
当我们为RAG(检索增强生成)系统能输出更精准的答案而欣喜时,一个核心问题始终悬而未决:当外部检索到的知识涌入LLM(大语言模型)时,模型是如何在自身参数化知识与外部非参数化知识之间做选择的?是优先采信新信息,还是固守旧认知?
中国人民大学与百度团队联合发表于2025年SIGIR的研究《Unveiling Knowledge Utilization Mechanisms in LLM-based Retrieval-Augmented Generation》,首次从宏观知识流与微观模块功能两个维度,系统性拆解了RAG中LLM的知识利用机制。这项研究不仅让我们看清了知识在模型内部的“流动轨迹”,更提出了可量化、可调控的技术方法,为打造更可控、低幻觉的RAG系统提供了底层支撑。
论文地址:https://arxiv.org/pdf/2505.11995
01、研究动机:RAG的“好用”与“未知”的矛盾
RAG技术的崛起,本质上是为了解决LLM的“知识困境”——模型训练完成后,参数中固化的“内部知识”难以覆盖实时动态信息或专业领域细节,容易产生事实性错误(幻觉)。通过引入检索模块补充“外部知识”,RAG成功扩展了模型的知识边界,在开放域问答、智能客服等场景中大放异彩。
但光鲜的性能背后,RAG系统实则是个“半黑箱”:
- 外部知识进入模型后,经历了怎样的处理流程?
- 检索段落的相关性究竟如何影响模型的决策倾向?
- 模型内部的MHA(多头注意力)和MLP(多层感知器)模块,在知识整合中分别扮演什么角色?
现有研究虽能通过调整检索策略、优化上下文格式提升RAG性能,却始终未能触及“知识如何被利用”的核心机制。正是这一研究缺口,推动团队开展了这场对RAG内部运作逻辑的“解剖式探索”。
02、核心定义:先分清两种“知识源”
在深入解析前,我们需明确RAG中两类关键知识的本质差异,这是后续分析的基础:
- 内部知识(IK):LLM在预训练阶段沉淀于参数中的知识,无需外部输入即可调用。生成过程可表示为:
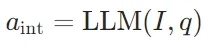 ,其中 I 为指令, q 为查询,
,其中 I 为指令, q 为查询,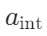 为仅依赖内部知识的答案。
为仅依赖内部知识的答案。 - 外部知识(EK):推理阶段通过检索器从外部语料库获取的上下文信息,生成过程需引入检索段落
