
引言
从写 RAG 开发入门这一系列文章开始,特别是文档解析这个环节,有很多读者询问某个文档解析工具的能力怎么样,和其它工具对比如何,这表明开源社区虽然涌现出了很多的文档解析工具,但是它们在实际场景的表现到底如何,这在很多人中是没有太明确答案的。因而,面对众多工具的选择,我们期望能有一个统一的基准来评估其实际效果,而且对于大部分人来说是需要开箱即用的。
本文我将介绍一款由上海人工智能实验室开源的多源文档解析评测框架 - OmniDocBench[1],凭借其多样性、全面性和高质量标注数据以及配套的评测代码,是一个不错的衡量文档解析工具性能的选择。
目前OmniDocBench已被CVPR2025接受! CVPR2025是计算机视觉与模式识别领域的顶级国际学术会议,被誉为计算机视觉领域的“三大顶会”之一(与ICCV、ECCV并列)。
OmniDocBench论文[2]:
https://arxiv.org/html/2412.07626v1
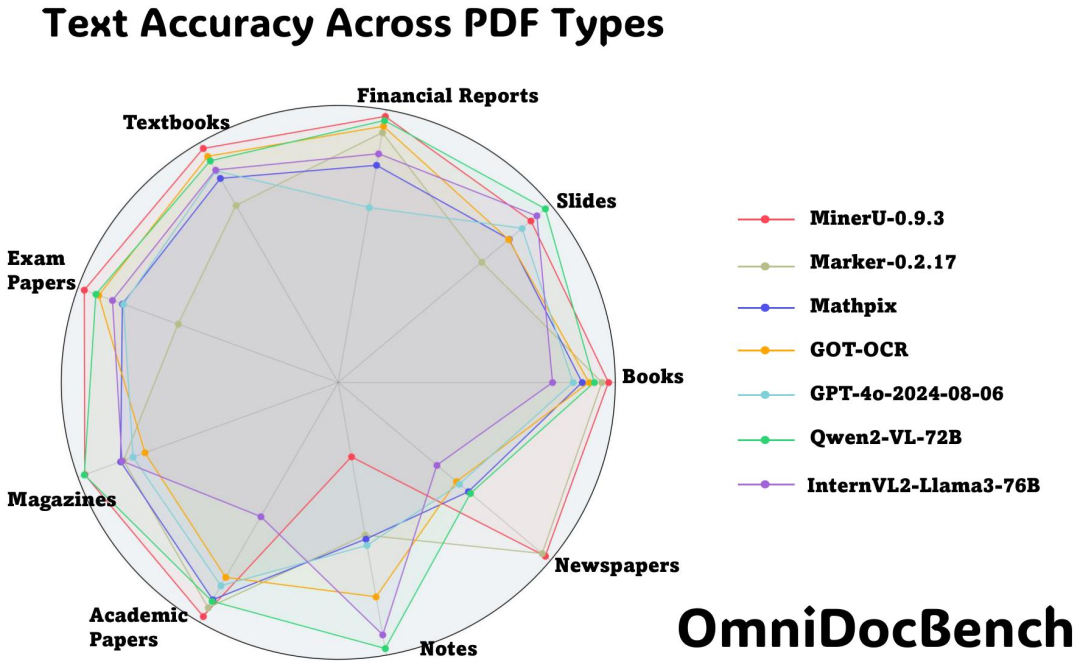
高质量基准测试集
OpenDataLab下载地址:https://opendatalab.com/OpenDataLab/OmniDocBench
Hugging Face下载地址:https://huggingface.co/datasets/opendatalab/OmniDocBench
高质量基准测试集是OmniDocBench的核心价值,其特点主要包括:
- 文档类型多样:该评测集涉及 981 个 PDF 页面,涵盖9 种文档类型(如学术文献、财报、报纸、教材、手写笔记等)、4 种排版类型(表格密集型、图文混合型、纯文本型等)和3 种语言类型(中文、英文、混合语种);
- 标注信息丰富:包含 15 个 block 级别(文本段落、标题、表格等,总量超过 20k)和 4 个 Span 级别(文本行、行内公式、角标等,总量超过 80k)的文档元素的定位信息,以及每个元素区域的识别结果(文本 Text 标注,公式 LaTeX 标注,表格包含 LaTeX 和 HTML 两种类型的标注)。OmniDocBench 还提供了各个文档组件的阅读顺序的标注。除此之外,在页面和 block 级别还包含多种属性标签,标注了 5 种页面属性标签、3 种文本属性标签和 6 种表格属性标签;
