
RAGFlow 在 8 月 4 号更新了 v0.20 版本,这是时隔两个多月之后,更新的一个里程碑式的版本,RAGFlow 在 Agent 板块的拼图这次终于算是完整了。其实早在一年前,RAGFlow 就有了 Agent 模块,但是一直只包含 Workflow。而且相比于 Dify 而言,社群对这部分的工具/插件的丰富度、易用性和 UI 美观度而言,一直也有吐槽。

过去大半年,市场上也出现了很多 RAGFlow 知识库+Dify 工作流的各种混合用法。这也说明了从产品定位上来说,RAGFlow 更偏向于一个专业的 RAG 引擎。而 Dify 则把工作流编排作为核心竞争力之一,投入了更多资源在易用性和社区建设上。不过随着 RAGFlow 在企业级应用中的不断深入,或许会催生出更多标准化的集成需求,从而为其工作流插件生态的发展带来新的可能性。
言归正传,这篇试图说清楚:
这篇来做个 text2sql 的简单 RAGFlow agent 的案例演示,顺便介绍下这次的主要 Agent 更新特性。选题是来自官方公众号一周前发布的一篇关于 SQL Assistant 的 demo 基础上,优化了数据样例和测试问题,但出现了增加了验证与自修复环节的报错,最后也会对比下在 Dify 上实现效果。
以下,enjoy:
1、版本升级参考
为了方便不熟悉版本升级的盆友操作,这里再简要介绍下相关操作。由于数据卷是独立于容器的,新的容器会重新挂载已存在的数据卷,从而保留历史项目文件。
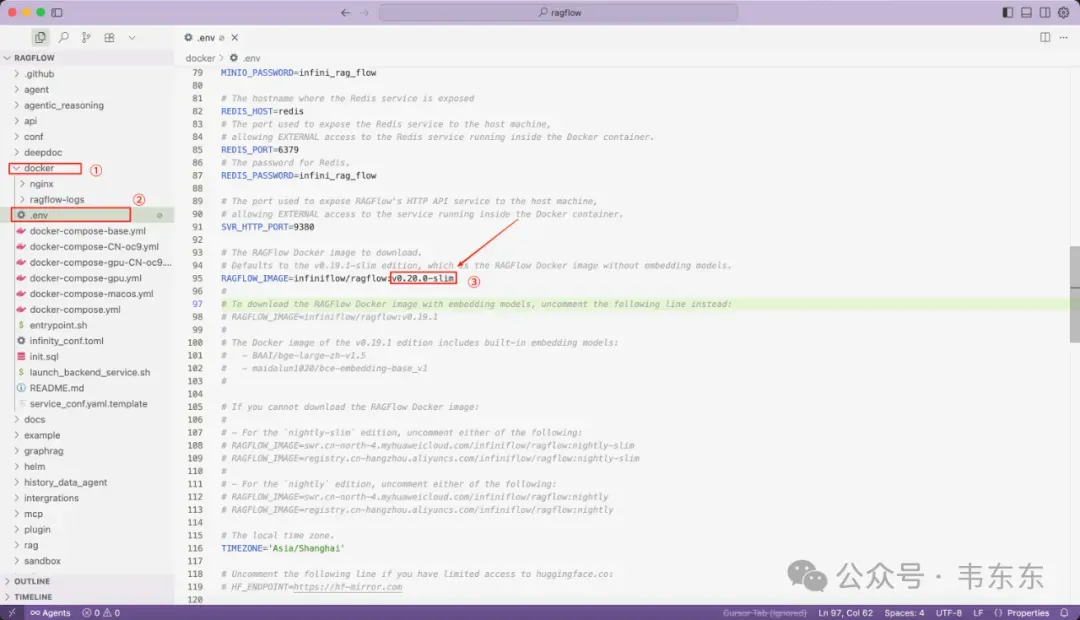
所以为了升级 v0.20(或者最新的 0.21),不需要重新部署。修改 ragflow/docker/.env 文件,更新 RAGFLOW_IMAGE 变量为你想要升级到的版本号。然后运行下述 Docker 命令会拉取 .env 文件中指定的新版本镜像,并使用新的镜像重新创建和启动容器。
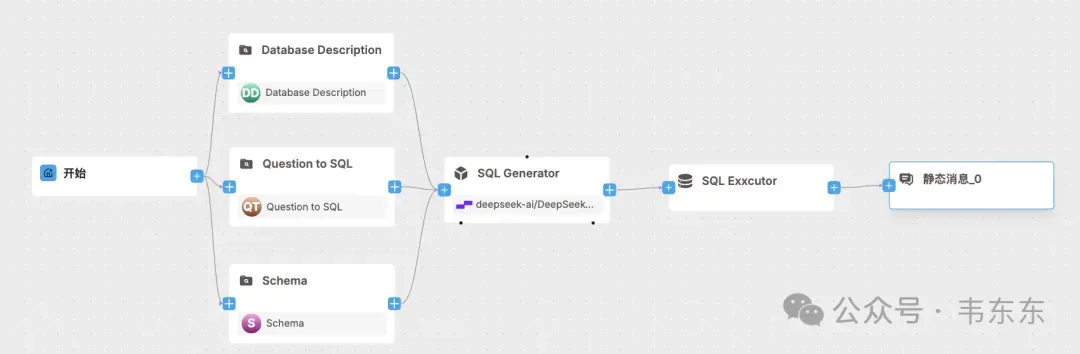
