在AI领域,参数规模曾被视为「性能天花板」。
Meta最新发布的KernelLLM,却用8B参数的「小身板」,在GPU内核生成任务中把200B的GPT-4o按在地上摩擦。
这是一个基于Llama 3.1 Instruct进行微调的8B参数模型,旨在将PyTorch模块自动转换为高效的Triton GPU内核。
 图片
图片
KernelLLM简直是GPU内核开发神器,用更少的参数实现了更强的性能,且简单易用。
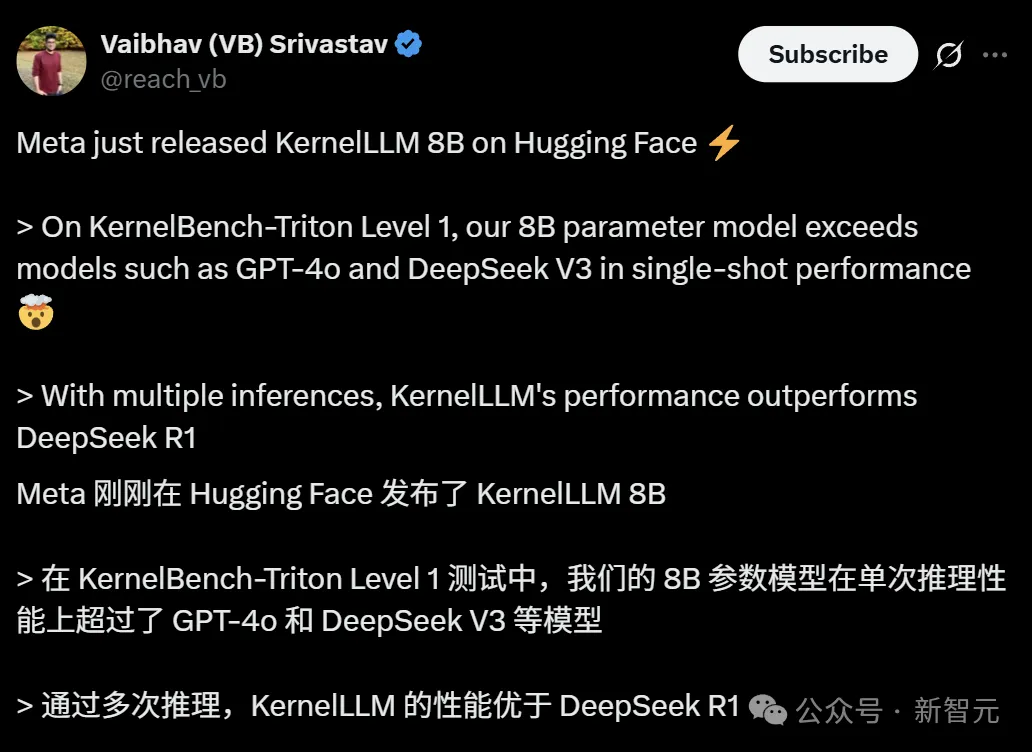
它只有8B参数,但是在KernelBench-Triton Level 1,单次推理性能超过了GPT-4o和DeepSeek V3。
通过多次推理,KernelLLM性能优于DeepSeek R1。
 图片
图片
这一切都来自一个参数规模比竞争对手小两个数量级的模型。
@Denis Kanonik吐槽「这又是用测试集训练的吗?」
 图片
图片
KernelLLM让内核开发更易上手
KernelLLM是一款基于Llama 3.1 Instruct的8B模型,专门针对用Triton编写GPU内核的任务进行了训练。
它能让GPU编程变得更简单,实现高性能GPU内核生成的自动化。
KernelLLM通过自动化生成高效的Triton实现,满足对高性能GPU内核日益增长的需求。