- 标注质量高: 经过人工筛选、智能标注、人工标注及全量专家质检和大模型质检,数据质量较高。
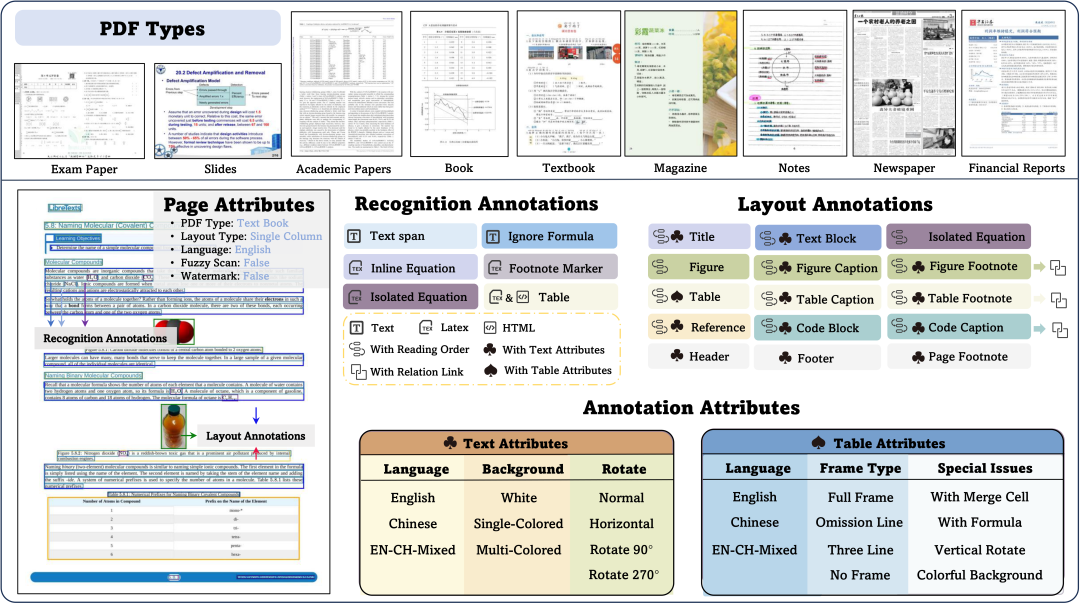
数据展示


支持多种衡量指标
OmniDocBench目前支持的衡量指标包括:
1. Normalized Edit Distance(归一化编辑距离):这个指标计算两个字符串之间的最小编辑操作次数(包括插入、删除、替换),并将这个距离进行归一化处理,通常用于衡量两个字符串或文本序列之间的相似度。归一化处理是为了让结果在 0 到 1 之间,便于比较;
2. BLEU(双语评价替补/Bilingual Evaluation Understudy):BLEU 是机器翻译领域中常用的自动评估指标,它通过比较候选译文和一组参考译文之间的 n-gram 重叠程度来计算得分,以此衡量机器翻译的质量。BLEU 分数越高,表示机器翻译的结果越接近人工翻译;
3. METEOR(基于明确排序的翻译评估/Metric for Evaluation of Translation with Explicit ORdering):METEOR 是一个更加复杂的翻译质量评估指标,它不仅考虑了单词精确匹配,还包括词干匹配、同义词匹配等,并且会根据词序差异对得分进行调整。因此,它比 BLEU 更能反映句子间的语义相似性;
4. TEDS(基于树编辑距离的表格相似度/Tree-based Edit Distance for Tables):TEDS 是一种专门用来评估表格结构相似度的指标。它将表格转换为树形结构,然后计算两棵树之间的编辑距离,以此来衡量表格结构上的相似度。这种指标特别适用于表格解析或者表格生成任务中的准确性评估;
