资讯列表
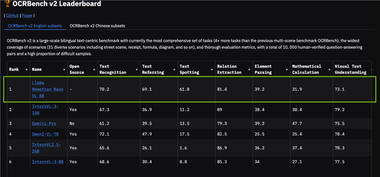
英伟达发布Llama Nemotron Nano VL AI:登顶 OCRBench,高精度文档处理解决方案
英伟达(NVIDIA)于2025年6月3日正式发布 Llama Nemotron Nano VL,一款专为文档智能处理优化的紧凑型视觉-语言模型(VLM)。 该模型在 OCRBench v2基准测试中荣登榜首,展现了其在处理复杂文档、图表和视频帧方面的卓越能力。 凭借高效的推理性能和灵活的部署方式,Llama Nemotron Nano VL 为企业提供了从云端到边缘设备的高精度文档处理解决方案。

Midjourney视频重磅来袭!V8模型蓄势待发,AI创意新时代即将来临!
据最新消息,Midjourney视频功能即将在本月上线,同时V7.1和V8模型的开发也在加速推进。 本文将为您详细解析Midjourney的最新动态,包括视频功能的突破、服务器升级、风格引用(sref)优化以及未来模型规划,带您一览AI图像生成的前沿进展。 视频功能蓄势待发,评级派对下周启动据AIbase获悉,Midjourney的视频生成功能已进入最后冲刺阶段,预计本月正式发布。
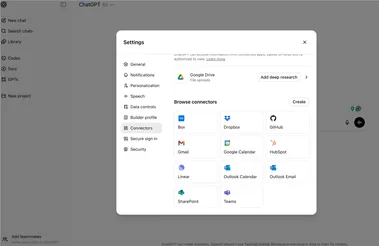
OpenAI宣布ChatGPT推出MCP支持与会议记录功能
OpenAI宣布,ChatGPT迎来两项重大功能更新:支持Model Context Protocol (MCP)以及新增会议记录模式,为企业和团队提供更高效的智能协作体验。 这两大功能的推出,标志着ChatGPT在企业级应用领域的进一步深化,旨在通过深度整合内部数据与自动化会议管理,提升工作效率与数据利用率。 以下为AIbase整理的最新动态与功能解析。

日本AI逆袭全球!Shisa V2 405B开源发布,碾压GPT-4的日语神器来了!
近日,AIbase从社交媒体平台获取最新信息,了解到一家专注于日语微调的HuggingFace模型提供者——Shisa.AI,其最新发布的日英双语模型引发业界广泛关注。 本文将为您详细解读Shisa.AI的最新成果及其在日语AI领域的突破性进展。 Shisa V2405B:日本最强开源模型诞生据AIbase了解,Shisa.AI最新发布了基于Llama3.1的Shisa V2405B模型,这一开源模型被誉为“日本有史以来训练的最强大型语言模型”。

蚂蚁国际发布AI金融平台Cockpit,开启智能代理驱动的新金融时代
蚂蚁国际正式推出人工智能即服务(AIaaS)平台——Alipay GenAI Cockpit,旨在为金融科技公司和超级应用构建AI代理和AI原生金融服务提供底层动力。 这一全新平台融合自动化工作流程与智能任务编排,覆盖支付编排、客户引导、合规检查、欺诈检测、争议解决、绩效优化等金融科技关键流程,标志着智能代理在金融行业的实用化与可扩展性迈出重要一步。 “金融的未来将由代理人工智能塑造。

Wordsmith AI 获 Index 领投2500万美元融资,重塑企业法务工作方式
总部位于苏格兰爱丁堡的法律科技公司 Wordsmith AI Ltd. 周二宣布完成2500万美元 A 轮融资,由 Index Ventures 领投,旨在推动其“将律师培养成法律工程师”的核心使命。 Wordsmith 专为企业内部法务团队打造人工智能平台,利用 Agentic AI 和聊天机器人,帮助法务人员自动审查合同与政策文件、提取洞见,并嵌入 Microsoft Word、Slack、Google Docs 等常用工具中进行操作。

美国商务部重组人工智能安全研究所,移除“安全”一词
美国商务部近日宣布将其人工智能安全研究所更名为人工智能标准与创新中心(CAISI),这项变动标志着该机构将重点从总体安全转向更加专注于应对国家安全风险和减少不必要的国际监管。 商务部长霍华德・卢特尼克于6月3日正式发布了这一消息,并表示此次重组旨在 “评估和增强美国创新”,同时确保美国在国际人工智能标准中保持领导地位。 图源备注:图片由AI生成,图片授权服务商Midjourney人工智能安全研究所成立于2023年,旨在为全球各国政府提供最佳实践,以降低人工智能系统可能带来的风险。

使用Claude 4提升程序员生产力的五种高级方式
译者 | 布加迪审校 | 重楼Anthropic的最新AI模型Claude 4在开发社区大行其道。 许多程序员称赞它是目前最好的编程模型,能够在短短几分钟内解决困扰一整年的编程难题,这是了不起的成就。 我们在本文中将探讨将Claude 4集成到工作流程中以提升生产力的五种有效方法。

