资讯列表

将KV Cache预算降至1.5%!他们用进化算法把大模型内存占用砍下来了
只用 1.5% 的内存预算,性能就能超越使用完整 KV cache 的模型,这意味着大语言模型的推理成本可以大幅降低。 EvolKV 的这一突破为实际部署中的内存优化提供了全新思路。 图源:(KV cache)已经成为大模型快速运行的核心技术,它就像一个「记忆库」,能够保存之前计算过的结果并重复使用,这样就不用每次都重新计算同样的内容。

兼得快与好!训练新范式TiM,原生支持FSDP+Flash Attention
TiM团队 投稿. 量子位 | 公众号 QbitAI生成式AI的快与好,终于能兼得了? 从Stable Diffusion到DiT、FLUX系列,社区探索了很多技术方法用于加速生成速度和提高生成质量,但是始终围绕扩散模型和Few-step模型两条路线进行开发,不得不向一些固有的缺陷妥协。

LLaSO 横空出世:逻辑智能推出全球首个完全开源语音大模型框架,定义 LSLM 研究新基准
在大型语言模型(LLM)的浪潮下,多模态 AI 取得了飞速发展,尤其是在视觉语言(LVLM)领域,已经形成了成熟的研究范式。 然而,与之形成鲜明对比的是,大型语音语言模型(LSLM)的发展却显得零散且步调缓慢。 该领域长期被碎片化的架构、不透明的训练数据和缺失的评估标准所困扰,导致研究之间难以进行公平比较,严重阻碍了技术的可复现性和社区的系统性进步。

AI解数学题只靠最后一个token
henry 发自 凹非寺. 量子位 | 公众号 QbitAI大语言模型在解心算题时,只依赖最后一个token? 最近,来自加州大学圣克鲁兹分校、乔治·梅森大学和Datadog的研究人员发现:在心算任务中,几乎所有实际的数学计算都集中在序列的最后一个token上完成,而不是分散在所有token中。
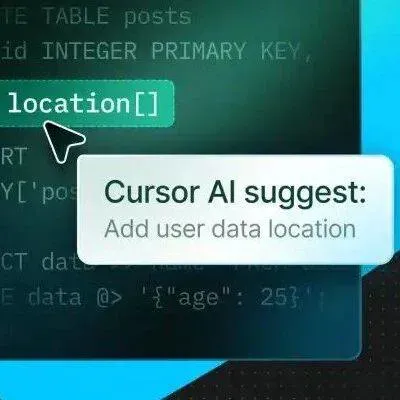
为这一个Tab键,我愿意单独付费:Cursor用在线强化学习优化代码建议,护城河有了?
Cursor Tab 是 Cursor 的核心功能之一,它通过分析开发者的编码行为,智能预测并推荐后续代码,开发者仅需按下 Tab 键即可采纳。 然而,它也面临着一个 AI 普遍存在的难题:「过度热情」。 有时,它提出的建议不仅毫无用处,甚至会打断开发者的思路。

小红书智创音频技术团队:SOTA对话生成模型FireRedTTS-2来了,轻松做出AI播客!
小红书智创音频技术团队近日发布新一代对话合成模型 FireRedTTS-2。 该模型聚焦现有方案的痛点:灵活性差、发音错误多、说话人切换不稳、韵律不自然等问题,通过升级离散语音编码器与文本语音合成模型全面优化合成效果。 在多项主客观测评中,FireRedTTS-2 均达到行业领先水平,为多说话人对话合成提供了更优解决方案。

大模型碰到真难题了,测了500道,o3 Pro仅通过15%
基准测试是检验大模型能力的一种方式,一般而言,一个有用的基准既要足够难,又要贴近现实:问题既能挑战前沿模型,又要反映真实世界的使用场景。 然而,现有测试面临着「难度–真实性」的矛盾:侧重于考试的基准往往被人为设置得很难,但实际价值有限;而基于真实用户交互的基准又往往偏向于简单的高频问题。 在此背景下,来自斯坦福大学、华盛顿大学等机构的研究者探索了一种截然不同的方式:在未解决的问题上评估模型的能力。

Claude记忆系统逆向研究!与ChatGPT完全相反!网友:放弃广告了?Claude深夜祭出记忆选项,隐身聊天,按项目单独记忆
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)上一篇文章中,小编分享了一位狠人逆向研究了 OpenAI 的 ChatGPT 底层记忆机制。 它的记忆系统主要分为四个板块:交互元数据、最近会话内容、模型设定上下文、用户知识记忆。 正是基于这样的设计,才会让 ChatGPT 充满了十足的留人能力。

用同一组提示词,横向测评30+热门AI绘画平台(中)
前言. 常见的 AI 生图模型大概有以下这些:黑森林的 flux kontext、flux krea、flux dev、flux pro、flux krea、flux1.1,谷歌的 imagen-4、nano-banana,OpenAI 的 Gpt-4o,以及国内的 Dreamina3.1、Qwen3、Wan2.2、星流,还有就是老牌的 Midjourney、Ideogram、即梦、豆包、可灵、海螺等其他平台。 当有设计需求,无论是要出主图还是找创意灵感时,我习惯根据具体使用场景,把提示词放到对应的平台上尝试。