5. COCODet (mAP, mAR, etc.):COCODet 指的是使用在 COCO 数据集上定义的一系列目标检测性能评估指标,主要包括:
- mAP(平均精度均值/Mean Average Precision):衡量模型在不同 IoU(交并比)阈值下的平均精度;
- mAR(平均召回率均值/Mean Average Recall):衡量模型在不同 IoU 阈值下的平均召回率。
每个指标都有其特定的应用场景和优势,你可根据具体的应用需求和上下文配置合适的衡量指标。
开箱即用的评测方法
OmniDocBench开发了一套基于文档组件拆分和匹配的评测方法,对文本、表格、公式、阅读顺序这四大模块分别提供了对应的指标计算,评测结果除了整体的精度结果以外,还提供了分页面以及分属性的精细化评测结果,精准定位模型文档解析的痛点问题。
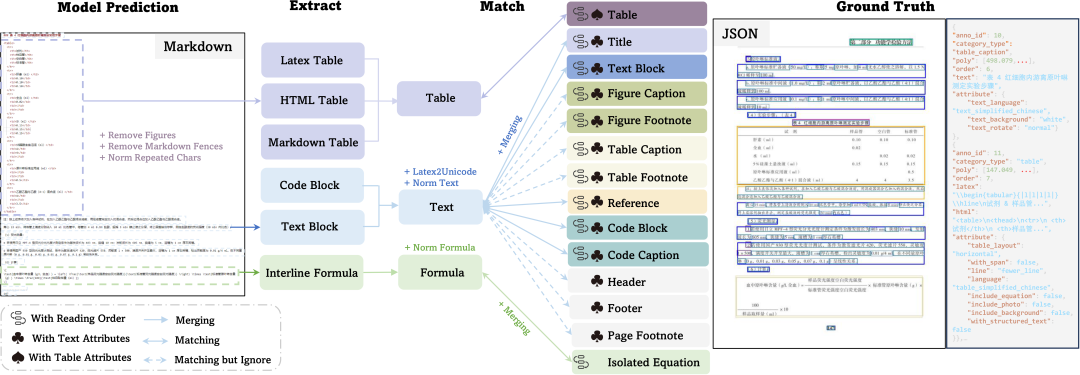
下载项目
环境配置和运行
下载评测集
OpenDataLab下载地址:https://opendatalab.com/OpenDataLab/OmniDocBench
Hugging Face下载地址:https://huggingface.co/datasets/opendatalab/OmniDocBench
评测集的文件夹结构如下:
评测配置
所有的评测的输入都是通过config文件进行配置的,在configs路径下提供了各个任务的模板。
比如端到端评测,你只需要在end2end.yaml文件中的ground_truth的data_path中提供 OmniDocBench.json的路径,在prediction的data_path中提供包含推理结果的文件夹路径,如下:
配置好config文件后,只需要将config文件作为参数传入,运行以下命令即可进行评测:
对开源工具的评测
可以端对端评测综合能力,也可以分项(文本、公式、表格、布局)评测。
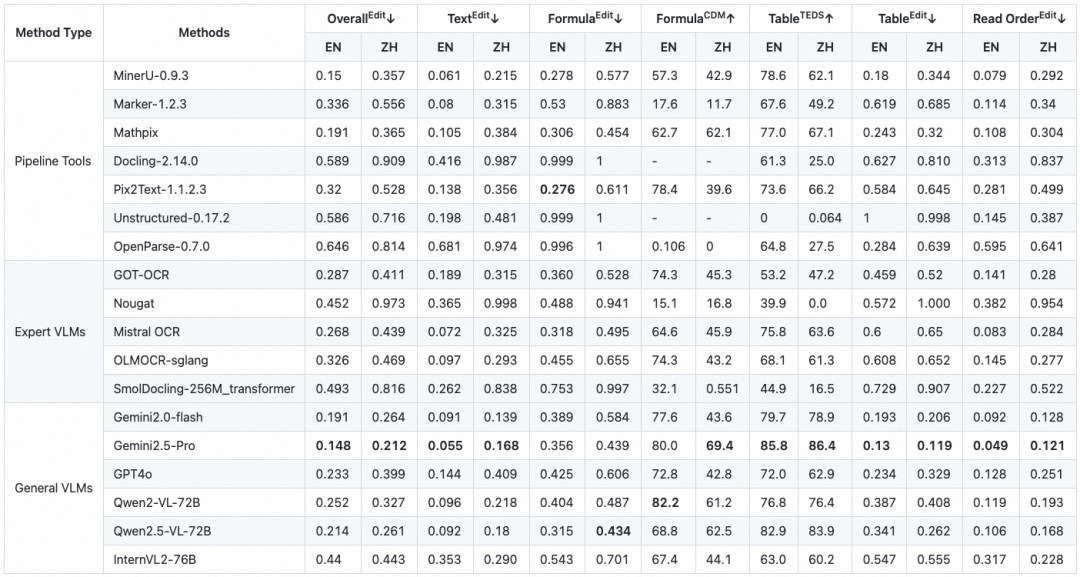
下面各个开源工具/模型的评测结果均是基于OmniDocBench的真实评测,可直接作为选择的依据。
