 作为一款类似 Hex.tech 的现代化 DataNotebook 平台,不仅支持在容器环境中快速部署,还可以通过简单的配置实现 GPU 加速,让用户在 DataNotebook 内即可运行深度学习任务。

AI工厂:国产GPU的算力进化
训练大模型,有点像炼丹。 而算力,就是炼丹炉里的柴。 只有炉火纯青,才能真正炼出好丹。

马斯克23万GPU训练Grok-这规模让OpenAI都要颤抖
马斯克昨天在X上发了一条消息:"xAI的目标是在5年内部署相当于5000万个H100的AI算力。 "5000万个H100,这什么概念? 我算了一下,这相当于35个核电站的发电量才能供得起。

惊到了!大神炮轰CUDA:CUDA存致命缺陷,它不是未来!这种新语言将打破英伟达的GPU垄断地位,护城河终会消失!
编辑 | 云昭CUDA一直被视为英伟达GPU的最强壁垒,让许多业界的玩家望洋兴叹。 但,今天这篇文章会给各位习惯C 、CUDA开发的大佬提个醒:有一种新的编程语言,正在AI圈兴起,撬动英伟达的围墙花园。 而CUDA也不再是护城河。

老黄再收95后华人才俊!4亿美元收购AI初创公司
鹭羽 白交 发自 凹非寺. 量子位 | 公众号 QbitAI又一家95后华人AI初创,被老黄收购! 仅四亿美金的收购金额,就把员工全部打包带回英伟达。

刚刚,Ilya官宣出任SSI CEO!送走「叛徒」联创,豪言不缺GPU
小扎到处挖人的举动,不仅是惹恼了奥特曼,连Ilya都忍无可忍,被炸出来了! 就在刚刚,消失许久的Ilya忽然现身X。 他发文表示,自己已亲自挂帅「安全超级智能」(SSI)的CEO。

韩国计划未来5年在人工智能领域投入16万亿韩元
据媒体报道,韩联社援引韩国科技部向总统国政规划委员会报告的计划称,韩国政府将在未来 5 年内在人工智能领域投入16. 1 万亿韩元。 保障 5 万颗GPU安全供应,打造AI数据中心。

免费GPU算力部署DeepSeek-R1 32B
前言DeepSeek-R1发布最新版本DeepSeek-R1-0528,显著提升了模型的思维深度与推理能力,在数学、编程与通用逻辑等多个基准测评中取得了当前国内所有模型中首屈一指的优异成绩,并且在整体表现上已接近其他国际顶尖模型,如 o3 与 Gemini-2.5-Pro。 另外,API接口还增加了Function Calling和JsonOutput 的支持。 DeepSeek-R1团队已经证明,大模型的推理模式可以蒸馏到小模型中,与通过强化学习在小模型上发现的推理模式相比,性能更优。

Meta「轻量级」KernelLLM颠覆GPU内核生成,8B参数碾压GPT-4o
在AI领域,参数规模曾被视为「性能天花板」。 Meta最新发布的KernelLLM,却用8B参数的「小身板」,在GPU内核生成任务中把200B的GPT-4o按在地上摩擦。 这是一个基于Llama 3.1 Instruct进行微调的8B参数模型,旨在将PyTorch模块自动转换为高效的Triton GPU内核。
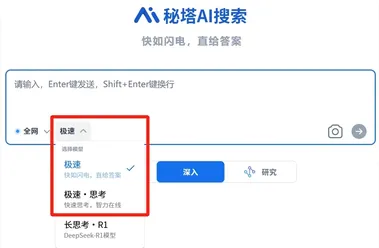
秘塔AI搜索推出全新“极速”模型:最高400 tokens/秒响应速度
近日,秘塔AI搜索正式推出全新“极速”模型,为用户带来更高效、精准的搜索体验。 秘塔AI搜索团队通过在GPU上进行kernel fusion技术,以及在CPU上实施动态编译优化策略,成功在单张H800GPU上实现了最高400tokens/秒的响应速度,大部分问题能在2秒内给出答案。 为了让用户更真切地感受新模型的速度,秘塔AI搜索还特别搭建了一个测速站点(kuai.metaso.cn),用户可随时输入问题,亲自体验新模型带来的快速响应。

NVIDIA全新GeForce GPU震撼亮相!黄仁勋:AI与模拟交织,极致美感颠覆游戏与创作!
NVIDIA在台北COMPUTEX2025大会上正式发布全新GeForce GPU系列,引发全球科技圈热议。 NVIDIA首席执行官黄仁勋在主题演讲中表示:“你在这里看到的都不是艺术,只是恰好很美而已”,强调新GPU通过人工智能与实时模拟的融合,为游戏玩家、内容创作者和AI开发者带来前所未有的视觉与性能体验。 AIbase综合最新动态,深入解析这一突破性发布的技术亮点及其对AI与游戏生态的深远影响。

5090将被秘密定位?美或强制植入「地理追踪」,锁定英伟达高端GPU
最近,美参议员Tom Cotton提出了一项新法案——要为英伟达、AMD等高端GPU装上「地理追踪」功能,防止落入竞争国家手中。 此举,不仅针对的是AI芯片,还涵盖了高性能游戏显卡等硬件。 若是法案通过,这些措施将在6个月后生效。

Fastino 融资 1750 万美元,利用廉价游戏 GPU 训练 AI 模型
在当今科技行业,AI(人工智能)正迅速崛起,许多巨头公司都在大谈特谈拥有万亿参数的 AI 模型,这些模型通常需要耗费巨资搭建庞大的 GPU 集群。 然而,Fastino 却走了一条不同的道路,利用成本低廉的游戏 GPU 进行 AI 模型训练,并成功获得了由 Khosla Ventures 领投的1750万美元融资。 这一创新的方式使得 Fastino 能够在资源有限的情况下,实现高效的 AI 模型开发。

AI学会“无师自通”?AZR让模型左右互搏,越打越聪明!
一项名为Absolute Zero Reasoner(AZR)的创新项目近日引发广泛关注。 该项目通过一种全新的“绝对零点”训练范式,让大型语言模型(LLM)能够自主提出问题、编写代码、运行验证,并通过自我博弈(self-play)循环提升编程与数学能力。 基于Qwen2.5-7B模型的测试数据显示,AZR在编程能力上提升了5分,数学能力提升了15.2分(满分100分),展现了其在AI自进化领域的巨大潜力。

北京:对采购自主可控 GPU 芯片开展智能算力服务的民营企业按照投资额一定比例给予支持
《北京市促进民营经济健康发展、高质量发展2025年工作要点》近日发布。其中提出,北京将支持民营企业建设智算中心,对采购自主可控GPU芯片开展智能算力服务的企业,按照投资额的一定比例给予支持,还将重点支持民营企业参与绿色创新平台建设。

流体力学专用版DeepSeek,单GPU可跑,成本节约高达100倍
又一专业领域成功引入AI工程师! 而且还是基于DeepSeek、Qwen等国产大模型打造,国内研究人员都能用的那种。 不卖关子了,这就是由英国埃克塞特大学初旭副教授团队与北航王文康副教授团队联合打造的OpenFOAMGPT,将AI工程师成功引入计算流体力学(CFD)领域。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