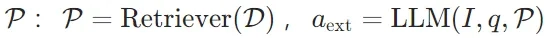 ,其中为融合外部知识的答案。
,其中为融合外部知识的答案。
研究正是围绕这两类知识的“交互与博弈”展开,聚焦开放域问答(ODQA)任务,选用LLaMA、Qwen两大开源模型家族,在Natural Questions、TriviaQA、HotpotQA三大基准数据集上开展实验,并特意构造“假段落”(替换真实答案的错误文本)验证模型的知识选择偏好。
03、宏观视角:知识在RAG中的4个流动阶段
团队创新性地采用“信息流分析”方法,通过追踪注意力分数与梯度变化,首次将RAG中的知识利用过程划分为四个清晰的阶段,完整呈现了外部知识从“输入”到“输出”的全生命周期。
信息流分析的两大工具
为精准捕捉知识流动,研究设计了两种互补的分析方法:
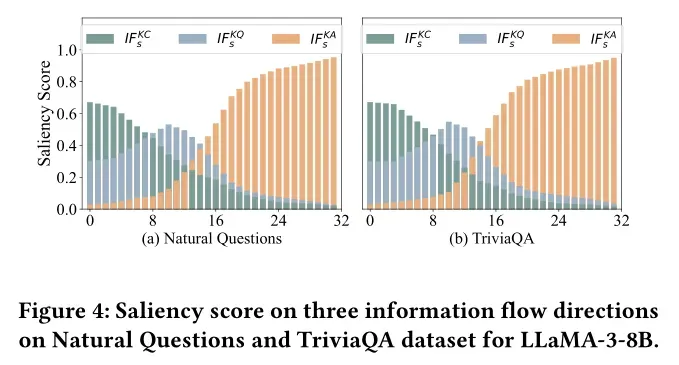
- 基于注意力的信息流:通过量化关键token(K,潜在答案)与上下文token(C,检索段落)、查询token(Q,用户问题)、答案token(A,生成结果)之间的注意力交互,定义了三个核心指标:
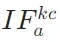 (关键到上下文)、
(关键到上下文)、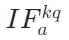 (关键到查询)、
(关键到查询)、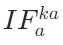 (关键到答案),公式如下:
(关键到答案),公式如下: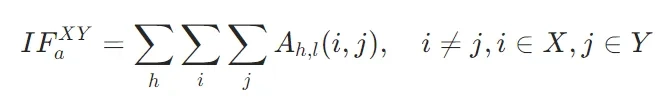
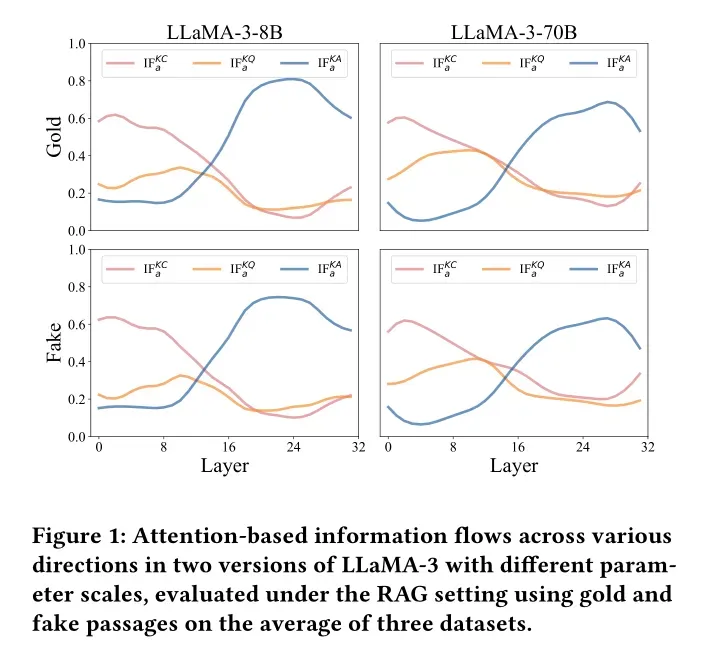
- 基于显著性的信息流:结合监督微调损失的梯度信息,衡量每个token对最终预测的边际贡献,弥补了注意力分析仅关注表层交互的局限,得到更全面的
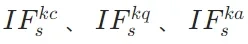 指标。
指标。
知识流动的四阶段模型
两种分析方法的结果高度一致,共同揭示了知识在LLM不同层级间的动态变化规律,最终形成“四阶段模型”:
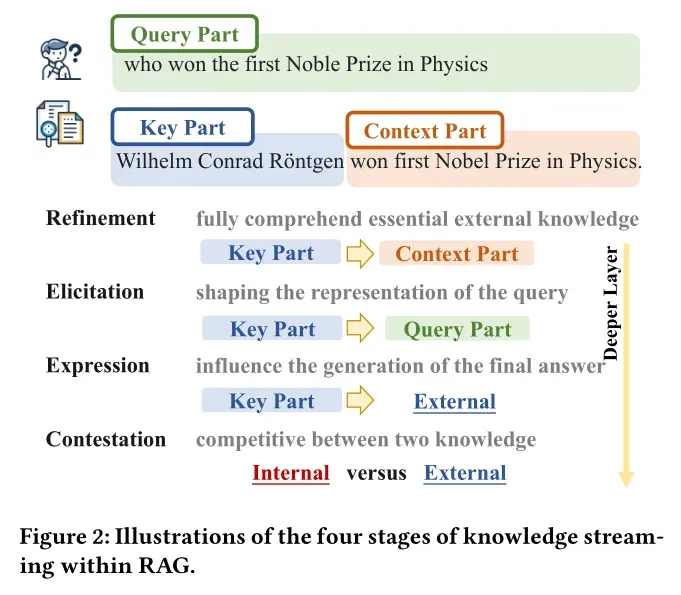
1. 知识精炼阶段(早期层级)