2、工作流逻辑
先看下工作流的整体架构,以及关键节点的配置操作。然后在正式测试前我会再介绍下知识库和数据库的相关配置。
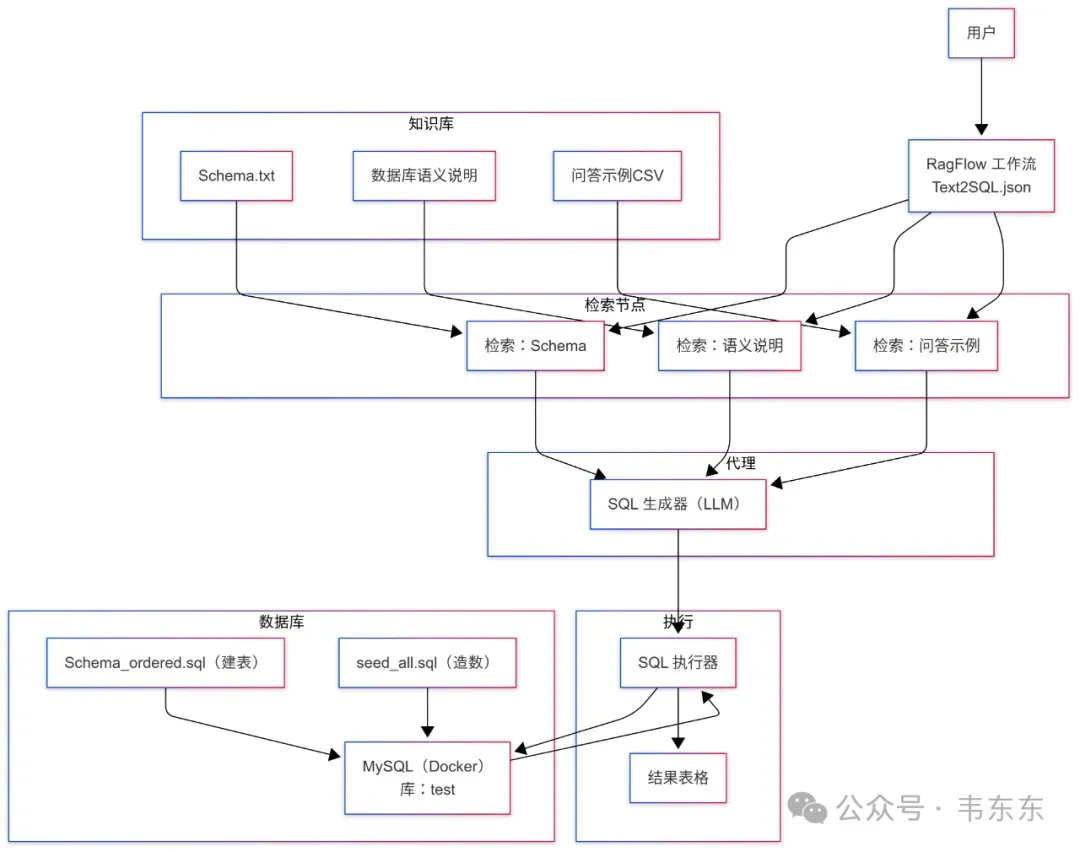
2.1三个检索节点
Schema:返回表结构片段(召回参数放宽,保证至少返回一条,用作硬约束)。
Question to SQL:召回 few-shot SQL 示例。
Database Description:返回字段语义/同义词(可选,易超时时可暂时移除)。
2.2生成节点(SQL Generator)
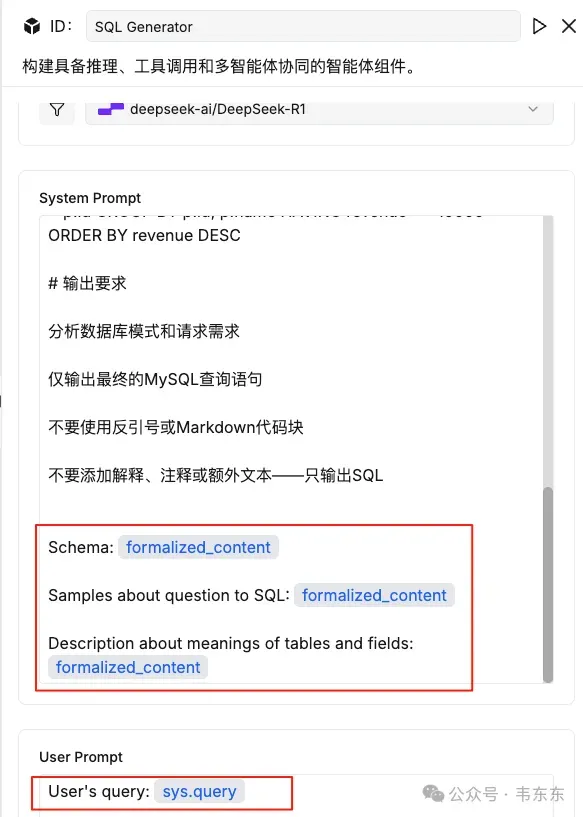
system prompt 放“角色/输出规范”,从三个检索节点注入上下文。
user prompt 只放 {sys.query}(最佳实践:把用户问题与系统上下文分层,避免被覆盖)。
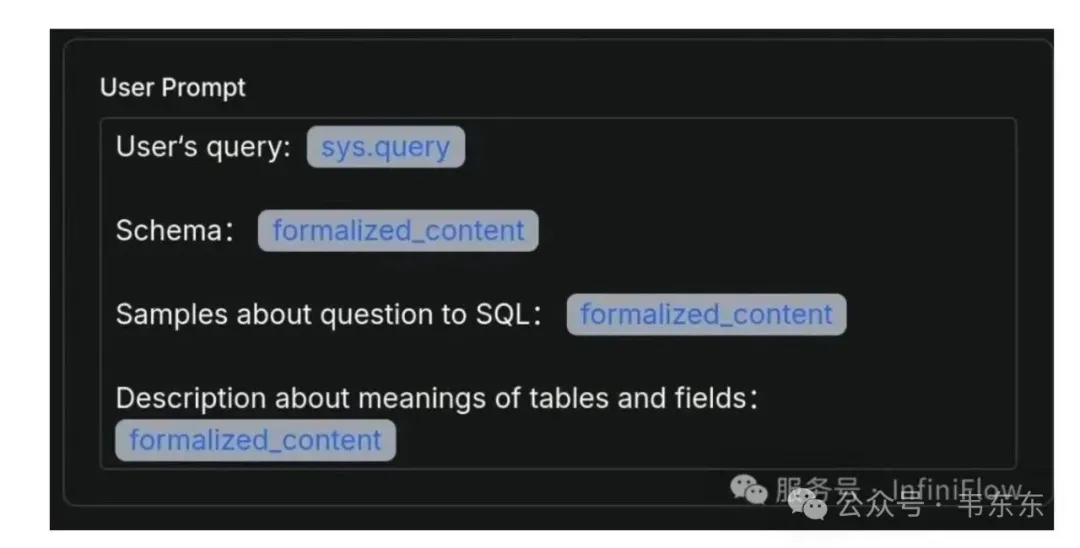
