
本工作由纽约大学 NYU SAI Lab 的硕士生王宇彤与博士生王海宇合作完成。本文的通讯作者为张赛骞,他是纽约大学(New York University)计算机科学系助理教授、SAI Lab 负责人,其研究方向涵盖多模态大模型(Vision-Language Models)压缩与加速、低比特量化、高效推理以及可信智能系统。
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
然而,强大的性能也带来了沉重的代价——模型动辄上百亿参数,显存和计算压力巨大。以 LLaVA-13B 为例,推理时 Key-Value 缓存(KV cache)体积极大,速度慢、资源耗尽,这让多模态/大模型的「落地」之路异常艰难。
面对这一瓶颈,来自纽约大学的研究团队 SAI Lab 在 NeurIPS 2025 上提出了一项突破性工作——QSVD(Efficient Low-rank Approximation for Unified Query-Key-Value Weight Compression in Low-Precision Vision-Language Models)。它通过「联合低秩分解 + 量化」的创新策略,为多模态模型找到了一条「轻量化而不减智」的新路径。

论文标题:QSVD: Efficient Low-rank Approximation for Unified Query-Key-Value Weight Compression in Low-Precision Vision-Language Models
论文地址:https://arxiv.org/abs/2510.16292
Github:https://github.com/SAI-Lab-NYU/QSVD
让多模态模型「减负」:从 Key-Value 缓存出发
视觉语言模型的强大来自 Transformer 中的注意力机制,但这也带来巨大的 KV 缓存压力。现有方案如 Grouped-Query Attention、Multi-Query Attention、DeepSeek 的 MLA 等虽能降低计算开销,却要么精度受损,要么需要重新训练。
