
作者介绍:德州农工大学博士生李港,专注于设计和应用高效算法到大规模机器学习和人工智能任务,包括增强大型基础模型的后训练算法、对抗性鲁棒学习算法和分布鲁棒性学习算法。曾发表数篇论文在 NeurIPS、ICML、KDD 等顶会, 并作为主要贡献者之一发布了针对不平衡分类任务的知名软件包 LibAUC。
DeepSeek-R1 的成功吸引了人们对群体相对策略优化(GRPO)作为大型推理模型(LRM)强化学习方法的广泛关注。
在本文中,作者分析了二元奖励(binary reward)设置下的 GRPO 优化目标,发现了由其群体相对优势函数引起的问题难度偏差的固有局限性,并且揭示了 GRPO 与传统判别式监督学习方法之间的联系。
基于这些分析发现,作者提出了一个新颖的判别式约束优化(DisCO)框架来强化大型推理模型。该框架基于判别式学习的基本原则:增加正确答案的得分,同时减少错误答案的得分。
与 GRPO 及其变体相比,DisCO 具有以下优势:
它通过采用判别式优化目标完全消除了难度偏差;
通过使用非裁剪评分函数和约束优化方法,解决了 GRPO 及其变体的熵不稳定性,得到了长期稳定的训练动态;
它允许结合先进的判别式学习技术来解决数据不平衡问题,例如在训练过程中一些问题的错误答案远远多于正确答案。
在增强大型模型的数学推理能力方面的实验表明,DisCO 大幅优于 GRPO 及其改进版本(如 DAPO),在 1.5B 模型的六个基准任务中,平均增益比 GRPO 高 7%,比 DAPO 高 6%。值得注意的是,最大响应长度(max response length)为 8k 的 DisCO 甚至优于最大响应长度为 32k 的 GRPO。
论文以「5,5,5,5」的高分被 NeurIPS 2025 接收。

论文标题:DisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization
论文地址:https://arxiv.org/abs/2505.12366