注:官方演示文章中这部分是错误的,如果把三个知识库的输出变量放在 user prompt 中,会被实际用户消息覆盖,导致 LLM 收不到 Schema 示例而不触发生成。应把检索到的上下文注入 system prompt(或模型的“上下文位”),user 仅放用户提问。
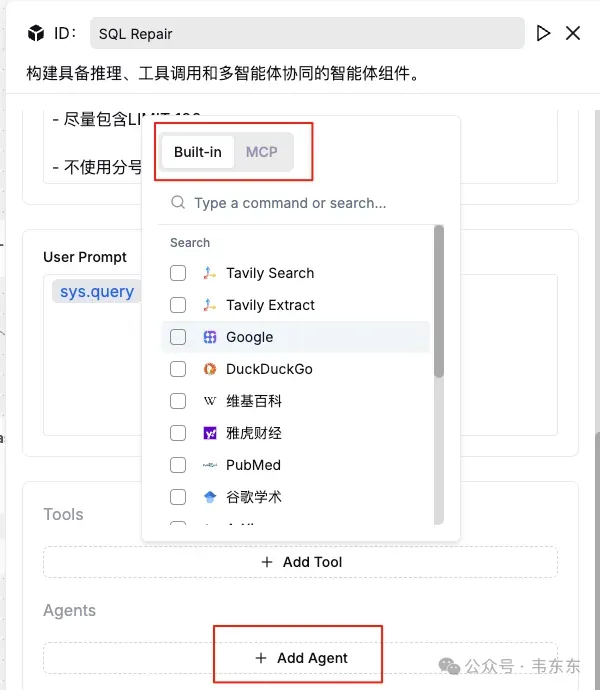
值得注意的是,在Agent节点中可以选择添加平台内置的工具或者MCP,也可以选择嵌套其他的Agent。
2.3执行节点(ExeSQL)
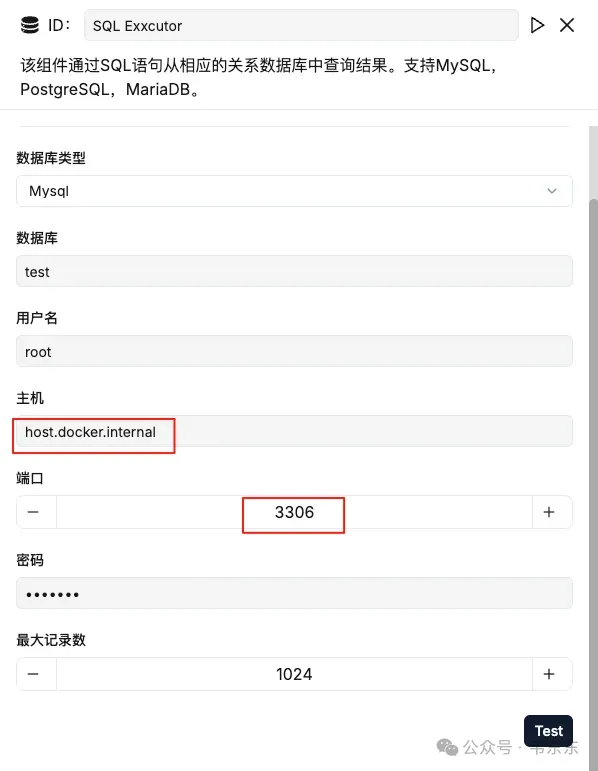
读取生成的 SQL,连接本机 MySQL。参照下述配置:库 test,用户 root,密码 ragflow,端口 3306。主机按运行位置三选一:127.0.0.1 / host.docker.internal / 实际 IP