QSVD 的目标很明确:不改架构、不重新训练,只通过数学压缩就让模型更轻、更快、更稳。
核心思想:联合 QKV 奇异值分解(Joint SVD over QKV)
传统做法是分别对 Q、K、V 矩阵进行奇异值分解(SVD),而 QSVD 首创联合分解(Joint SVD):
将三者拼接成一个整体矩阵后进行 SVD,只需一次降维计算(图 2-c),即可得到共享的下投影矩阵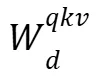 以及分别的上投影矩阵
以及分别的上投影矩阵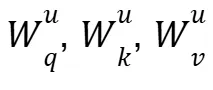 ,在秩 r < 0.75E 时,显著减少存储与计算。
,在秩 r < 0.75E 时,显著减少存储与计算。
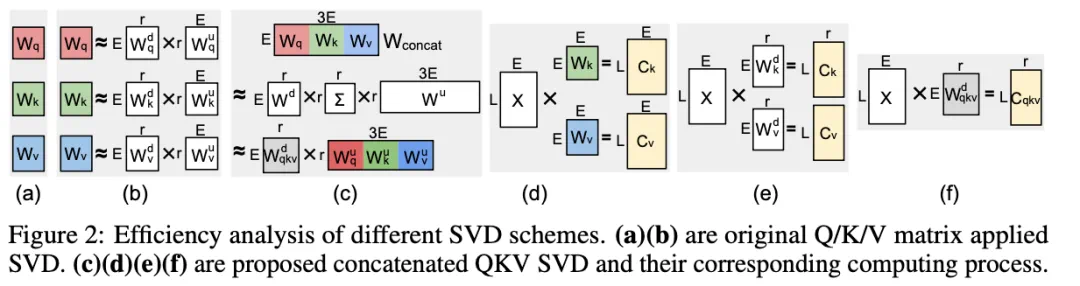
在推理阶段,传统方法需要分别存储所有的 K/V 缓存(图 2-d/e),而 QSVD 仅缓存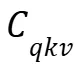 (图 2-f)。每当生成新 token 时,只需更新这一共享缓存,并通过各自的
(图 2-f)。每当生成新 token 时,只需更新这一共享缓存,并通过各自的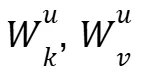 投影恢复具体的 K/V 值。这样显存占用直接减半,尤其在长序列生成中节省显著。
投影恢复具体的 K/V 值。这样显存占用直接减半,尤其在长序列生成中节省显著。
这带来三大优势:
计算更少:降维乘法减少矩阵乘法;
显存更省:只缓存一个中间表示,KV 缓存量减半;
表示更稳:联合分解保持 Q/K/V 之间的语义耦合,不损失信息。
自适应秩分配:让压缩更聪明