开源模型地址:https://huggingface.co/collections/ganglii/disco-681b705decb9979e65614d65
GitHub 地址:https://github.com/Optimization-AI/DisCO
GRPO 的难度偏差问题分析
GRPO 的核心思想在于对输入问题 q 生成多个输出,并定义群体相对优势函数。当采用期望形式而非经验平均时,其优化目标为:
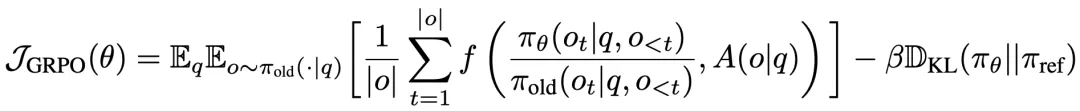
其中,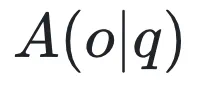 表示群体相对优势函数,
表示群体相对优势函数,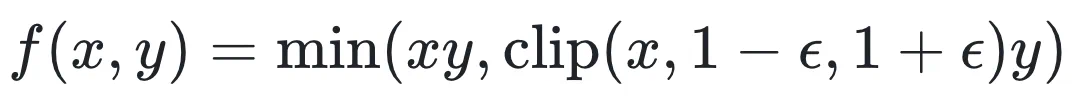 表示裁剪操作,
表示裁剪操作, 是冻结的参考模型。在二元奖励(binary reward)设置下,即奖励函数
是冻结的参考模型。在二元奖励(binary reward)设置下,即奖励函数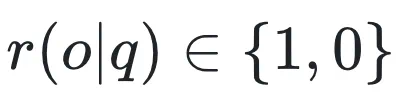 时,上述目标可简化为(暂时忽略 KL 项后):
时,上述目标可简化为(暂时忽略 KL 项后):
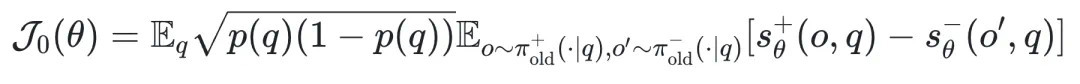
其中:
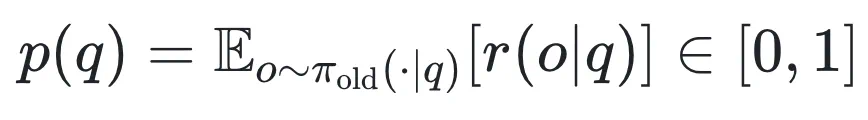 是正确答案概率
是正确答案概率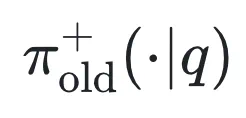 是奖励为 1 的输出分布(正确答案)
是奖励为 1 的输出分布(正确答案)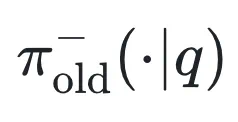 是奖励为 0 的输出分布(错误答案)
是奖励为 0 的输出分布(错误答案)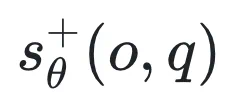 和
和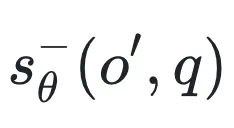 是裁剪后的评分函数。
是裁剪后的评分函数。
从上面的变式分析中,作者有两个重要发现:
1. 与判别式监督学习的联系
在上述优化目标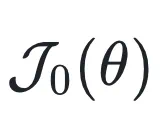 中,最大化
中,最大化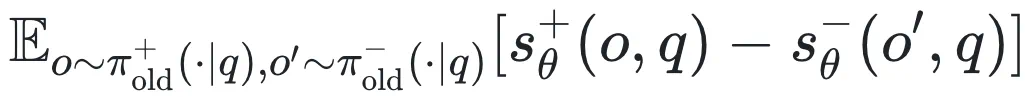 就是在增加正确答案的得分,同时减少错误答案的得分。这种优化目标与 AUC 最大化的判别式监督学习的思路不谋而合。
就是在增加正确答案的得分,同时减少错误答案的得分。这种优化目标与 AUC 最大化的判别式监督学习的思路不谋而合。
2. 难度偏差(Difficulty Bias)
在上述优化目标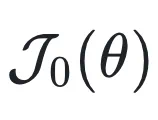 中,
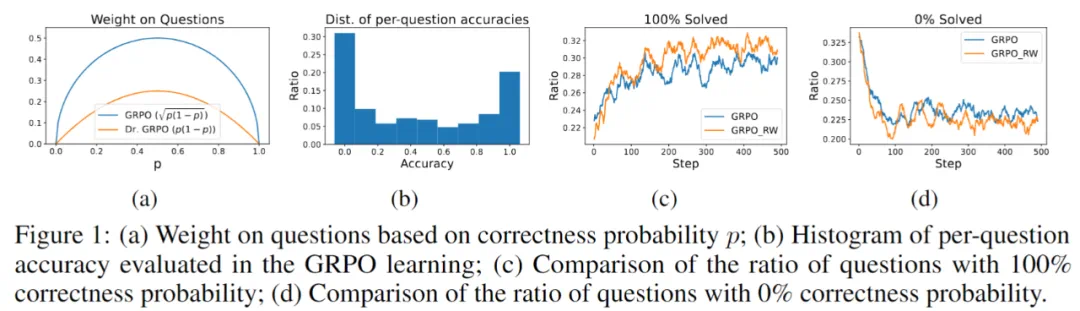
中,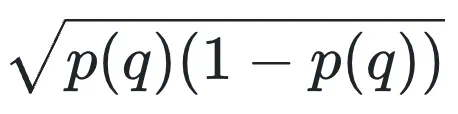 在每个问题上起到了加权作用,导致模型只重点学习「中等难度」的问题(如下图 a 所示)。然而实际训练过程有很多正确率相对较高或较低的问题却不被重视,使得学习效率下降。
在每个问题上起到了加权作用,导致模型只重点学习「中等难度」的问题(如下图 a 所示)。然而实际训练过程有很多正确率相对较高或较低的问题却不被重视,使得学习效率下降。
当作者移除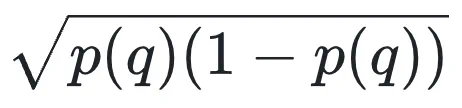 进行实验发现,没有加权的变体「GRPO_RW」能够在更多的问题上实现 100% 正确率和更少的问题上实现 0% 正确率(如下图 c, d 所示),证实了不适当的加权的有害影响。
进行实验发现,没有加权的变体「GRPO_RW」能够在更多的问题上实现 100% 正确率和更少的问题上实现 0% 正确率(如下图 c, d 所示),证实了不适当的加权的有害影响。
提出方法:判别式强化学习
1. 判别式目标函数(类似 AUC 优化)
基于上述与 AUC 最大化联系的分析发现,作者直接从判别式学习的原则重新设计了新的判别式强化学习框架:
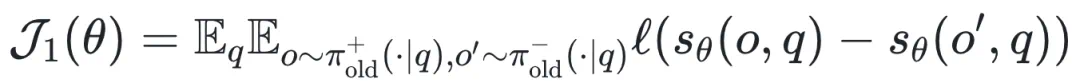