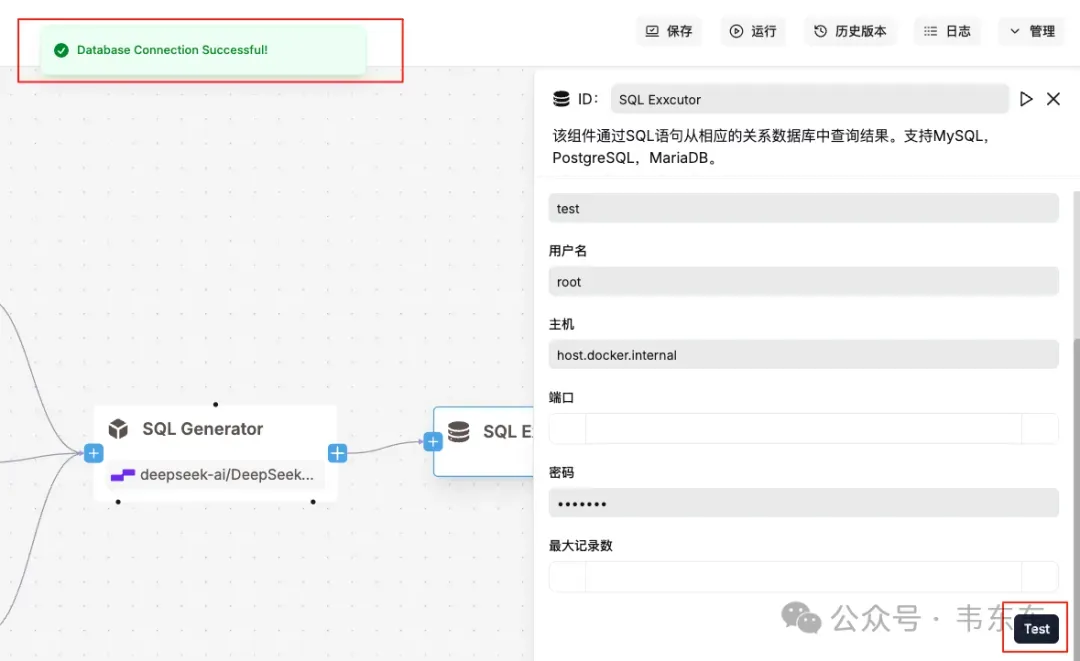
注意配置完数据库后,在执行节点做下连通性测试。
3、知识库构成
先用 Schema.txt 锁定可用表与字段 → 用 Database Description EN.txt 做语义对齐与别名映射 → 召回 QuestiontoSQL_mysql.csv 的最相近示例做 few-shot 参考并生成/修正 SQL。
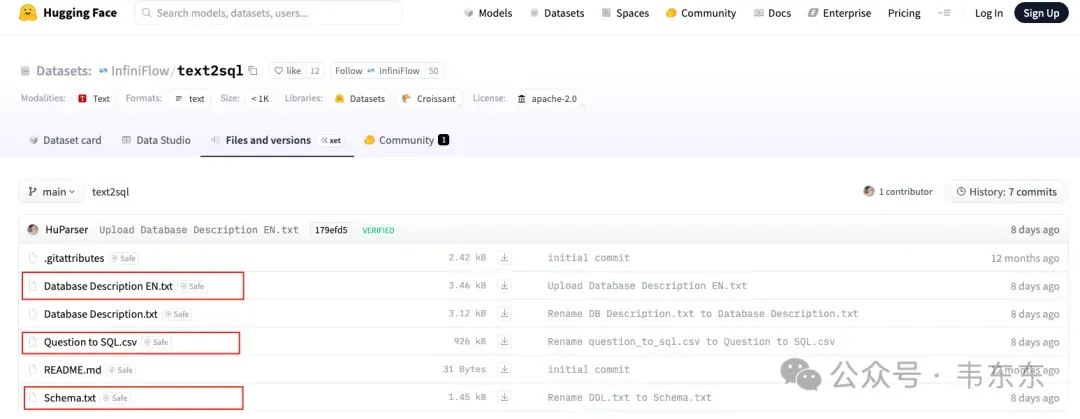
不建议直接使用官方提供的 Huggingface 样例数据,实际测试发现有以下问题:
Snowflake/PG 方言(ILIKE、DATE_PART、三段式 db.schema.table)、掺杂解释文字/Markdown、外部数据集引用、部分语句残缺、中英文重复等问题,和本地 MySQL 架构不匹配。
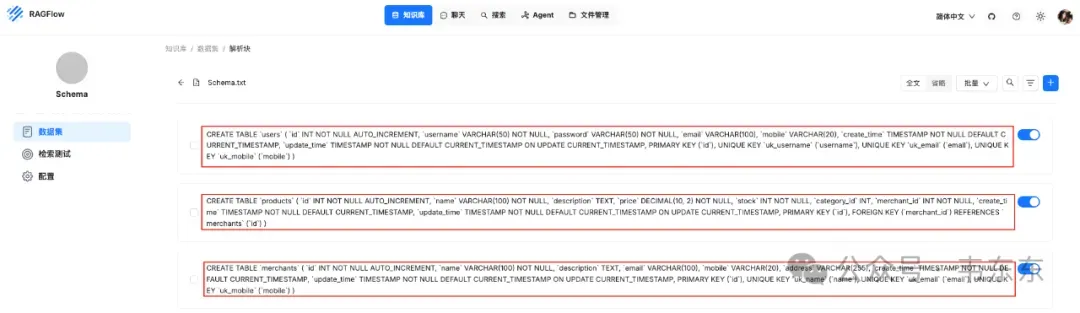