随着工作负载的增大和加速器架构的多样化,对定制化内核解决方案的需求显著增加。
现在市面上很多相关工具,要么只能在测试的时候优化,要么就只盯着KernelBench的问题调优,很难应对更广泛的场景。
KernelLLM是首个在外部(PyTorch,Triton)代码对数据上进行微调的LLM。
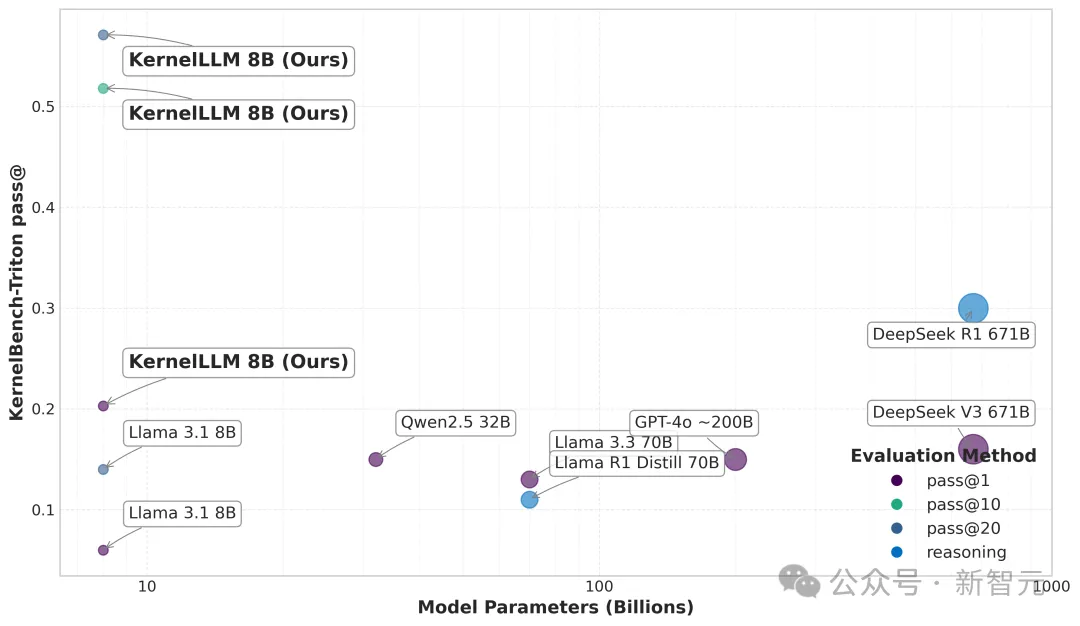
Triton内核生成工作流程
把PyTorch代码输进去,KernelLLM就会生成Triton内核候选代码。
然后用单元测试来验证这些代码,用随机输入跑一跑,看看输出对不对。要是生成好几个候选代码,还能比比哪个最好,挑出最优的。
 图片
图片
KernelLLM的Triton内核生成流程:用KernelLLM把PyTorch代码翻译成Triton内核的候选代码。生成的代码会通过单元测试验证,测试用已知形状的随机输入数据运行内核。这个流程支持生成多个候选代码(通过 pass@k评估),增加候选数量来提高质量,最后选出最好的Triton内核实现作为输出(绿色部分)
为了训练这个模型,团队可是下了大功夫,用了25000多对(PyTorch,Triton)代码示例,还有合成的样本。