为了避免其他研究发现的由裁剪操作引起的熵崩塌现象,作者设计选择非裁剪评分函数, 例如:
对数似然 (log-L):
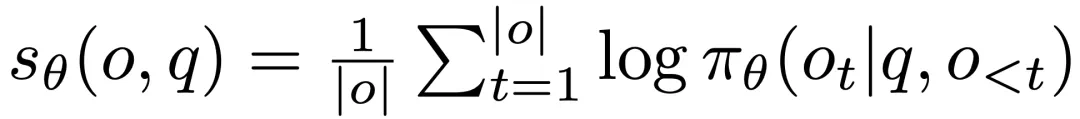
似然比 (L-ratio):
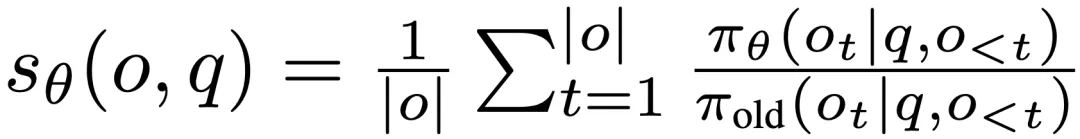
2. 基于 DRO 的判别式目标函数(类似局部 AUC 优化)
基于判别式学习原则设计目标函数的一个优点是能够利用文献中先进监督学习技术来改进训练。推理模型的强化学习微调的一个关键挑战就是稀疏奖励,这导致答案生成的不平衡。具体来说,对于一些问题,错误答案的输出的数量可能大大超过正确答案的数量,这反映了一个经典的数据不平衡问题。这个问题在判别式学习领域中得到了广泛的研究。
为了解决这个问题,作者利用局部 AUC 优化设计了分布鲁棒性优化(DRO)目标:
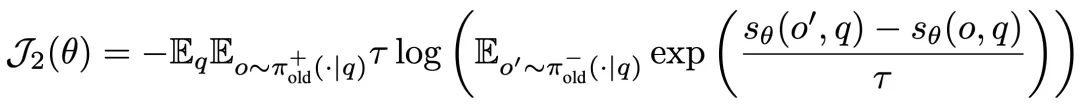
3. 约束优化(稳定训练)
为了稳定训练,作者借鉴 TRPO 中的信任域思想,加入 KL 散度约束,形成以下优化问题:
DisCO-b:
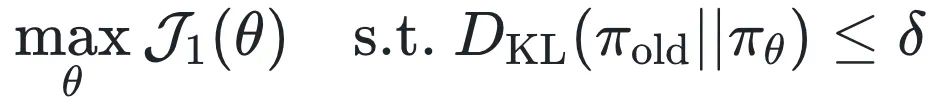
DisCO:
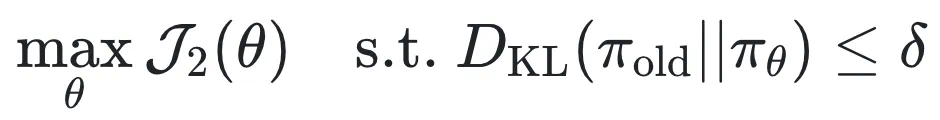
不同于 TRPO 的二阶优化方法,作者采用近期发展的一种非凸不等式约束优化策略,将约束替换为平滑的方形铰链惩罚项 (squred hinge penalty):
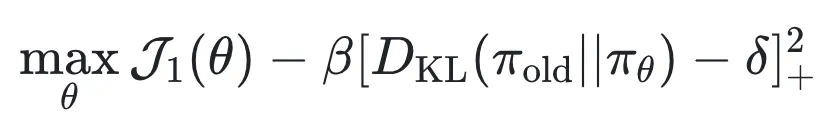
其中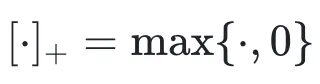 。 在适当条件下, 求解上述方形铰链惩罚目标可保证满足原始问题的 KKT 条件。
。 在适当条件下, 求解上述方形铰链惩罚目标可保证满足原始问题的 KKT 条件。
实验结果与分析
测试效果对比
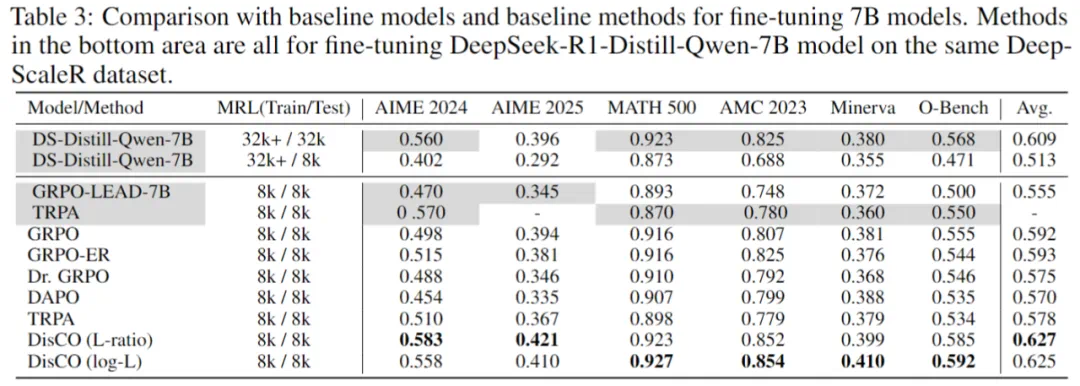
