
译者 | 李睿
审校 | 重楼
本文介绍如何从零开始构建Zepto的多语言查询解析系统,该系统利用LLM与RAG技术处理拼写错误及方言查询问题。通过复制从模糊查询到修正输出的端到端流程,可以解释这一技术在提升搜索质量与多语言查询处理中的核心作用。
你用过Zepto在网上订购杂货吗?如果用过,你可能会注意到,即使写错单词或拼错商品名称,Zepto仍然能理解并显示想要的结果。但是,输入“kele chips”(香蕉片)而不是“banana chips”(香蕉片)的用户则很难找到他们想要的商品。拼写错误和方言查询导致糟糕的用户体验并降低转化率。
Zepto公司的数据科学团队利用LLM和RAG构建了一个强大的系统来解决多语言拼写错误问题。本文将从模糊查询到修正输出,完整复制这一端到端功能,并解释了该技术在搜索质量和多语言查询解析中发挥的关键作用。
了解Zepto的系统
技术流程
以下了解Zepto用于其多语言查询解析的技术流程。该流程涉及多个组件,将在后续详细说明。
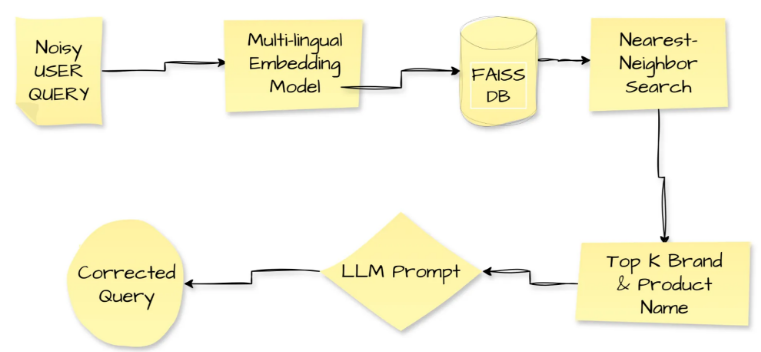
图1多语言查询解析工作流程
图1追踪了一个嘈杂的用户查询的完整修正过程。拼写错误或方言文本进入管道;多语言嵌入模型将其转换为密集向量。该系统将该向量输入Facebook的相似性搜索引擎FAISS,该引擎返回嵌入空间中最接近的top-k个品牌和产品名称。接下来,管道将嘈杂的查询和检索到的名称转发到LLM提示,LLM输出经过修正、干净的查询。Zepto部署了这个查询解析循环来提升用户体验和转化率。Zepto在处理拼写错误、代码混合短语和方言词汇时,根据Zepto的调查,受影响查询的转化率提高了7.5%,这清楚地展示了技术提升日常互动的能力。
核心组件
以下介绍在这个系统中使用的核心概念。
1.拼写错误的查询和方言查询
用户经常在查询中使用英语和方言的混合。例如,“kele chips”(“香蕉片”),“balekayi chips”(卡纳达语)等。例如“kothimbir”(马拉地语/印地语的香菜)或泰米尔语中“paal”(牛奶)的语音输入会导致传统搜索失效。如果没有规范化或音译支持,其语义就会丢失。