QSVD 进一步提出跨层秩分配策略(Cross-layer Rank Allocation)。不同层的重要性不同,不能「一刀切」地压缩。研究者通过梯度近似计算每个奇异值对模型损失的影响,得到重要性评分,并在全模型范围内排序与截断。

这样,模型可以智能决定「该减多少秩、留多少精度」,实现全局最优的压缩配置。
低比特量化 + 异常值平滑
仅靠低秩近似还不够。为了进一步提升硬件效率,QSVD 结合了后训练量化(PTQ)与异常值平滑(Outlier Smoothing)。
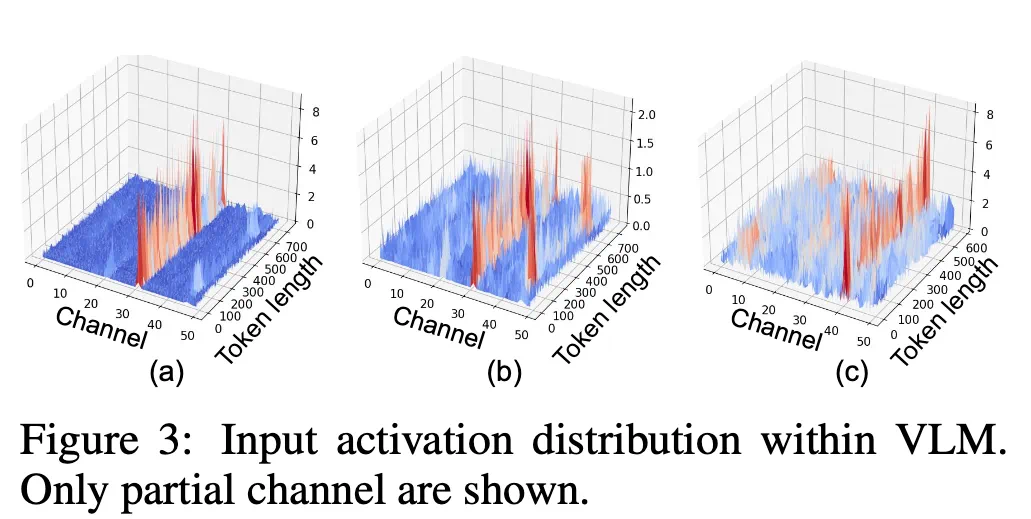
研究发现,VLM 激活值中存在严重的通道异常值(outliers),直接量化会导致信息丢失。为此,QSVD 引入两个正交变换矩阵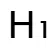 与
与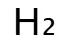 ,借鉴旋转量化(Rotation Quantization)的思想,使激活分布更平滑,从而在 4 位或 8 位量化条件下仍保持高精度。
,借鉴旋转量化(Rotation Quantization)的思想,使激活分布更平滑,从而在 4 位或 8 位量化条件下仍保持高精度。
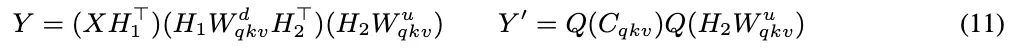
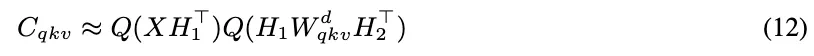
此外,还加入一个参数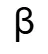 ,用于在校准集上优化奇异值的缩放比例,使不同通道间的动态范围更加平衡,显著降低量化误差。
,用于在校准集上优化奇异值的缩放比例,使不同通道间的动态范围更加平衡,显著降低量化误差。
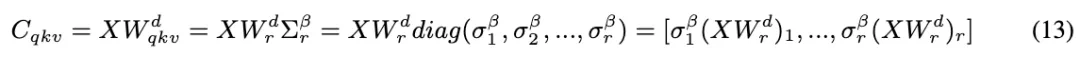
实验结果:更轻、更快、更准
研究团队在 LLaVA-v1.5(7B/13B)、LLaVA-Next 和 SmolVLM 等模型上进行了系统评估,结果令人惊喜:
FP16 比 ASVD 与 SVD-LLM 精度高 10% 以上;
