资讯列表

告别人工写脚本!多模态大模型驱动携程UI自动化测试迈入“描述即生成”阶段
作者简介Jessi Peng,携程资深后端开发工程师,关注AI技术在测试领域的应用。 一、引言 在传统的UI自动化测试流程中,测试人员需要构建完整的开发环境,包括Python运行环境、PyCharm集成开发环境、自动化测试框架等工具链的配置与部署。 在用例编写过程中,测试人员必须通过人工方式精确定位目标UI元素,并基于自动化框架封装的底层方法,手工编写测试代码。

AI驱动电子表格平台Paradigm获500万美元种子轮融资 配备5000个AI智能体
在"AI智能体"这个概念还未兴起的时候,安娜·摩纳哥就已经开始构建AI智能体产品。 在开发了众多聊天机器人后,她开始寻找适合AI智能体的其他交互界面,最终将目光锁定在电子表格上。 摩纳哥向TechCrunch表示:"我有一个个人使用习惯,也注意到很多其他人都有这样的习惯,就是将非常重要的CRM数据放在电子表格中,因为这是最灵活的工具。

Perplexity进军印度市场!AI搜索巨头新增印度股票财报电话会议实时转录功能
AI搜索初创公司Perplexity正在强化其金融仪表板功能,新增了印度上市公司季度财报电话会议的实时转录服务,同时提供财报后会议的日程安排功能。 这一升级进一步丰富了Perplexity金融仪表板的功能体系。 该平台除了提供市场新闻资讯外,还展示市场摘要、股票交易所图表和表现最佳的股票信息。

小红书发布DynamicFace人脸生成技术,实现高质量图像视频人脸融合
小红书AIGC团队近日正式发布了名为DynamicFace的可控人脸生成技术。 据官方介绍,这项技术专门针对图像和视频领域的人脸融合任务进行优化,能够实现高质量与高度一致性的人脸置换效果。 DynamicFace技术的推出标志着小红书在AI内容生成领域的重要技术突破。

ARM 挖角亚马逊高管,推进自研芯片计划
根据路透社的最新报道,芯片架构授权公司 ARM 最近成功引进了亚马逊 AI 芯片主管拉米・辛诺(Rami Sinno),此举旨在加速公司自研完整芯片的进程。 辛诺在亚马逊曾负责开发名为 “Trainium” 和 “Inferentia” 的 AI 芯片,这些芯片专为支持大型 AI 应用程序而设计。 图源备注:图片由AI生成,图片授权服务商MidjourneyARM 的目标是从一个单纯提供芯片知识产权的供应商,转型为能够独立设计和生产完整芯片的企业。

Meta内部文件曝光:AI被允许与未成年人"性感对话"引发轩然大波
随着人工智能竞赛的白热化,Meta首席执行官马克·扎克伯格正采取激进策略以保持竞争优势,但最新曝光的内部政策文件却引发了严重的道德和安全担忧。 路透社记者杰夫·霍洛维茨近日披露的一份超过200页的内部文件显示,Meta对其AI聊天机器人制定了令人震惊的行为准则。 这份已获得Meta法律、工程和公共政策团队批准的政策文件,清晰展现了这家科技巨头希望向世界推出的AI系统类型。

Grammarly推出全新文档界面集成AI助手,既能帮写作又能检测AI生成内容
知名写作助手平台Grammarly推出了基于去年收购的生产力初创公司Coda技术构建的全新文档界面。 这一界面不仅配备了AI助手,还为学生和专业人士提供了多款AI工具,包括AI评分器、校对工具和引用查找器。 新界面采用了模块优先的设计理念,用户可以插入表格、列、分隔符、列表和标题等元素。

德克萨斯州检察官调查 Meta 和 Character.ai 的儿童心理健康 AI 聊天机器人
近日,德克萨斯州检察官肯・帕克斯顿(Ken Paxton)对 Meta 公司和人工智能初创企业 Character.ai 展开了调查,重点关注这些公司是否在推广其人工智能聊天机器人时存在误导行为,特别是涉及向儿童提供心理健康支持。 检察官办公室表示,他们已针对 Meta 的 AI 工作室和 Character.ai 的聊天机器人展开调查,指控这两家公司可能存在 “欺骗性商业行为”。 他们认为这些聊天机器人被宣传为 “专业治疗工具”,而实际上并没有合法的医疗资质或监督。

阿里亮剑Ovis2.5:90亿参数挑战巨兽,AI视觉从此不“近视”
在AI界,“参数为王”的信仰似乎坚不可摧,巨头们在千亿、万亿参数的军备竞赛中一路狂奔。 然而,阿里国际数字贸易集团(AIDC)最近却悄然扔出了一枚“深水炸弹”——Ovis2.5。 它没有夸张的参数规模,却用一种近乎“降维打击”的方式,重新定义了什么叫“经济型高性能”。