2.检索-增强生成(RAG)
RAG是一个将语义检索(向量嵌入和元数据查找)与LLM生成功能相结合的管道。Zepto在收到嘈杂、拼写错误和方言查询时,利用RAG功能检索top-k个相关的产品名称和品牌。然后,将这些最相似的检索到的结果与嘈杂的查询一起被馈送到LLM进行修正。
在Zepto的用例中使用RAG的好处:
- 通过提供上下文来防止幻觉,从而为LLM的应用奠定基础。
- 提高准确性并确保相关品牌术语的修正。
- 通过缩小上下文减少提示大小和推理成本。
3.向量数据库
向量数据库是一种专门用于存储、索引单词或句子嵌入的数据库。这些嵌入是数据点的数字表示。这些向量数据库用于在给定查询时使用相似度搜索检索高维向量。FAISS是一种开源库,专门为高效的相似度搜索和密集向量聚类而设计。FAISS用于快速搜索多媒体文档的相似嵌入,Zepto系统可以使用FAISS来存储品牌名称、标签和产品名称的嵌入。
4.逐步提示和JSON输出
Zepto的流程强调模块化的提示分解,可以将复杂的任务分解成更小的逐步任务,然后有效地执行,而不会出现任何错误,从而提高准确性。它包括检测查询是否拼写错误或方言,修正术语,翻译成英语规范术语,并以JSON格式输出。
JSON模式确保了可靠性和可读性,例如:
复制其系统提示包含几个简短的例子,其中包含英语和修正方言的混合,以指导LLM的行为。
5.内部LLM托管
Zepto使用Meta的Llama3-8B,托管在Databricks上以控制成本和提供性能。Zepto采用指令微调,这是一种使用逐步提示和角色扮演指令的轻量级调优。确保LLM仅关注提示行为,避免成本昂贵的模型重新训练。
6.通过用户重新表述的隐式反馈
当推出新功能的时候,用户反馈至关重要。Zepto用户看到的每次快速修正和更好的结果都是有效的修复。收集这些信号以向提示添加新的示例,将新的同义词放入检索数据库,并清除错误。Zepto的A/B测试显示转化率提升了7.5%。
复制查询解析系统
接下来,将尝试通过定义系统来复制Zepto的多语言查询解析系统。以下是将要使用的系统流程图。
其实现遵循Zepto概述的相同策略:
- 语义检索:首先获取用户的原始查询,并从整个目录中找到top-k个潜在相关产品的列表。这是通过将查询的向量嵌入与存储在向量数据库中的产品的嵌入进行比较来实现的。这一步骤提供了必要的上下文。
- LLM支持的校正和选择:LLM驱动的修正与选择:将检索到的产品(上下文)和原始查询传递给LLM。LLM的任务不仅是修正拼写,还需分析上下文并选择用户最可能想要查找的产品。然后,它以结构化格式返回一个干净的、经过修正的查询以及其决策背后的推理。
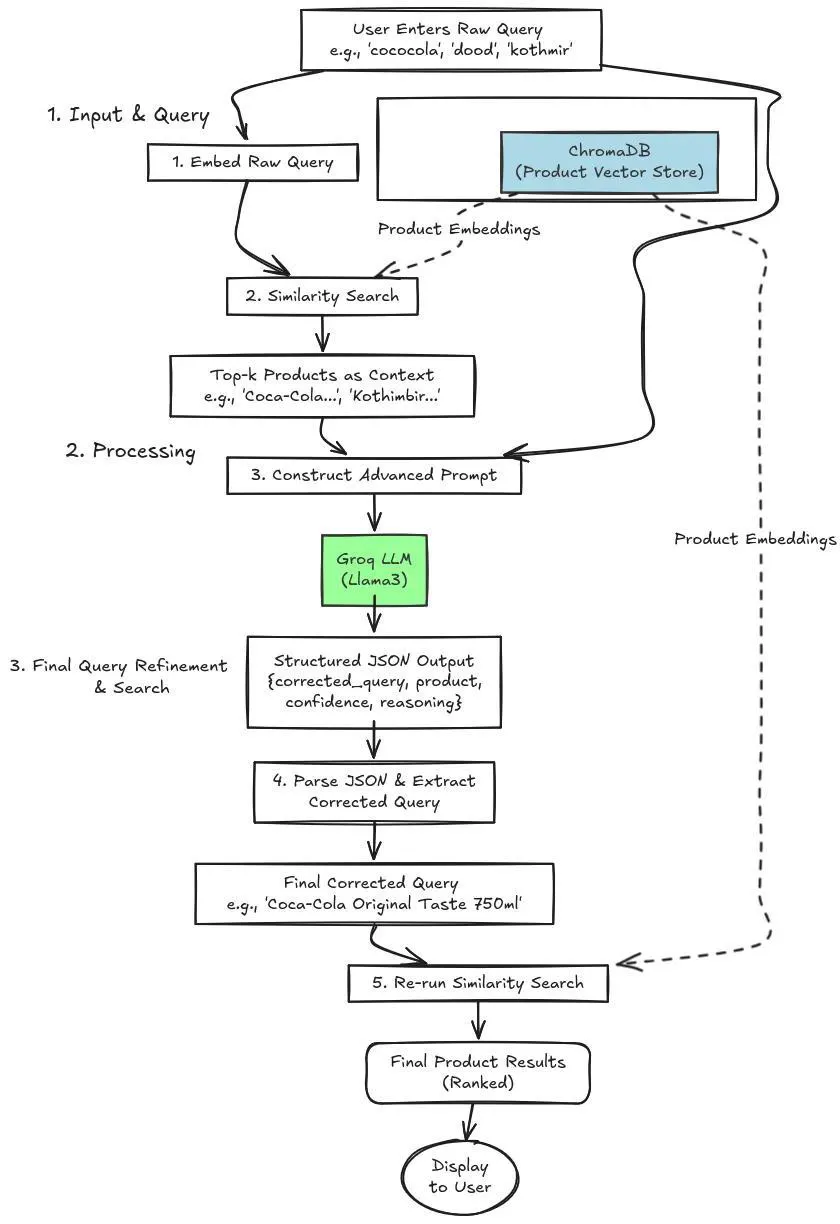
图2 系统流程图
流程
该流程可以简化为以下3个步骤:
1.输入和查询
用户输入原始查询,该查询可能包含一些噪声或使用不同的语言。Zepto系统直接将原始查询嵌入到多语言嵌入中。在具有一些预定义嵌入的Chroma DB向量数据库上执行相似性搜索。它返回top-k个最相关的产品嵌入。
2.处理
检索到top-k产品嵌入之后,通过高级系统提示将它们与嘈杂的用户查询一起提供给Llama3。该模型返回一个清晰的JSON,其中包含清理后的查询、产品名称、置信度评分及其推理过程,明确说明选择该品牌的原因。确保查询修正的透明性,可访问LLM选择该产品和品牌名称的推理逻辑。
3.最终查询细化和搜索
这个阶段包括解析来自LLM的JSON输出,通过提取修正之后的查询,可以根据用户输入的原始查询访问最相关的产品或品牌名称。最后一个阶段涉及在Vector DB上重新运行相似性搜索,以查找搜索产品的详细信息。这样,就可以实现多语言查询解析系统。
动手实施
在了解查询解析系统的工作原理之后,现在通过编写代码动手构建这个系统。将逐步完成每一个事项,从安装依赖项到最终的相似性搜索。
步骤1:安装依赖项
首先,安装必要的Python库。将使用LangChain协调组件,使用langchain-groq实现快速LLM推理,fastembed用于高效生成嵌入,langchain-chroma用于管理向量数据库,pandas用于处理数据。
复制步骤2:创建一个扩展和复杂的虚拟数据集
为了彻底测试系统,需要一个反映现实世界挑战的数据集。这个CSV包括:
- 更多种类的产品(20多种)
- 常见的品牌名称(如可口可乐、美极)
- 多语言和方言术语(dhaniya、kanda、nimbu)
- 潜在歧义项(cheese spread、cheese slices)。
输出:
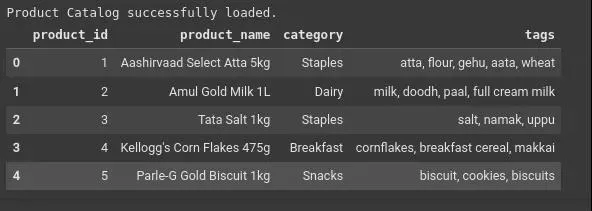
图3输出表格
步骤3:初始化向量数据库
将产品数据转换成捕获语义的数值表示(嵌入)。这里使用FastEmbed,因为它速度很快并且在本地运行。将这些嵌入存储在轻量级的向量数据库ChromaDB中。
- 嵌入策略:为每个产品创建组合产品名称、类别和标签的文本文档,生成丰富的描述性嵌入,这样可以提高语义匹配成功率。
- 嵌入模型:在这里使用BAAI/ big -small-en-v1.5模型。其“小型”版本资源高效且快速,是适合多语言任务的嵌入模型。BAAI/ big -small-en-v1.5是一个强大的英文文本嵌入模型,在某些上下文中很有用。它在涉及语义相似性和文本检索的任务中提供了具有竞争力的性能。
输出:
图4向量数据库初始化
如果看到这个小部件,那就意味着可以在本地下载BAAI/ big -small-en-v1.5。
步骤4:设计高级LLM的提示
这是最关键的一步。这里设计了一个提示,指示LLM充当专家查询解释器。该提示强制LLM遵循严格的流程来返回结构化JSON对象。这确保了输出是可预测的,并且易于在应用程序中使用。
提示的主要功能:
- 明确的角色:LLM被告知这是一个杂货店专家系统。
- 上下文是关键:它必须基于检索产品列表做出决策。
- 强制JSON输出:指示它返回具有特定模式的JSON对象:corrected_query, identified_product、confidence和reasoning。这对系统可靠性至关重要。
步骤5:创建端到端管道
现在使用LangChain表达式语言(LCEL)将所有组件链接在一起。这创建了从查询到最终结果的流畅流程。
管道流程:
- 用户的查询被传递给检索器以获取上下文。
- 对上下文和原始查询进行格式化并输入到提示中。
