GPU

图灵奖得主 LeCun 加盟 AI 芯片黑马 Groq,估值 28 亿美元挑战英伟达
英伟达又双叒迎来强劲挑战者了。成立于 2016 年的初创公司 Groq 在最新一轮融资中筹集了 6.4 亿美元,由 BlackRock Inc. 基金领投,并得到了思科和三星投资部门的支持。目前,Groq 的估值已经达到 28 亿美元。公司创始人 Jonathan Ross 曾在谷歌从事 TPU 芯片的开发,而 Groq 目前的顶梁柱 LPU 也是专门用于加速 AI 基础模型,尤其是 LLM。Ross 表示,一旦人们看到在 Groq 的快速引擎上使用大语言模型有多么方便,LLM 的使用量将会进一步增加。以更低的价格

小扎自曝砸重金训 Meta Llama 4 模型:24 万块 GPU 齐发力,预计 2025 年发布
Llama 3.1 刚发布不久,Llama 4 已完全投入训练中。这几天,小扎在二季度财报会上称,Meta 将用 Llama 3 的十倍计算量,训练下一代多模态 Llama 4,预计在 2025 年发布。这笔账单,老黄又成为最大赢家十倍计算量,是什么概念?要知道,Llama 3 是在两个拥有 24,000 块 GPU 集群完成训练。也就是说,Llama 4 训练要用 24 万块 GPU。那么,Meta 存货还够不够?还记得小扎曾在年初宣布,计划到年底要部署 35 万块英伟达 H100。他还透露了更多的细节,Meta

Llama3.1 训练平均 3 小时故障一次,H100 万卡集群好脆弱,气温波动都会影响吞吐量
每 3 个小时 1 次、平均 1 天 8 次,Llama 3.1 405B 预训练老出故障,H100 是罪魁祸首?最近有人从 Meta 发布的 92 页超长 Llama 3.1 论文中发现了华点:Llama 3.1 在为期 54 天的预训练期间,经历了共 466 次任务中断。其中只有 47 次是计划内的,419 次纯属意外,意外中 78% 已确认或怀疑是硬件问题导致。而且 GPU 问题最严重,占了 58.7%。Llama 3.1 405 模型是在一个含 16384 块 Nvidia H100 80GB GPU 集群

Meta 训练 Llama 3 遭遇频繁故障:16384 块 H100 GPU 训练集群每 3 小时“罢工”一次
Meta 发布的一份研究报告显示,其用于训练 4050 亿参数模型 Llama 3 的 16384 个英伟达 H100 显卡集群在 54 天内出现了 419 次意外故障,平均每三小时就有一次。其中,一半以上的故障是由显卡或其搭载的高带宽内存(HBM3)引起的。由于系统规模巨大且任务高度同步,单个显卡故障可能导致整个训练任务中断,需要重新开始。尽管如此,Meta 团队还是保持了 90% 以上的有效训练时间。AI在线注意到,在为期 54 天的预预训练中,共出现了 466 次工作中断,其中 47 次是计划中断,419 次