这些数据一部分来自TheStack的过滤代码,一部分是通过torch.compile () 和提示技术生成的。
数据集KernelBook,参考链接:https://huggingface.co/datasets/GPUMODE/KernelBook。
训练时用的是Llama3.1-8B-Instruct模型,在自定义数据集上做了监督微调(SFT),测试它在KernelBench-Triton上生成正确Triton内核及调用代码的能力。
KernelBench-Triton是基于KernelBench[Ouyang et al. 2025]开发的变体,专注Triton内核生成。
训练和评估时,PyTorch代码会配置一个包含格式示例的提示模板作为指令。
模型训练了10个epoch,批大小为32,采用标准SFT方法,超参数根据验证集的困惑度(perplexity)来选择。
训练用了16个GPU,共耗时12小时(192 GPU小时),报告了最佳检查点的验证结果。
性能评估
尽管模型规模较小,但其性能可与最先进的LLM相媲美。
 图片
图片
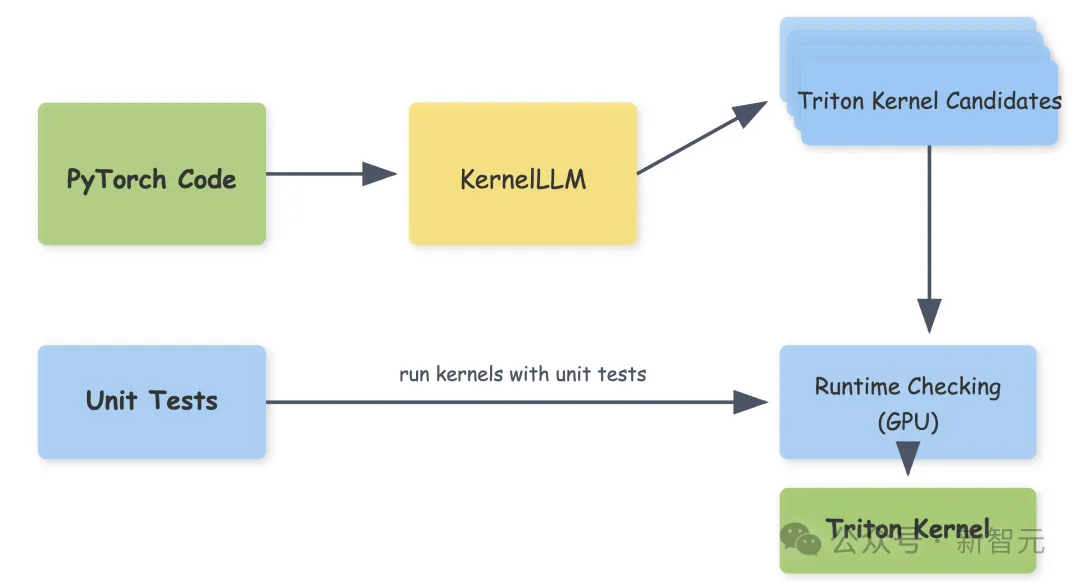
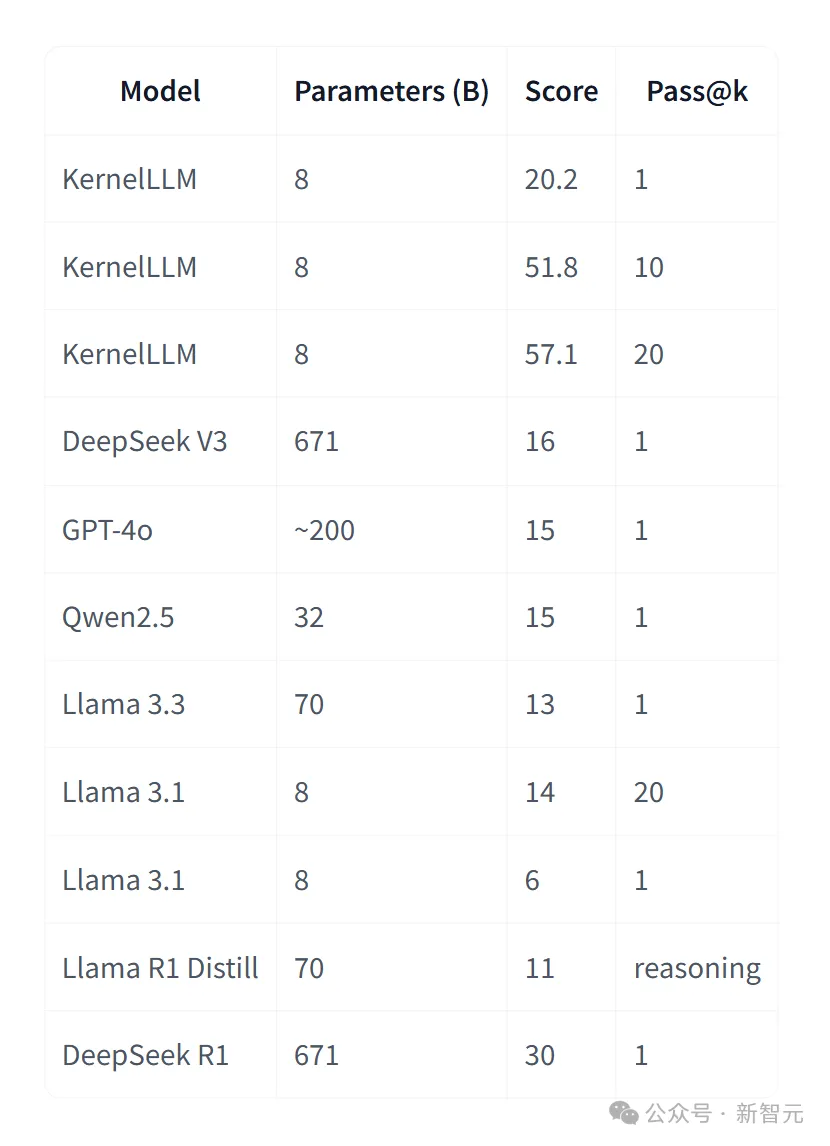