作者采用平均 16 次输出的 Pass@1 作为评价指标,在六个数学基准数据集上评估了 DisCO 和其他基线方法。
从下表观察到,作者提出的 DisCO 方法始终显著优于其他基线方法。值得注意的是,训练和推理长度均为 8k 的 DisCO (log-L)比 GRPO 平均提高了 7%,超过了以最大 24k 长度训练并以 32k 长度评估的 DeepScaleR-1.5B-Preview。在 7B 模型实验中,DisCO 也大幅优于所有基线方法,比 GRPO 平均提高了 3.5%。
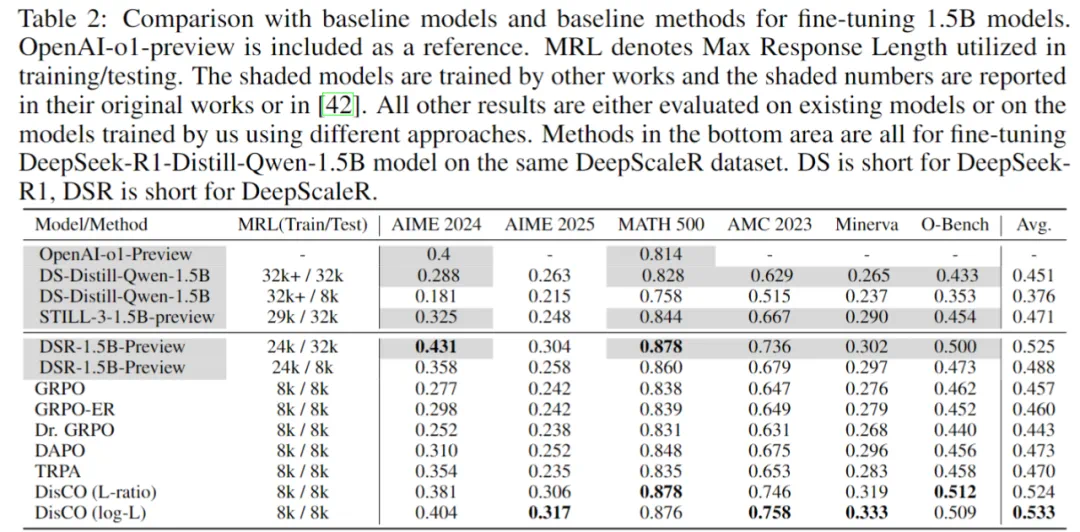
在上面这张表格中,作者展示了多种强化学习方法在 1.5B 模型上的效果对比。作者也加入了 OpenAI 的 o1-preview 模型作为参考基线。 表中的 MRL(Max Response Length)表示训练或测试时使用的最大响应长度,限制模型能生成多长的推理结果。 其中用阴影标注的模型,是其他团队所训练的成果,相应的指标也来自他们的原始论文或 DeepScalaR 项目。除了这些以外,其余结果要么来自现有模型的直接评估,要么是基于不同方法训练后得到的结果。 值得注意的是,表格下半部分的所有方法,都是基于相同的数据集(DeepScaleR),对 DeepSeek-R1-Distill-Qwen-1.5B 模型进行微调的结果。其中,DS 是 DeepSeek-R1 的缩写,DSR 是 DeepScalaR 的缩写。
训练动态对比
随着大规模强化学习训练成为改进推理模型的核心技术,学习算法的稳定性至关重要,因为学习稳定性决定了学习算法是否适用于大规模训练。作者从训练奖励和生成熵的角度比较了不同方法的训练动态。
从下图对 1.5B 和 7B 模型进行微调的实验中,我们可以看到,由于 GRPO、GRPO-ER、Dr. GRPO 的熵崩塌和 DAPO 的熵过度增长,它们都只能获得早熟的确定性策略或高度随机的策略,所有基线都出现了过早饱和。使用 KL 散度正则化的 TRPA 在后面的步骤中也观察到不稳定的生成熵。