此阶段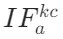 (关键到上下文)指标达到峰值,表明模型正集中精力对检索到的外部知识进行“筛选与提炼”。就像我们拿到一份参考资料时,首先会快速抓取核心信息,这一阶段完成了外部知识的初步“消化”,上下文信息逐渐趋于稳定。
(关键到上下文)指标达到峰值,表明模型正集中精力对检索到的外部知识进行“筛选与提炼”。就像我们拿到一份参考资料时,首先会快速抓取核心信息,这一阶段完成了外部知识的初步“消化”,上下文信息逐渐趋于稳定。
2. 知识激发阶段(中间层级)
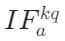 (关键到查询)指标在此阶段达到顶峰,意味着精炼后的外部知识开始与用户问题深度融合,帮助模型重新理解查询意图。例如,当被问“2025年世界杯冠军是谁”时,检索到的“阿根廷队夺冠”信息会在此阶段修正模型对“2025年赛事结果”的认知,是外部知识向模型内部传递的关键环节。
(关键到查询)指标在此阶段达到顶峰,意味着精炼后的外部知识开始与用户问题深度融合,帮助模型重新理解查询意图。例如,当被问“2025年世界杯冠军是谁”时,检索到的“阿根廷队夺冠”信息会在此阶段修正模型对“2025年赛事结果”的认知,是外部知识向模型内部传递的关键环节。
3. 知识表达阶段(中后层级)
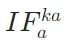 (关键到答案)指标显著上升,说明模型开始将整合后的知识转化为具体的答案内容。此时外部知识对生成结果的影响力最强,若检索段落准确,答案的事实性将得到有效保障。
(关键到答案)指标显著上升,说明模型开始将整合后的知识转化为具体的答案内容。此时外部知识对生成结果的影响力最强,若检索段落准确,答案的事实性将得到有效保障。
4. 知识竞争阶段(深层级)
在模型最深处,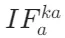 指标逐渐下降,而显著性分析显示外部知识的“隐性影响”仍在持续。这种差异表明,内部知识与外部知识在此阶段展开最终博弈,模型需权衡两种知识的可靠性,最终确定输出内容。
指标逐渐下降,而显著性分析显示外部知识的“隐性影响”仍在持续。这种差异表明,内部知识与外部知识在此阶段展开最终博弈,模型需权衡两种知识的可靠性,最终确定输出内容。
值得注意的是,即使外部知识与内部知识存在冲突(如假段落场景),这四个阶段的流动模式依然稳定,说明知识处理的“框架”是LLM的固有特性。
相关性的“指挥棒”作用