2025北京文化论坛AI沙龙重磅举办!海淀率先破「百模」规模,105款大模型占全国五分之一
人工智能正在深刻改写文化生产方式,而数字艺术正成为最鲜活的见证。 9月13日,2025北京文化论坛平行论坛首场沙龙在海淀成功举办,聚焦“AI重塑数字内容生产”主题。 本次活动由北京市委网信办承办,海淀区委网信办、东升镇人民政府、快手联合协办。

Arm拥抱AI:五倍性能,三倍能效
构建芯片架构的 Arm,也全面拥抱 AI 了。 9 月 10 日,在上海举行的活动上,Arm 全新 Arm Lumex 计算子系统(Compute Subsystem,CSS)平台正式全球发布。 作为每年全球新款手机 SoC 的核心,今年的 Arm 解决方案重磅更新,让人们不得不关注。

Meta开源MobileLLM-R1模型,不到1B参数,用1/10的训练就超越了Qwen3
与其他全开源模型相比,性能提升2-5倍。 小参数模型也进入了 R1 时代,这次开源出新技术的是 Meta。 本周五,Meta AI 团队正式发布了 MobileLLM-R1。

清华、上海AI Lab等顶级团队发布推理模型RL超全综述,探索通往超级智能之路
超高规格团队,重新审视RL推理领域发展策略。 在人工智能的发展中,强化学习 (RL) 一直是一种非常重要的方法。 自 1998 年 Sutton 提出强化学习概念以来,就明确了只要给出明确的奖励信号,智能体就能学会在复杂环境中超越人类。

快手可灵团队提出MIDAS:压缩比64倍、延迟低于500ms,多模态互动数字人框架实现交互生成新突破
数字人视频生成技术正迅速成为增强人机交互体验的核心手段之一。 然而,现有方法在实现低延迟、多模态控制与长时序一致性方面仍存在显著挑战。 大多数系统要么计算开销巨大,无法实时响应,要么只能处理单一模态输入,缺乏真正的交互能力。

数据与AI双引擎驱动智能未来,2025外滩大会论数据进化之道
可供大模型训练的人类数据越来越少,Scaling Law正在缓慢失效,智能的上限,如何再次突破? 9月12日,在2025 Inclusion·外滩大会“Data meets AI:智能时代的双引擎”见解论坛上,产学界的多位权威专家给出了新解法:数据驱动了AI发展,AI也让数据迎来了新一轮的进化,双引擎融合驱动才是演进方向。 论坛由中国人工智能学会、上海交通大学与蚂蚁集团联合主办。
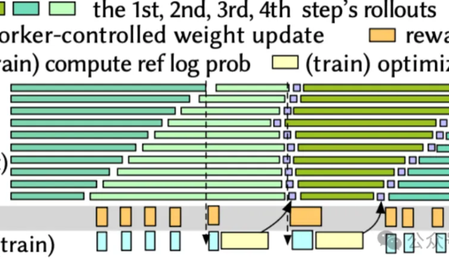
攻克强化学习「最慢一环」!交大字节联手,RL训练速度飙升2.6倍
强化学习的训练效率,实在是太低了! 随着DeepSeek、GPT-4o、Gemini等模型的激烈角逐,大模型“深度思考”能力的背后,强化学习(RL)无疑是那把最关键的密钥。 然而,这场竞赛的背后,一个巨大的瓶颈正悄然限制着所有玩家的速度——相较于预训练和推理,RL训练更像一个效率低下的“手工作坊”,投入巨大但产出缓慢。
他同时参与创办OpenAI/DeepMind,还写了哈利波特同人小说
这是硅谷版世界末日传教士Eliezer Yudkowsky的最新论点。 Yudkowsky用现在的话说,是个不折不扣的斜杠青年,是MIRI创始人,也是著名的哈利波特同人文作者。 但最引人注目的身份则是一手缔造OpenAI和谷歌DeepMind的中之人。
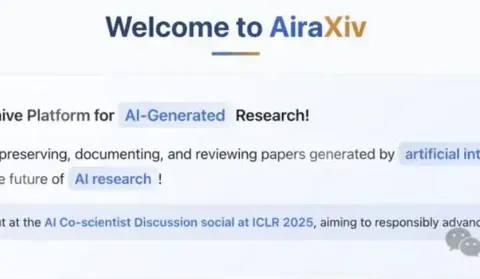
AI水论文还得AI治:西湖大学首次模拟人类专家思考链,AI审稿分钟级给出全面反馈
审稿不用再等了,高质量的AI审稿平台来了! 如今,AI生成的论文数量激增,如何从海量的AI “水文”中筛选出真正高质量的研究成果,已经成为学术界必须直面的难题。 为此,西湖大学自然语言处理实验室推出了首个AI生成学术成果的开放预印本平台AiraXiv,以及首个模拟人类专家思考链的AI审稿人系统DeepReview。