相比之下,作者提出的 DisCO 使用两种非裁剪评分函数的方法最为稳定,训练奖励不断增加,生成熵保持相对稳定。
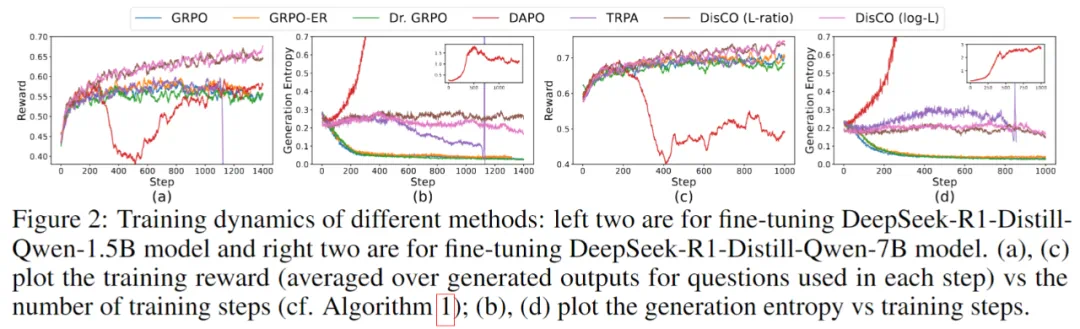
上图展示不同方法在训练过程中的动态表现:左边两张图展示的是在训练 1.5B 模型时的训练情况,右边两张图则对应于训练 7B 模型。图 (a) 和 (c) 展示了训练奖励随训练步数的变化情况,奖励是对每一步中用于训练的问题所生成答案的平均得分。图 (b) 和 (d) 展示的是生成结果的熵值(反映输出的多样性)随训练步数的变化趋势。
消融实验
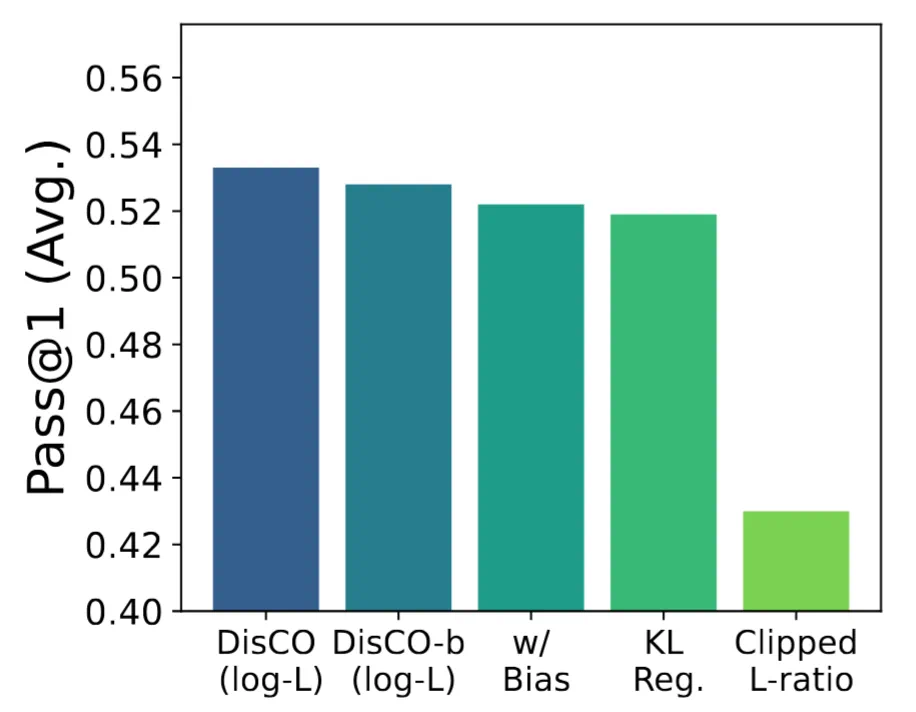
作者通过单独替换 DisCO 中的组件来分析每个组件的单独贡献。他们在 1.5B 模型上进行了实验,与 (1) 去除困难负样本权重的 DisCO-b 进行了比较;(2) 在 DisCO-b 中添加问题级权重偏差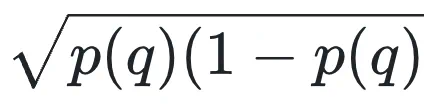 ,(3) 在 DisCO-b 中使用 KL-divergence 正则化替换 KL-divergence 约束,以及 (4) 在 DisCO-b 中分别使用
,(3) 在 DisCO-b 中使用 KL-divergence 正则化替换 KL-divergence 约束,以及 (4) 在 DisCO-b 中分别使用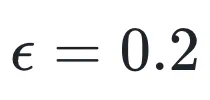 的裁剪评分函数。
的裁剪评分函数。
从下图中可以看到,作者提出的每个组件在 DisCO 的改进中都很重要,其中使用非裁剪评分函数是至关重要的。
总结
在这项工作中,作者提出了一种新的判别式约束优化框架用于强化大型推理模型,避免了难度偏差和熵崩塌问题。数学推理实验表明,与 GRPO 及其最近的变体相比,本文方法具有显著的优越性。
虽然这项工作主要关注的是二元奖励,但是对于非二元奖励,可以考虑利用监督学习中排序目标函数或者其他新颖的评分函数来进行设计。作者将应用判别式约束优化微调更大的模型或其他推理任务留作后续研究。