3.1Schema.txt(结构真相/DDL)
让模型知道真实的表/字段/约束,防止“编字段”;同一份 DDL 也用于实际建表。
切片方法:General、文本块大小:2 Token、文本分段标识符: “ ; “
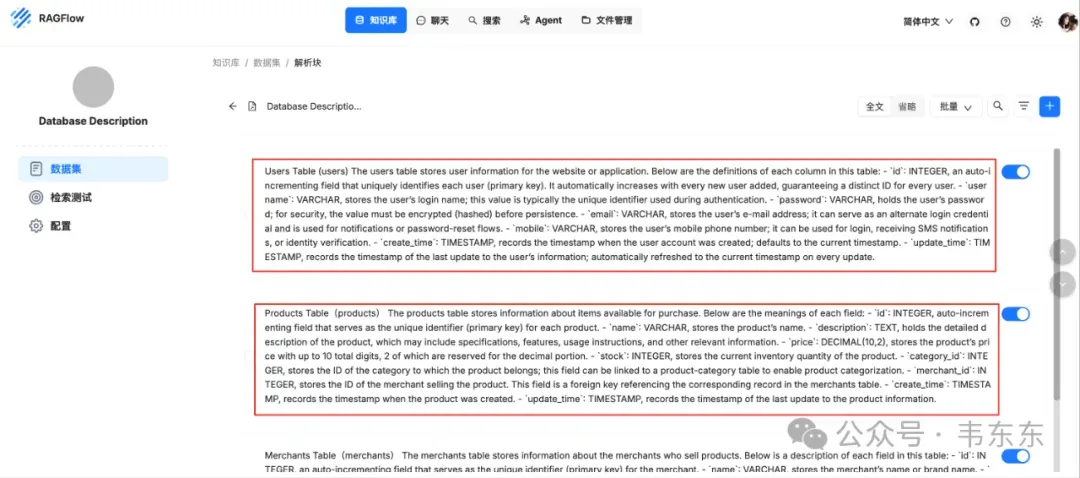
3.2Database Description EN.txt(业务语义)
用自然语言解释表/字段,提供同义词/口径,帮助从中文/英文问题映射到正确字段。
切片方法:General 建议文本块大小:2 Token 文本分段标识符:##
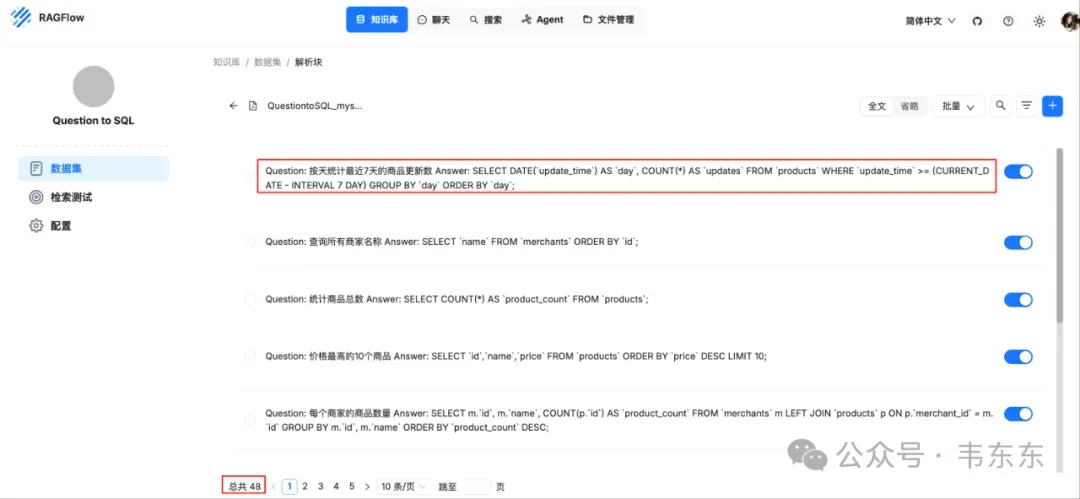
3.3QuestiontoSQL_mysql.csv(few-shot 示例)
“问题→SQL”成对样例,严格使用 MySQL 8 方言,且字段/表只来自 Schema.txt 的 users/products/merchants。覆盖单表筛选、JOIN、聚合/HAVING、时间过滤、排序/TopN 等常见模式。