KernelBench-Triton测试中,8B参数的KernelLLM,单次推理得分20.2,比671B参数的DeepSeek V3(16分)和200B参数的GPT-4o(15分)都高。
 图片
图片
要是多生成几个候选代码,得分还能蹭蹭往上涨,生成10个的时候能到51.8分,20个的时候能到57.1分。
KernelLLM推理用temperature=1.0和top_p=0.97运行。
在KernelBench上测试了模型,这是一个开源基准测试,用于评估LLM编写的高效GPU内核的能力。
它包含250个精心挑选的PyTorch模块,按负载调整,从简单的单操作(如Conv2D或Swish,Level 1)到完整的模型架构(Level 3)。
它在不同难度的任务里表现都很稳,不管是简单的单个操作符,还是复杂的模型架构,都能应对。
测试会同时降低代码的正确性(通过与参考PyTorch输出对比)和性能(通过与基准实现的加速比)。
团队开发了一个新的KernelBench-Triton变体,专门评估LLM生成Triton内核的能力,非常适合测试KernelLLM。
所有测试都在NVIDIA H100 GPU上完成。
 图片
图片
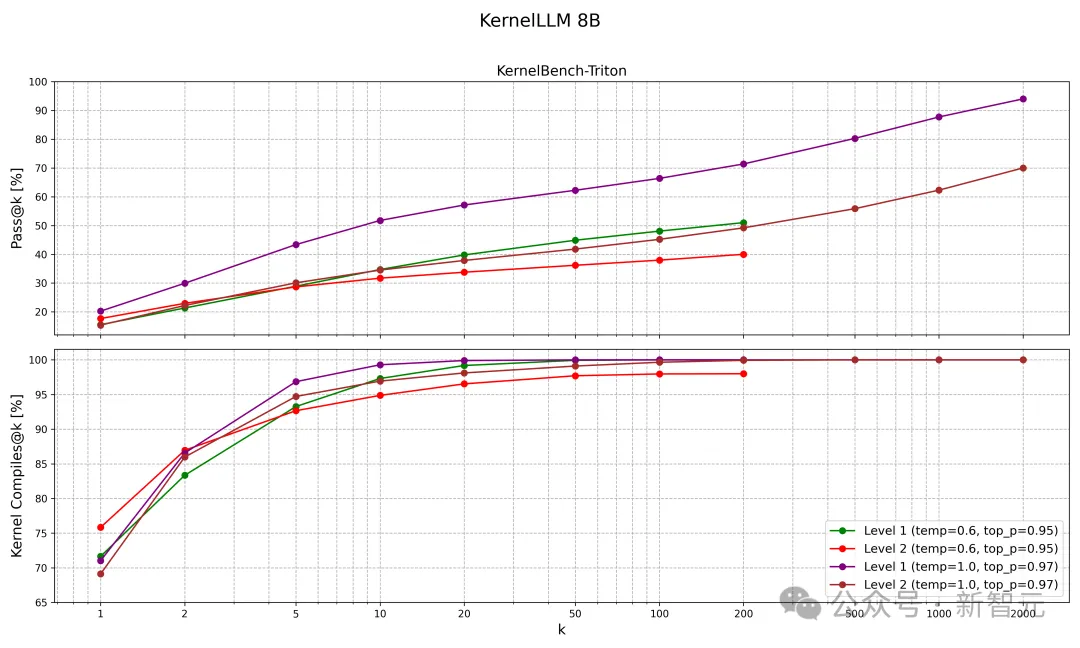
KernelLLM在pass@k中表现出近似对数线性的扩展行为
KernelLLM怎么用?