马斯克的“世界最强大 AI 数据中心”目前由 14 台移动发电机供电,引环保担忧
埃隆・马斯克的孟菲斯超级计算集群(Memphis Supercluster)已上线,据马斯克介绍称,该集群在单个 RDMA fabric 上使用 10 万张液冷 H100,是“世界上最强大的 AI 训练集群”。如此庞大的算力自然需要惊人的电力供应,每个 H100 GPU 至少消耗 700 瓦电力,这意味着整个数据中心同时运行需要超过 70 兆瓦的电力,这还不包括其他服务器、网络和冷却设备的耗电量。令人惊讶的是,由于与当地电网的供电协议尚未敲定,马斯克目前使用 14 台大型移动发电机为这个巨型设施供电。AI 和半导体
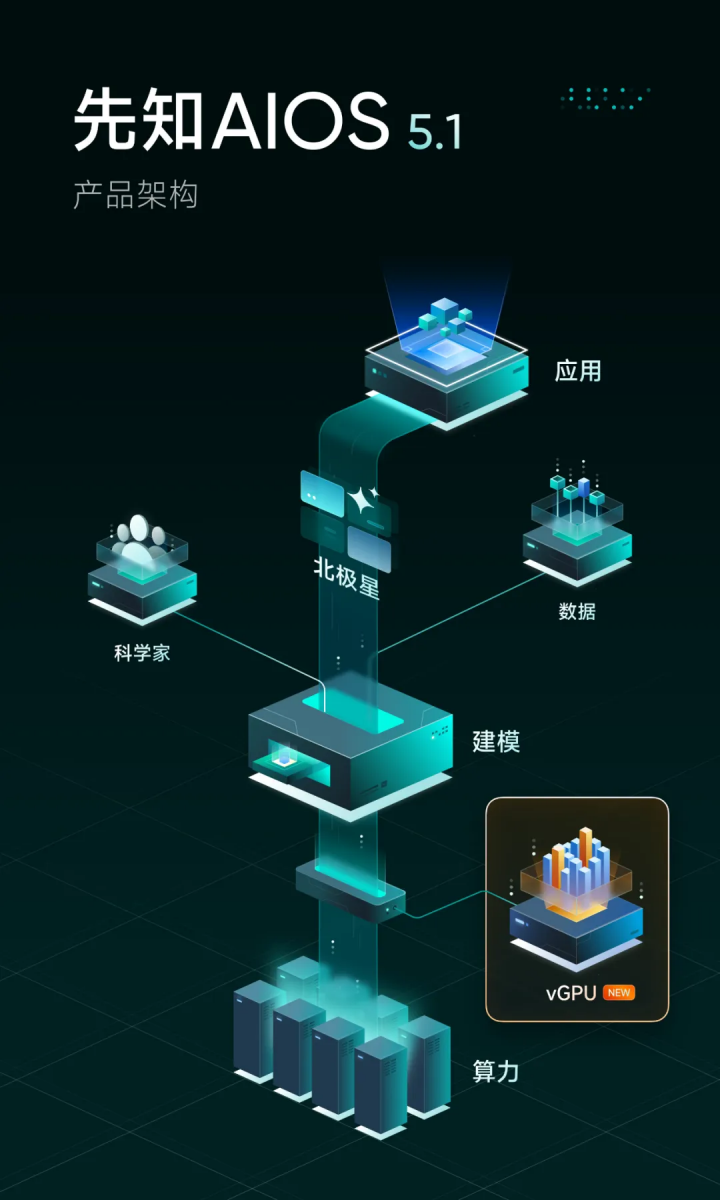
第四范式发布先知AIOS 5.1,升级支持GPU资源池化功能
今天,第四范式先知AIOS 5.1版本正式发布。该版本新增GPU资源池化(vGPU)能力,实现对硬件集群平台化管理、算力资源的按需分配和快速调度,最多节省80%的硬件成本,提高GPU综合利用率多达5-10倍。第四范式先知AIOS 5是行业大模型开发及管理平台。平台以提升企业核心竞争力为目标,在支持接入企业各类模态数据的基础上,提供大模型训练、精调等低门槛建模工具、科学家创新服务体系、北极星策略管理平台、大模型纳管平台、主流算力适配优化等能力,实现端到端的行业大模型的构建、部署、管理服务。在行业大模型的构建过程中,为

投资巨头高盛质疑 AI 投资回报:巨额投入能否换来光明未来?
全球知名投行高盛 (Goldman Sachs) 近期对人工智能 (AI) 投资的回报率提出了质疑。尽管各大企业和投资者正斥资数十亿美元用于人工智能研发,但高盛担忧如此巨额的投入能否真正带来丰厚回报。图源 Pexels目前,我们使用的 LLM 大型语言模型(例如 GPT-4o)训练成本就高达数亿美元,下一代模型的训练成本更是预计将飙升至 10 亿美元。风投巨头红杉资本 (Sequoia Capital) 经过测算后表示,整个 AI 行业每年都需要产生 6000 亿美元(AI在线备注:当前约 4.36 万亿元人民币)