检索段落的相关性如何影响知识流动?研究通过对比“正例段落(含正确答案)、困难负例(相关无答案)、易负例(弱相关)、随机段落(无关)”四类数据发现:
- 无论相关性高低,知识流动的四阶段模式始终存在,但信息流强度随相关性降低而显著减弱——无关段落难以引发模型对外部知识的深度利用。
- 相关性的影响集中体现在知识激发阶段:正例段落在此阶段的
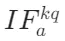 指标远高于其他类型,表明模型会在这一环节主动判别外部知识的价值,优先整合高相关性信息。
指标远高于其他类型,表明模型会在这一环节主动判别外部知识的价值,优先整合高相关性信息。
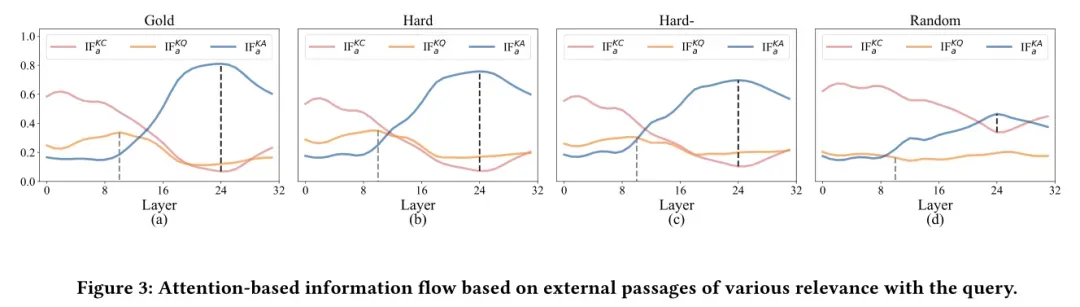
进一步实验证实,若在知识激发阶段切断关键token与查询token的交互,高相关性段落对答案的影响会急剧下降,这直接证明了该阶段是模型进行“相关性判断与知识筛选”的核心关口。
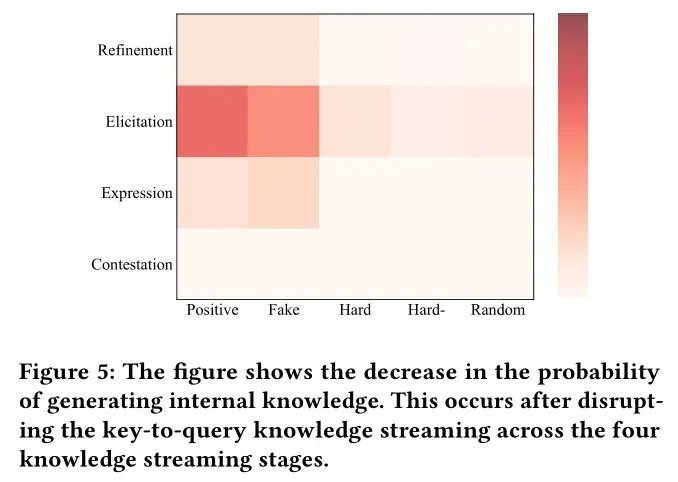
04、微观视角:神经元与模块的“分工密码”
如果说知识流是“宏观轨迹”,那么模型内部的神经元与功能模块就是实现这一轨迹的“微观单元”。研究通过拆解LLM的核心组件,揭开了知识利用的底层分工逻辑。
知识特异性神经元:可调控的“知识开关”
模型中是否存在专门负责处理内部或外部知识的神经元?团队提出KAPE(知识激活概率熵) 指标,成功识别出这类“知识特异性神经元”。
KAPE的工作原理
- 神经元激活量化:基于LLM中MLP层的GLU(门控线性单元)机制,计算每个神经元在处理内部知识与外部知识时的激活概率
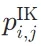 和
和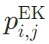 。
。 - 熵值计算:通过熵值衡量神经元的知识偏好,公式为:
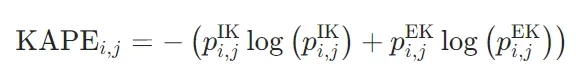
低KAPE值意味着神经元对某类知识有显著偏好(如仅对外部知识激活),即“知识特异性神经元”。
神经元调控的神奇效果
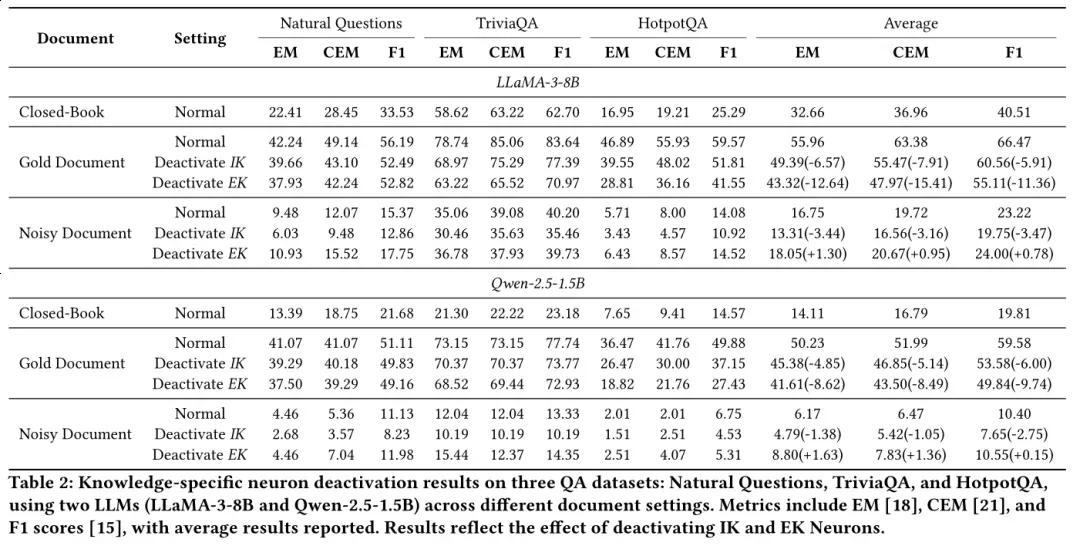
通过选择性停用这些特异性神经元,模型的知识依赖偏好可被精准调控:
- 当使用含正确答案的黄金文档时,停用外部知识神经元会导致答案准确性大幅下降,说明此时模型高度依赖外部信息;