- 格式化的提示发送到LLM。
- LLM的JSON输出被解析成Python字典。
步骤6:演示和结果
现在,使用各种具有挑战性的查询来测试系统以了解其性能。
复制输出:
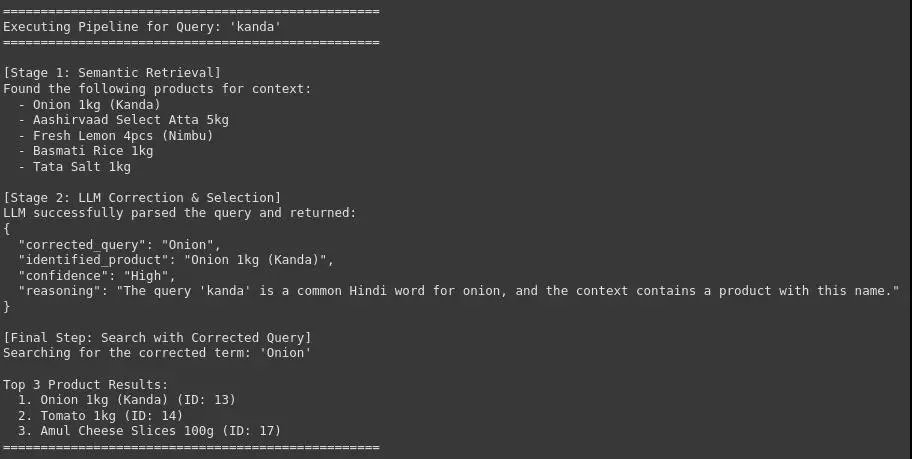
图5 查询管道:Kanda
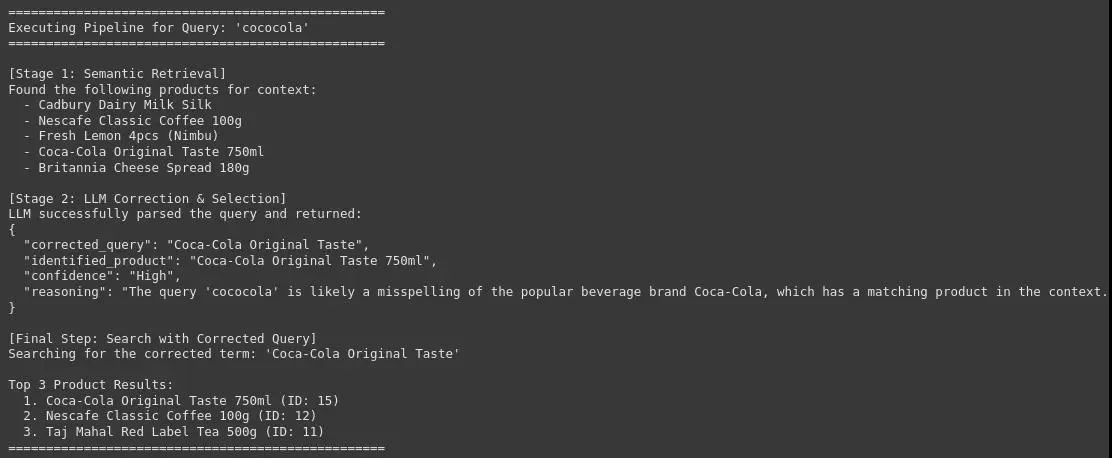
图6查询管道:cococola
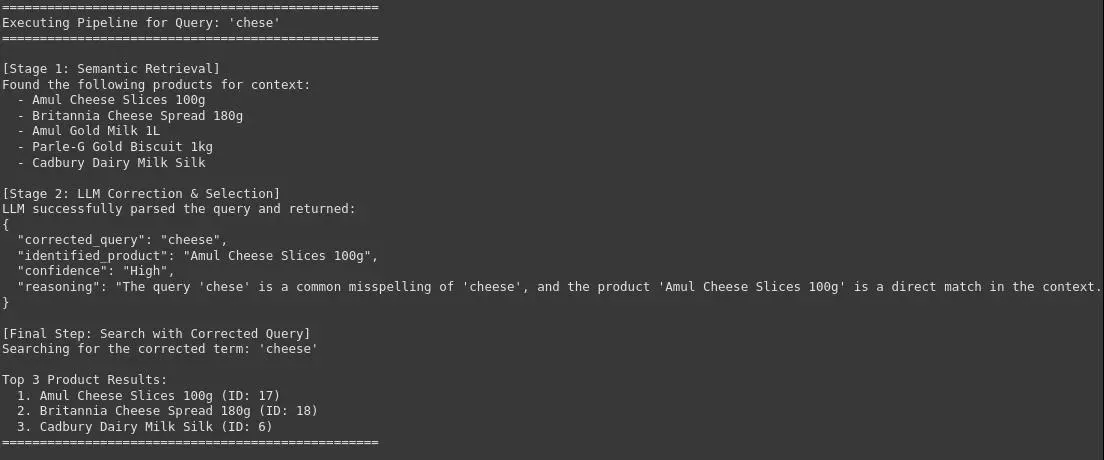
图7查询管道:Chese
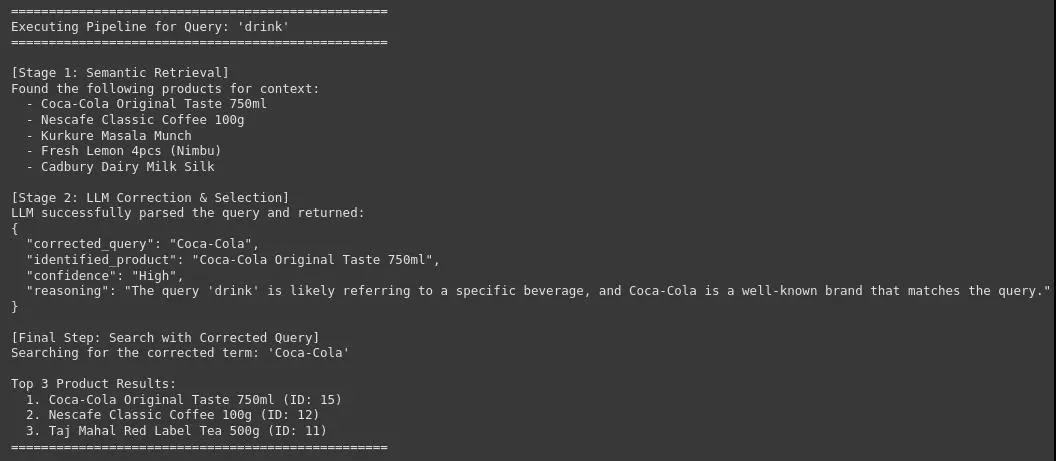
图8查询管道:Girnk
可以看到,该系统可以用准确和正确的品牌或产品名称来修正原始和嘈杂的用户查询,这对于在电子商务平台上实现高精度的产品搜索至关重要。这将改善用户体验并提高转化率。
注:在这个Git存储库中可以找到完整的代码。
结论
这个多语言查询解析系统成功地复制了Zepto高级搜索系统的核心策略。通过将快速语义检索与基于LLM的智能分析相结合,该系统可以:
- 准确地修正拼写错误和俚语。
- 理解多语言查询并匹配正确产品。
- 通过使用检索到的上下文推断用户意图来消除查询的歧义(例如,在“奶酪片”和“奶酪酱”之间进行选择)。
- 提供结构化的,可审计的输出,展示修正及推理过程。
这种基于RAG的架构是稳健的、可扩展的,并展示了显著改善用户体验和搜索转化率的清晰路径。
常见问题
Q1:什么是RAG,为什么在这里使用它?
答:RAG通过将其锚定到真实的目录数据来提高LLM的准确性,避免幻觉并减少提示规模。
Q2:如何防止品牌名称修正错误?
答:在检索步骤中只注入最相关的品牌术语,避免扩大提示的规模。
Q3:应该使用什么嵌入模型?
答:多语言句子转换器模型(例如BAAI/ big -small-en-v1.5)针对语义相似性进行了优化,最适合嘈杂和方言输入。原文标题:How to Replicate Zepto’s Multilingual Query Resolution System from Scratch?,作者:Harsh Mishr