外媒评北京世界人形机器人运动会:进步神速,比真人刺激
为期三天的2025世界机器人大会在北京落下帷幕,共有500多款人形机器人参加,它们来自16个国家的280个团队。 大会还举办了2025世界人形机器人运动会。 在足球比赛中,机器人频频碰撞翻倒;在跑步项目中,还有机器人在冲刺时摔倒。

如何训练你的大型语言模型
打造一个听起来很智能的大型语言模型 (LLM) 助手,就像在反复塑造泥塑一样。 你从一块泥土开始,把它挤压成一个可行的结构,然后开始精雕细琢,直到最终成品。 越接近最终成品,那些精妙的点缀就越重要,正是这些点缀决定了最终成品是杰作还是恐怖谷效应。

GPT-5翻车实录:被寄予厚望的AI新王者,为何不如Claude?
昨天在Twitter上,一位开发者@Teknium1发了一条推文:"在多次尝试中,GPT-5(包括gpt-5-thinking-high max)表现不佳,不如Opus甚至Sonnet。 "这条推文迅速引爆了AI圈,成千上万的开发者开始分享自己的"翻车"经历。 作为一个从GPT-3时代就开始使用OpenAI产品的人,我对这次GPT-5的发布抱有极高期待。

4o-mini华人领队也离职了,这次不怪小扎
哦豁,OpenAI奥特曼又痛失一员大将。 Kevin Lu,领导4o-mini发布,并参与o1-mini、o3发布,主要研究强化学习、小模型和合成数据。 下一站是Thinking Machine Lab,OpenAI前CTO Mira Murati出走后新创立的AI公司,估值已达120亿美元。

小模型才是 Agent 的未来?这篇立场文把话挑明了
AI圈最近什么最火? 答案里一定有AI Agent。 从能帮你预订机票、规划旅行的私人助理,到能自动编写、调试代码的程序员搭档,AI智能体的浪潮正汹涌而来。

AI来了!记者、UP主、写手,谁能逃过这场「灭绝浪潮」?
AI正在重新定义信息获取的入口和方式。 同时,原生AI新闻产品带来的用户体验与传统新闻截然不同。 一项研究显示,AI已经在世界各地的新闻编辑室中崭露头角。

超越RAG和DAPT!华人团队新研究引热议:即插即用、无需改变原参即可让模型化身领域专家
一个小解码器让所有模型当上领域专家! 华人团队新研究正在引起热议。 他们提出了一种比目前业界主流采用的DAPT(领域自适应预训练)和RAG(检索增强生成)更方便、且成本更低的方法。
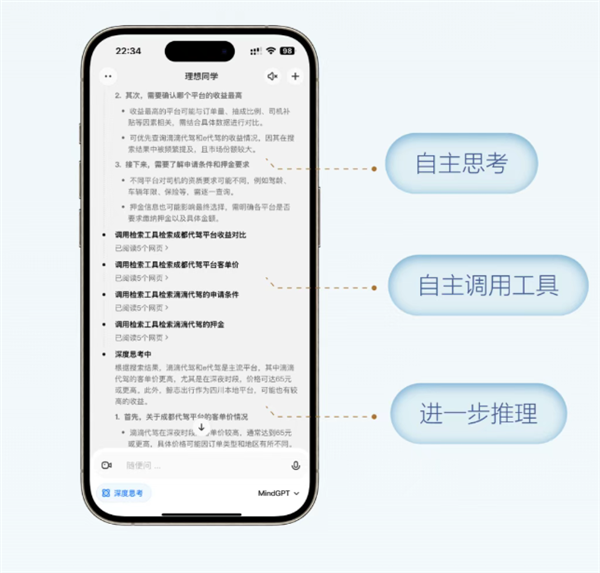
理想汽车MindGPT 3.1发布:速度跃升近5倍
理想汽车正式宣布其自研的MindGPT大模型迎来重大升级,全新版本MindGPT3.1惊艳亮相。 此次升级将智能体能力深度融入大模型之中,实现了边想边搜的创新功能,即在推理过程中能够同步调用各类工具,从而为用户提供更加迅速、全面且精准的结果反馈。 官方数据显示,MindGPT3.1在性能上实现了质的飞跃,每秒出字速度最高可达200tokens,相较于前代MindGPT3.0,速度提升近5倍,这一突破将极大提升用户与智能助手的交互效率。
英伟达新研究:小模型才是智能体的未来
henry 发自 凹非寺. 量子位 | 公众号 QbitAI大模型OUT,小模型才是智能体的未来! 这可不是标题党,而是英伟达最新论文观点:.