配置切片方法为 Q&A
4、数据库配置
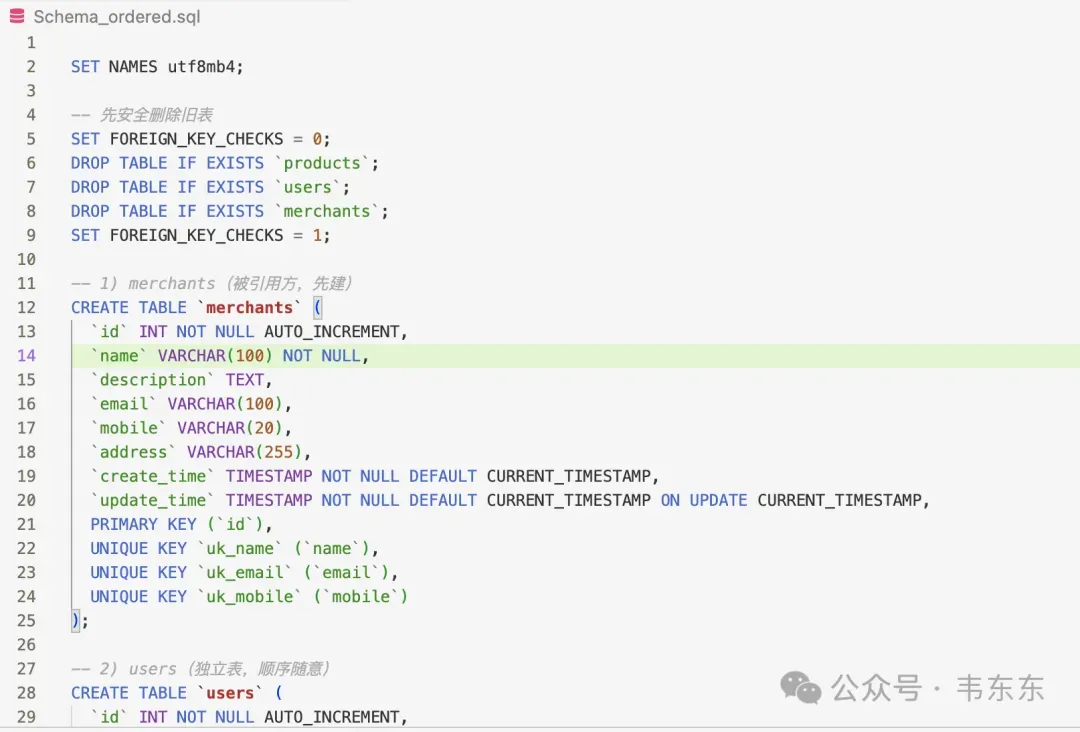
4.1Schema_ordered.sql
与 Schema.txt 等价,但按依赖顺序建表:merchants → users → products,避免外键引用表未创建导致的导入报错。
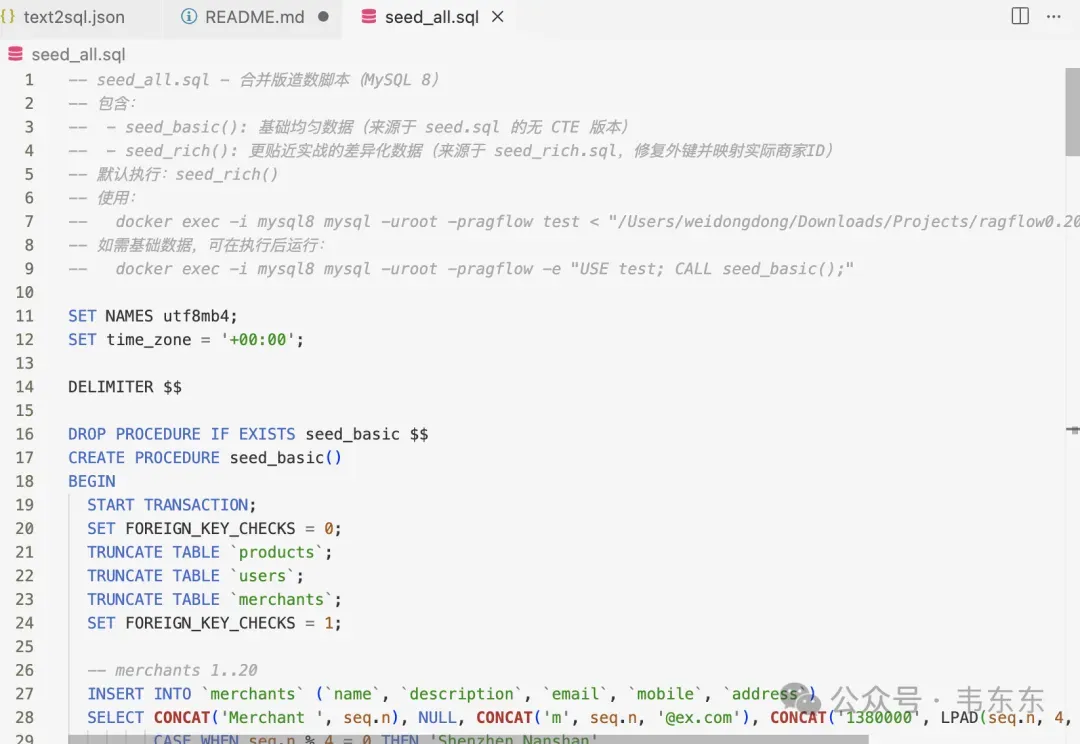
4.2seed.sql
插入更“像真实数据”的分布(价格/库存/类别/时间差异、零库存、空描述、商家分配不均),便于测试 TopN、时间、HAVING、多指标聚合;脚本会先 TRUNCATE 三表再插入。已修复外键映射,确保 merchant_id 一定落在实际存在的商家集合。
5、实际测试
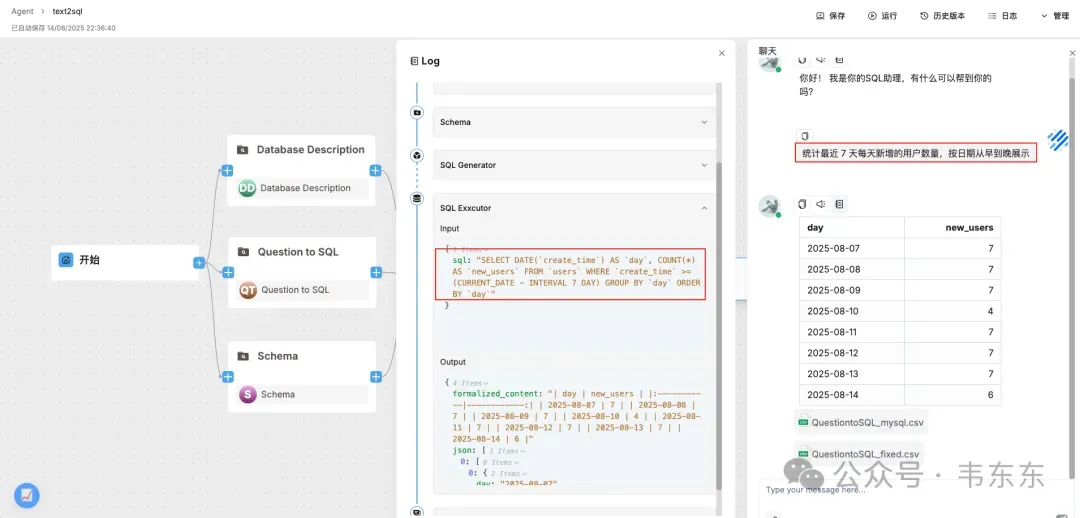
5.1问题测试