OpenAI深夜宣布ChatGPT支持MCP、会议记录,万物互联时代来了!
今天凌晨1点,OpenAI开始技术直播对ChatGPT进行了重大更新,包括向macOS用户推出ChatGPT会议记录模式,可以转录任何会议、头脑风暴或语音笔记,并快速提取要点然后转化为新的内容。 另外一个重要功能就是ChatGPT正式支持MCP协议,例如,直接连接Github、SharePoint、Gmail、Dropbox、Box、Outlook等常用工具,实现跨平台数据整合、搜索和推理。 简单来说,OpenAI希望把ChatGPT打造成智能协作平台,在一个地方就把所有事情都做了。

配合OpenAI搞数据垄断,排挤Anthropic?Reddit撕破脸:赔钱!网友:互联网还没死!AGI太快这官司打完早没意义了
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)6月5日凌晨,就在WindSurf被Claude“断供”的消息传出来的第二天,Anthropic后院着火了。 这次的主角是大家熟悉的社交讨论平台Reddit。 Reddit在正式起诉Anthropic的文件中称,后者其在未经许可的情况下,大规模抓取Reddit公共内容,涉嫌侵犯版权。

AI+数字经济的核心三要素
前几天和一位互联网老兵聊天,他说:"现在的数字经济就像当年的工业革命,你看不见摸不着,但它正在重新定义一切。 "这话听起来有点玄乎,但仔细想想,确实如此。 你知道吗?

人工智能和知识图谱五:著名的开源和商业知识图谱工具
一、开源工具RDFLib:RDFLib是一个用于处理RDF的纯Python库。 它被开发人员广泛用于中小型项目或数据科学领域。 RDFLib允许您创建图表、解析RDF文件(Turtle、XML等)以及执行SPARQL查询(它有一个基于Python的SPARQL1.1引擎)。

奥特曼:假如给我一千倍算力,我会这样做
完美的人工智能是“一个拥有超人推理能力、1万亿个上下文标记并可以使用你能想到的所有工具的微型模型”。 这是奥特曼在最新的访谈中对下一代模型的展望。 他表示,理想中的AGI不需要包含知识——只需要思考、搜索、模拟和解决任何问题的能力。

陶哲轩再爆:一个月三破18年未解难题!AlphaEvolve彻底改写数学研究规则
数学界再次见证奇迹! 一项沉睡了18年的难题,在一个月内竟被AI与人类联手三度突破! 每一次都将我们对可能性的认知推向新高。

深度研究白菜化?谷歌将Gemini级AI研究能力开源
谷歌太良心了,推出"gemini-fullstack-langgraph-quickstart"的开源项目,这个项目用Gemini 2.5模型与LangGraph框架的结合,主打快速构建一个能够本地运行的自主进行深度研究的智能代理系统目前github已经飙升到3.5k星了,地址:"研究型AI代理",能够像人类研究员一样工作:它会根据用户的问题动态生成搜索关键词,通过Google搜索获取信息,分析结果中的知识空白,然后迭代地优化搜索策略,最终提供有充分引用支持的答案技术架构:前后端分离的现代设计前端:React与现代开发体验项目采用了React配合Vite构建工具的前端架构。 Vite的选择体现了对开发效率的重视——它提供了极快的热重载功能,让开发者能够实时看到代码改动的效果。 这种即时反馈对于调试复杂的AI交互界面特别重要,因为你需要频繁测试不同的用户输入场景后端:LangGraph的强大编排能力后端使用了LangGraph框架,这是一个专门为构建复杂AI工作流而设计的工具。

10步优化超越强化学习,仅需1条未标注数据!后训练强势破局
在具备强大的通用性能之后,当下大模型的研究方向已经转向了「如何解决特定且复杂的推理任务」,比如数学问题、分析物理现象或是构建编程逻辑。 要想达到更高的性能,除了海量文本的预训练之外,往往还需要进一步的后训练。 主流后训练方法是采用强化学习(RL),特别是结合可验证奖励的强化学习(RLVR)。

Andrej Karpathy最新暴论:这类软件正走向绝境,PS首当其冲?
Andrej Karpathy最新观点,觉得很有意思,分享给大家Karpathy 认为在人机协作日益紧密的时代,那些拥有复杂用户界面(UI)、充斥着大量滑块、开关、菜单,却缺乏脚本支持,并且建立在不透明、自定义二进制格式之上的软件产品,其前景堪忧Karpathy 的核心观点是,如果大型语言模型(LLM)无法读取软件的底层数据表示,也无法通过脚本来操作相关的设置和功能,那么这款产品就很难实现与专业人士的智能协同(AI Co-pilot),更无法赋能给数量庞大十倍、富有创造力的“产消者”(prosumers),让他们通过更接近自然语言的“氛围编程”(vibe coding)方式来驾驭产品他列举了不同风险等级的软件产品:高风险区:几乎所有的 Adobe 产品、数字音频工作站(DAWs)、CAD/3D建模软件。 这些产品严重依赖不透明的二进制对象或自定义文件格式,缺乏文本化的领域特定语言(DSL)支持。 AI难以理解其内部结构,更不用说进行编程控制中高风险区:Blender、Unity。

ChatGPT 新功能上线,助力职场高效协作
近日,OpenAI 宣布推出 ChatGPT 的两项新功能 ——“连接器” 和 “记录模式”,旨在将这一人工智能助手更深入地融入企业的日常工作流程。 这些更新不仅提升了 ChatGPT 的实用性,也让其成为众多职场人士的 “第二大脑”。 首先,新的 “连接器” 功能使 ChatGPT 能够无缝接入多种企业工具,如 GitHub、Google Drive、SharePoint 等。