暴涨 8050%,富国银行预估 2030 年 AI 产业用电激增至 652 TWh
富国银行(Wells Fargo)预测今年 AI 用电需求为 8 TWh,而到 2030 年将激增到 652 TWh,将增长 8050%。富国银行表示 AI 用电主要用于训练 AI 模型方面,在 2026 年将达到 40 TWh,到 2030 年将达到 402 TWh;此外 AI 推理耗电量将会在 21 世纪 20 年代末出现快速增长。如果单纯看这个数字可能没有直观的感觉,那么这里再附上一组数据:2023 年中国全年用电为 9224.1 TWh,上海市全年用电为 184.9 TWh,深圳市全年用电为 112.8 T

AI 泡沫加剧,红杉资本:年产值 6000 亿美元才够支付硬件开支
红杉资本(Sequoia Capital)的分析师大卫・卡恩(David Cahn)发布报告,认为 AI 产业泡沫家居,年产值超过 6000 亿美元,才够支付数据中心、加速 GPU 卡等 AI 基础设施费用。英伟达 2023 年数据中心硬件收入达到 475 亿美元(其中大部分硬件是用于 AI 和 HPC 应用的计算 GPU)。此外 AWS、谷歌、Meta、微软等公司在 2023 年也在 AI 方面投入了大量资金,卡恩认为这些投资很难在短期内回本。卡恩只是粗略估算了 AI 运行成本,首先将英伟达的 run-rate

全球 AI 面临 6000 亿美元难题,人工智能泡沫正在接近临界点
【新智元导读】AI 基础设施的巨额投资,和实际的 AI 生态系统实际收入之间,差距已经到了不可思议的地步。曾经全球 AI 面临的 2000 亿美元难题,如今已经翻成了 6000 亿美元。现在,业内关于 AI 模型收入的质疑声,已经越来越大。动辄投入几万亿美元打造基础设施,跟部分国家的 GDP 不相上下,然而从 AI 模型中得到的回报,究竟能有几何?在 2023 年 9 月,来自红杉资本的 David Cahn 发表了一篇名为《AI 的 2000 亿美元问题》的文章,目的是探讨:「AI 的收入都去哪了?」根据报告,当

13瓦功耗处理10亿参数,接近大脑效率,消除LLM中的矩阵乘法来颠覆AI现状
编辑 | 萝卜皮通常,矩阵乘法 (MatMul) 在大型语言模型(LLM)总体计算成本中占据主导地位。随着 LLM 扩展到更大的嵌入维度和上下文长度,这方面的成本只会增加。加州大学、LuxiTech 和苏州大学的研究人员声称开发出一种新方法,通过消除过程中的矩阵乘法来更有效地运行人工智能语言模型。这从根本上重新设计了目前由 GPU 芯片加速的神经网络操作方式。研究人员描述了如何在不使用 MatMul 的情况下创建一个自定义的 27 亿参数模型,性能与当前最先进的 Transformer 模型相当。该研究以「Scal

首个类 Sora 开源复现方案,Open Sora 可在英伟达 RTX 3090 显卡上 AI 生成视频:最高 4 秒 240P
作为全球首个类 Sora(OpenAI 的文本生成视频模型)开源复现方案,Open-Sora 可以在英伟达 RTX 3090 GPU 上基于文本生成视频,最高可以生成 240P 分辨率、时长最长 4 秒的视频。处理 AI 任务的 GPU 云服务提供商 Backprop 展示了基于 Open-Sora V1.2 的 AI 环境,展示 4 个基于提示词生成的视频。Backprop 表示:“在 RTX 3090 GPU 上,用户可以生成最高 240p、时长 4 秒的视频,生成 2 秒视频大约需要 30 秒,4 秒视频大约

Yandex 开源 LLM 训练工具节省高达 20% 的 GPU 资源
跨国科技公司 Yandex 最近推出了 YaFSDP,这是一种用于训练大型语言模型 (LLM) 的开源方法。YaFSDP 是目前最有效的公开可用工具,用于增强 GPU 通信并减少 LLM 训练中的内存使用量,与 FSDP 相比,其训练速度提升最高可达 26%,具体取决于架构和参数数量。通过使用 YaFSDP 减少 LLM 的训练时间可以节省高达 20% 的 GPU 资源。Yandex 承诺为全球人工智能社区的发展做出贡献,将YaFSDP开源提供给全球的 LLM 开发人员和人工智能爱好者即是履行此承诺的其中一步。“目