统计最近 7 天每天新增的用户数量,按日期从早到晚展示
选择理由:覆盖时间过滤与按日分组;检验是否用 MySQL 的日期函数(如 DATE()、INTERVAL),避免方言错误。
更多测试用例各位可以自由探索,完整的工作流json文件及测试文档已发布至知识星球。
5.2扩展报错
我尝试增加了验证与自修复环节的处理逻辑,但是报错显示 CodeExecParam 。这是由于平台端定义的“代码节点工具”的参数模型/适配器。缺失这个任何 Code 节点都会在解析阶段失败。
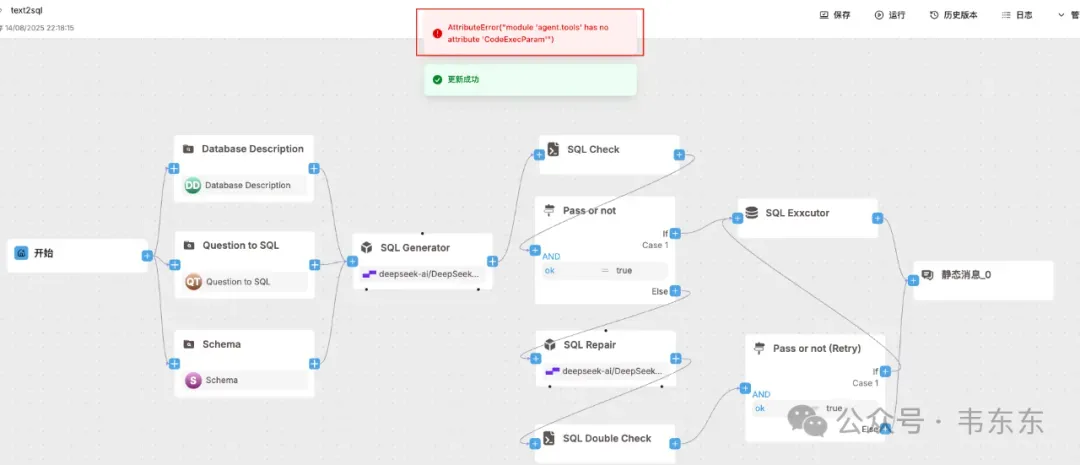
这通常由“后端版本不含代码工具/未开启安全开关/版本不匹配”导致。我没有具体研究如何解决,感兴趣的盆友可以再具体测试下。
总结来说,还是期待RAGFlow的Agent组件后续保持快速迭代。目前版本看起来,相比在Dify上实现类似功能,似乎还有很多核心节点的稳定性和延展性上做不少优化工作。