端到端评测
端到端评测是对模型在PDF页面内容解析上的精度作出的评测。以模型输出的对整个PDF页面解析结果的Markdown作为Prediction。
公式识别评测
OmniDocBench包含每个PDF页面的公式的bounding box信息以及对应的公式识别标注(包括行间公式equation_isolated和行内公式equation_inline),因此可以作为公式识别评测的benchmark。
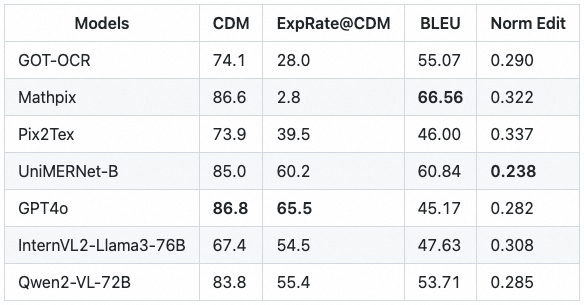
文字OCR评测
OmniDocBench包含每个PDF页面的所有文字的bounding box信息以及对应的文字识别标注(包含block_level的标注和span_level的标注),因此可以作为OCR评测的benchmark。
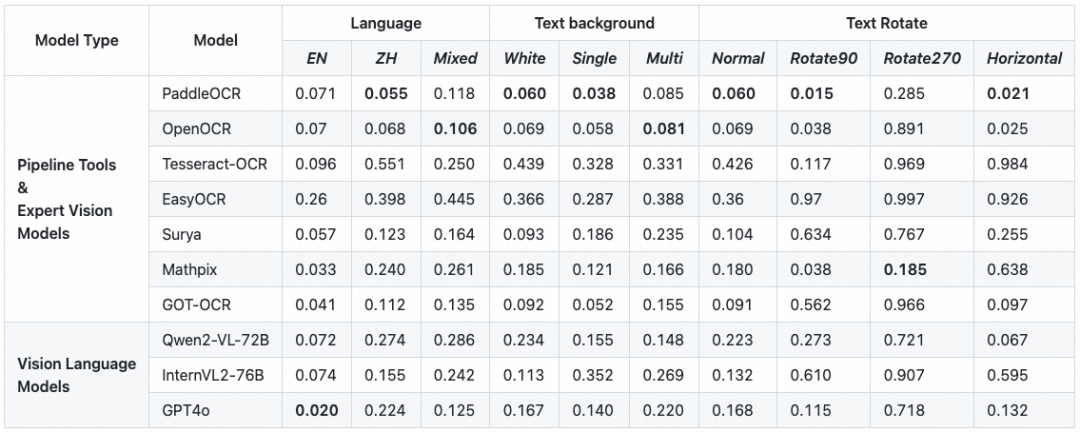
表格识别评测
OmniDocBench包含每个PDF页面的公式的bounding box信息以及对应的表格识别标注(包括HTML和LaTex两种格式),因此可以作为表格识别评测的benchmark。
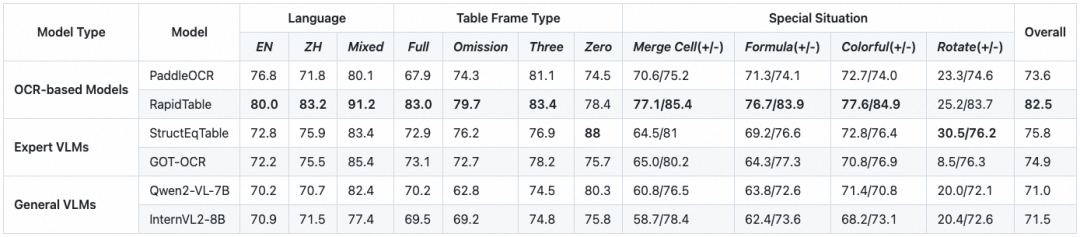
布局检测
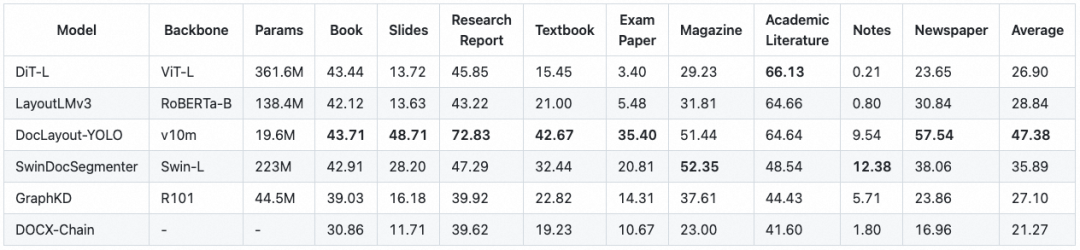
OmniDocBench包含每个PDF页面的所有文档组件的bounding box信息,因此可以作为布局检测任务评测的benchmark。
结语
本文给大家介绍了一款由上海人工智能实验室开源的多源文档解析评测框架-OmniDocBench,希望大家通过该评测框架,可以选出适合自己实际业务场景的文档解析工具。
引用链接
[1] OmniDocBench: https://github.com/opendatalab/OmniDocBench
[2] OmniDocBench论文: https://arxiv.org/html/2412.07626v1