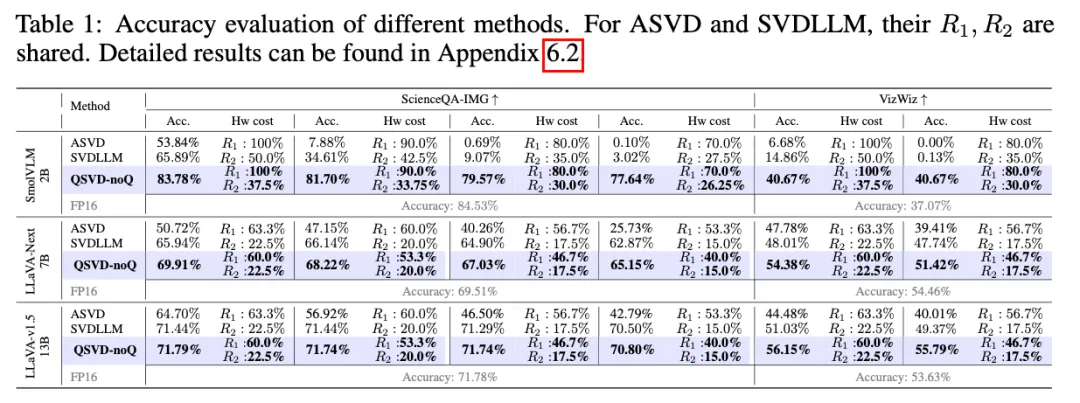
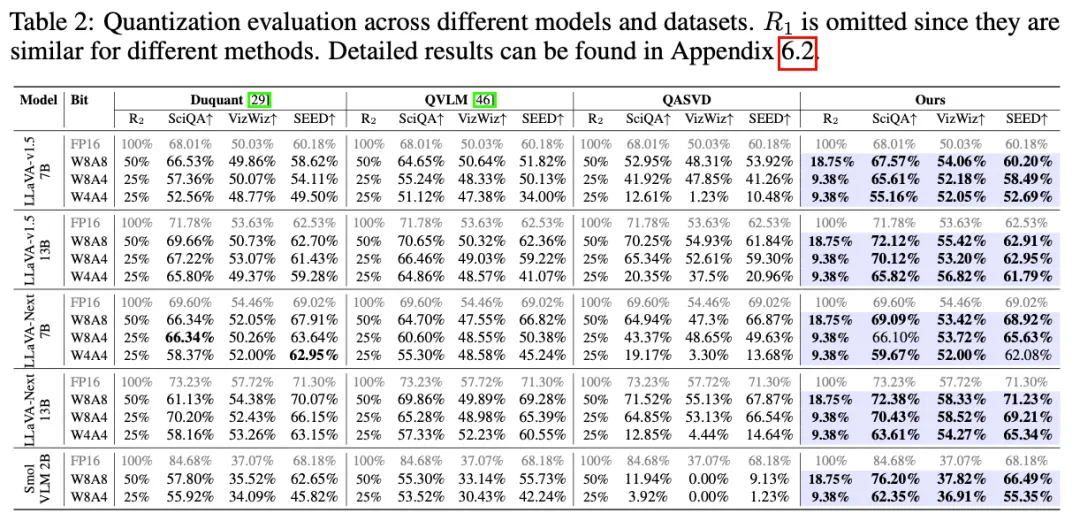
W8A8(8 位量化)下几乎无精度损失,W4A4 极低比特条件下依然稳定工作;
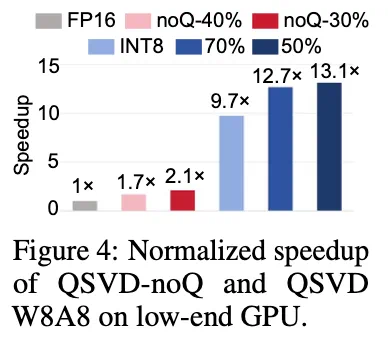
推理速度最高提升 13 倍。
这些结果说明,QSVD 不仅压缩模型,还让模型更「聪明」。
技术总结:三步实现高效多模态推理
Joint SVD over QKV
拼接 Q/K/V 矩阵,统一做低秩分解;
Cross-layer Rank Allocation
按重要性分配秩,全局最优压缩;
Quantization with Outlier Smoothing
旋转量化 + 可学习奇异值分配,抑制异常值。
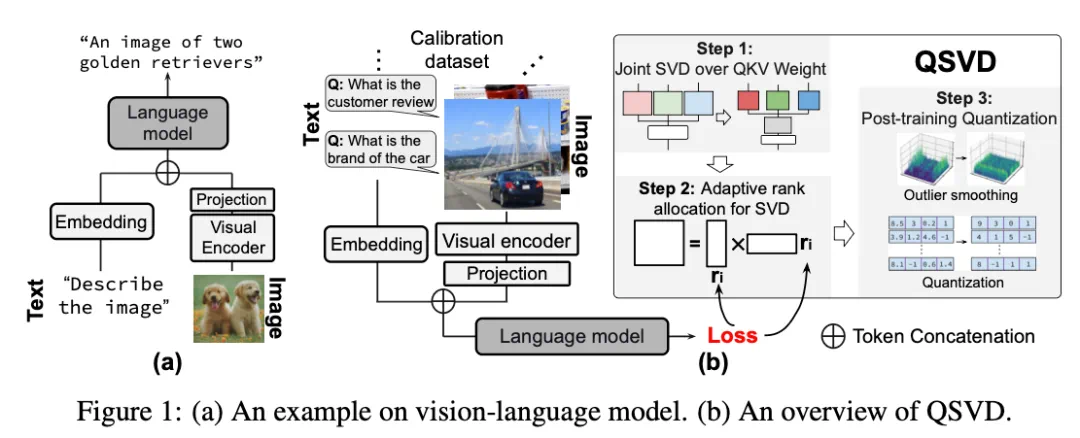
三步即可打造出低显存、高精度、快速响应的多模态大模型。
结语
在这项工作中,我们提出了 QSVD —— 一个将奇异值分解(SVD)与量化(Quantization)结合的统一框架,用于高效压缩视觉语言模型(VLM)。通过对 Q、K、V 权重矩阵的联合分解,并引入跨层自适应秩分配策略,QSVD 在几乎不损失精度的前提下,显著降低了计算开销、KV 缓存规模与模型存储成本。
虽然量化操作应用于整个模型,但压缩的核心集中在自注意力层(Self-Attention Layers)的 QKV 权重上,这正是影响推理效率的关键环节。未来,我们计划将优化范围扩展至跨模块联合压缩与自适应优化,进一步推动多模态模型的系统级轻量化。
值得注意的是,提高模型效率也意味着更强的可部署性与普惠性。当更强大的模型能够被更广泛地使用时,它们将有潜力加速教育、医疗、创意与人机交互的发展——但同时也可能带来监控、隐私与虚假信息传播等风险。如何在开放与安全之间取得平衡,是下一阶段研究必须正视的问题。
论文与代码均已公开,欢迎感兴趣的同学阅读、复现以及深入讨论。