- 当使用含错误答案的噪声文档时,停用外部知识神经元能有效过滤误导信息,提升输出质量;
- 这种调控效果在LLaMA、Qwen等不同模型家族,以及单跳、多跳等不同任务中均保持一致,证明了方法的通用性。
一个典型案例显示:当检索段落包含错误答案时,模型最初会被误导;但停用外部知识特异性神经元后,模型立即转向依赖内部知识,输出了正确结果。反之,当外部知识正确但模型未充分利用时,停用内部知识神经元可强制模型采信外部信息。

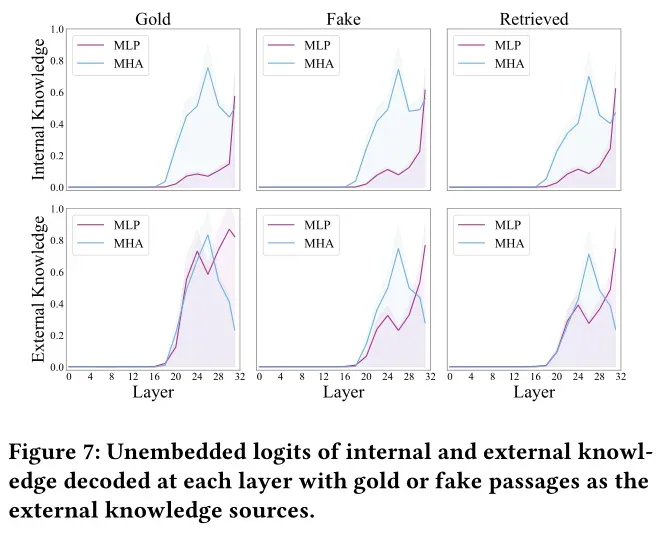
MHA与MLP的“互补分工”
Transformer架构中的两大核心模块在知识利用中扮演着截然不同的角色,研究通过残差流分析与早期解码技术揭开了它们的分工:
- MHA(多头注意力)模块:专注于“知识整合”。它负责将外部知识、查询意图、内部记忆中的相关信息进行跨源融合,为答案生成构建统一的上下文基础,类似“信息调度中心”;
- MLP(多层感知器)模块:专注于“知识验证”。它对知识的准确性极为敏感——当检索到黄金文档时,MLP模块对答案生成的贡献显著增强;当遇到虚假文档时,其贡献则明显下降,相当于“事实审核员”。
这一发现解释了为何部分RAG系统会整合错误信息:若MLP模块功能弱化,模型就难以甄别外部知识的真伪,只能被动依赖MHA整合的信息。
05、总结:RAG技术的“可控化”新起点
人大与百度的这项研究,不仅是对RAG机制的“解剖报告”,更是推动RAG从“经验驱动”走向“原理驱动”的关键一步。其核心贡献可概括为三点:
- 宏观建模:首次明确RAG中知识利用的四阶段流程(精炼→激发→表达→竞争),并锁定知识激发阶段为相关性影响的核心环节;
- 微观突破:提出KAPE指标实现知识特异性神经元的精准识别,为调控模型知识依赖提供了“开关级”工具;
- 模块解码:厘清MHA与MLP的互补作用,为针对性优化模型结构、提升事实准确性指明了方向。
对于产业界而言,这些发现的价值尤为深远:未来的RAG系统可通过以下方式实现升级:
- 优化知识激发阶段的上下文设计,强化高相关性信息的引导作用;
- 基于KAPE指标筛选神经元,在金融、医疗等关键领域定向增强模型对权威外部知识的依赖;
- 针对性强化MLP模块功能,提升模型对噪声知识的“免疫力”。
从“知其然”到“知其所以然”,这项研究让我们离可控、可靠的AI系统又近了一步。当RAG的“黑箱”被逐层揭开,那些曾困扰我们的幻觉、不可控等问题,终将在原理性突破中找到答案。