先装几个依赖包:
复制pip install transformers accelerate torch triton pip install transformers accelerate torch triton
用的时候,先导入库,调用generate_triton函数,就能生成优化后的Triton代码啦。
KernelLLM提供了一个简单的接口,用于从PyTorch代码生成Triton核。
复制from kernelllm import KernelLLM# Initialize the modelmodel = KernelLLM()# Define your PyTorch modulepytorch_code = '''import torchimport torch.nn as nnclass Model(nn.Module): """ A model that computes Hinge Loss for binary classification tasks. """ def __init__(self): super(Model, self).__init__() def forward(self, predictions, targets): return torch.mean(torch.clamp(1 - predictions * targets, min=0))batch_size = 128input_shape = (1,)def get_inputs(): return [torch.randn(batch_size, *input_shape), torch.randint(0, 2, (batch_size, 1)).float() * 2 - 1]def get_init_inputs(): return []'''# Generate optimized Triton codeoptimized_code = model.generate_triton(pytorch_code, max_new_tokens=512)print(optimized_code)
from kernelllm import KernelLLM
# Initialize the model
model = KernelLLM()
# Define your PyTorch module
pytorch_code =
'''
import torch
import torch.nn as nnclass Model(nn.Module):
"""
A model that computes Hinge Loss for binary classification tasks.
"""
def __init__(self):
super(Model, self).__init__()
def forward(self, predictions, targets):
return torch.mean(torch.clamp(1 - predictions * targets, min=0))
batch_size = 128
input_shape = (1,)
def get_inputs():
return [torch.randn(batch_size, *input_shape), torch.randint(0, 2, (batch_size, 1)).float() * 2 - 1]
def get_init_inputs():
return []
'''
# Generate optimized Triton code
optimized_code = model.generate_triton(pytorch_code, max_new_tokens=512)
print(optimized_code)要是不想写脚本,还能直接运行python kernelllm.py,使用内置的REPL接口,打开交互式界面,实时看结果。
kernelllm.py提供了多种与模型交互的方法。
复制python kernelllm.py python kernelllm.py
KernelLLM提供了几种自定义生成过程的方法:
复制from kernelllm import KernelLLMmodel = KernelLLM()# Stream output in real-timemodel.stream_raw("Your prompt here", max_new_tokens=2048)# Generate raw text without the Triton-specific prompt templateraw_output = model.generate_raw("Your prompt here", temperature=1.0, max_new_tokens=2048)
from kernelllm import KernelLLM
model = KernelLLM()
# Stream output in real-time
model.stream_raw("Your prompt here", max_new_tokens=2048)
# Generate raw text without the Triton-specific prompt template
raw_output = model.generate_raw("Your prompt here", temperature=1.0, max_new_tokens=2048)有时它会犯点小错误,比如API引用不对、语法出错,有时候还不太能按指令生成理想的内核。
生成的代码结构有点像编译器自动吐出来的,有时在变量命名、张量形状、类型处理和数值精度这些细节上也容易出问题。
参考资料:
https://x.com/reach_vb/status/1924478755898085552
https://huggingface.co/facebook/KernelLLM