马斯克称将为 xAI 购买约 30 万块英伟达 AI 芯片,预估至少花费 90 亿美元
马斯克北京时间今天凌晨在回复一则投票时透露,xAI 的下一项重大举措可能是在明年夏天购买约 30 万块配备 CX8 网络的 B200 芯片。xAI 已在近期获得了 60 亿美元(IT之家备注:当前约 435.6 亿元人民币)融资,公司估值达到约 180 亿美元(当前约 1306.8 亿元人民币)。目前,xAI 计划通过加大对 GPU 集群的投资,大幅扩展其 AI 相关的产品组合。今年 4 月,X 平台(推特)博主“The Technology Brother”曾发帖表示,Meta 公司目前已经拥有约 35 万个 H

英伟达黄仁勋解读“CEO 数学”:花小钱,办大事
英伟达首席执行官黄仁勋日前在 2024 台北电脑展前夕提出了一个有趣的概念 ——“CEO 数学”。“买得越多,省得越多,” 黄仁勋在演讲中表示,“这就是 CEO 数学,它并不完全准确,但却很有效。”乍一听让人困惑?黄仁勋随后解释了这个概念的含义。他建议企业同时投资图形处理器 (GPU) 和中央处理器 (CPU)。这两种处理器可以协同工作,将任务完成时间从“100 个单位缩短到 1 个单位”。因此,从长远来看,增加投资反而能节省成本。这种结合使用 CPU 和 GPU 的做法在个人电脑领域已经很普遍。“我们往一台 10

黄仁勋一口气解密三代 GPU,量产英伟达 Blackwell 解决 ChatGPT 全球耗电难题
感谢IT之家网友 佳宜 的线索投递!【新智元导读】刚刚,老黄又高调向全世界秀了一把:已经量产的 Blackwell,8 年内将把 1.8 万亿参数 GPT-4 的训练能耗狂砍到 1/350;英伟达惊人的产品迭代,直接原地冲破摩尔定律;Blackwell 的后三代路线图,也一口气被放出。就在刚刚,老黄手持 Blackwell 向全世界展示的那一刻,全场的观众沸腾了。它,是迄今为止世界最大的芯片!▲ 眼前的这块产品,凝聚着数量惊人的技术如果用老黄的话说,它就是「全世界迄今为止制造出来的最复杂、性能最高的计算机。」▲ 8

马斯克旗下 xAI 公司宣布 B 轮融资达 60 亿美元
感谢埃隆・马斯克(Elon Musk)旗下人工智能初创公司 xAI 今日在博客文章中宣布,该公司已在 B 轮融资中筹集了 60 亿美元(IT之家备注:当前约 435.6 亿元人民币),投资方包括 Andreessen Horowitz 和红杉资本等。xAI 表示,这笔资金将用于把 xAI 的首批产品推向市场、建设先进的基础设施并加速未来技术的研发。“未来几周将会有更多消息公布,xAI 的投前估值为 180 亿美元”马斯克在 X 上的一篇帖子中回应融资公告时表示。xAI 于 2023 年 7 月成立,去年 11 月推

世界最大开源 AI 社区 Hugging Face 将免费提供 1000 万美元共享 GPU,帮助小企业对抗大公司
世界最大的开源 AI 社区 Hugging Face(IT之家注:通称“抱抱脸”)日前宣布,将提供 1000 万美元的免费共享 GPU 帮助开发者创造新的 AI 技术。具体来看,Hugging Face 这次做出此举的目的是帮助小型开发者、研究人员和初创公司对抗大型 AI 公司,避免 AI 进步陷入“集中化”。Hugging Face 首席执行官 Clem Delangue 在接受 The Verge 采访时表示,对能够投资社区感到很幸运,此次之所以能够进行投资,是因为公司“已经盈利,或正走在盈利的路上”。前段时间
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