
本文第一作者是二年级博士生闫熠辰,主要研究方向是多模态大模型的数据质量管理;通讯作者是李环研究员,主要研究方向包括人工智能数据准备、大模型高效推理与部署、时空大数据与模型轻量化等。

01 省流版:一张图看懂 COIDO
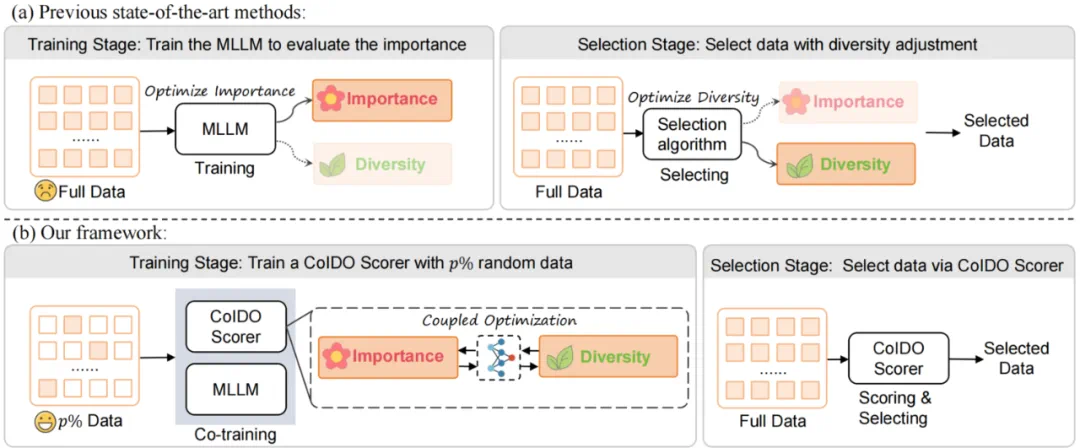
在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:
正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。而 COIDO 通过「耦合优化」的新契约,实现了以简驭繁的效果。
02 论文速览

论文题目:COIDO: Efficient Data Selection for Visual Instruction Tuning via Coupled Importance-Diversity Optimization
收录会议:NeurIPS 2025
作者单位:浙江大学大数据智能团队、杭州电子科技大学、北京邮电大学
项目代码:https://github.com/SuDIS-ZJU/COIDO
论文链接:https://arxiv.org/abs/2510.17847
03 研究背景与动机 (Motivation)
多模态大语言模型(MLLM)的能力在很大程度上依赖于高质量的视觉指令微调(Visual Instruction Tuning)。然而,随着数据集规模的爆炸式增长(如 LLaVA-665K),在全量数据上进行微调带来了巨大的计算开销和冗余 。
现有的数据筛选方法虽然旨在选取高质量子集,但普遍存在两个关键痛点:
高昂的筛选成本:现有方法通常要求目标 MLLM 对全量数据进行反向传播以计算重要性(如梯度、Loss),这导致筛选阶段本身的计算成本就极高,违背了 「降本增效」的初衷 。也就是说,为了筛选出少量有价值数据,我们还是得让全部的数据进入到目标 MLLM 当中并训练。
优化目标的解耦:数据筛选通常需要兼顾重要性(Importance)和多样性(Diversity)。现有方法往往将二者割裂处理——在训练阶段关注重要性,在筛选阶段通过独立算法处理多样性。这种解耦往往导致次优的权衡 。
针对上述问题,本文提出了 COIDO 框架,旨在通过极低成本的训练,实现重要性与多样性的联合(耦合)优化 。
04 方法论 (Mothodology)
COIDO 的核心思想是摒弃「遍历全量数据」的旧范式,转而采用轻量级评分器(Plug-in Scorer)配合小样本采样的策略。
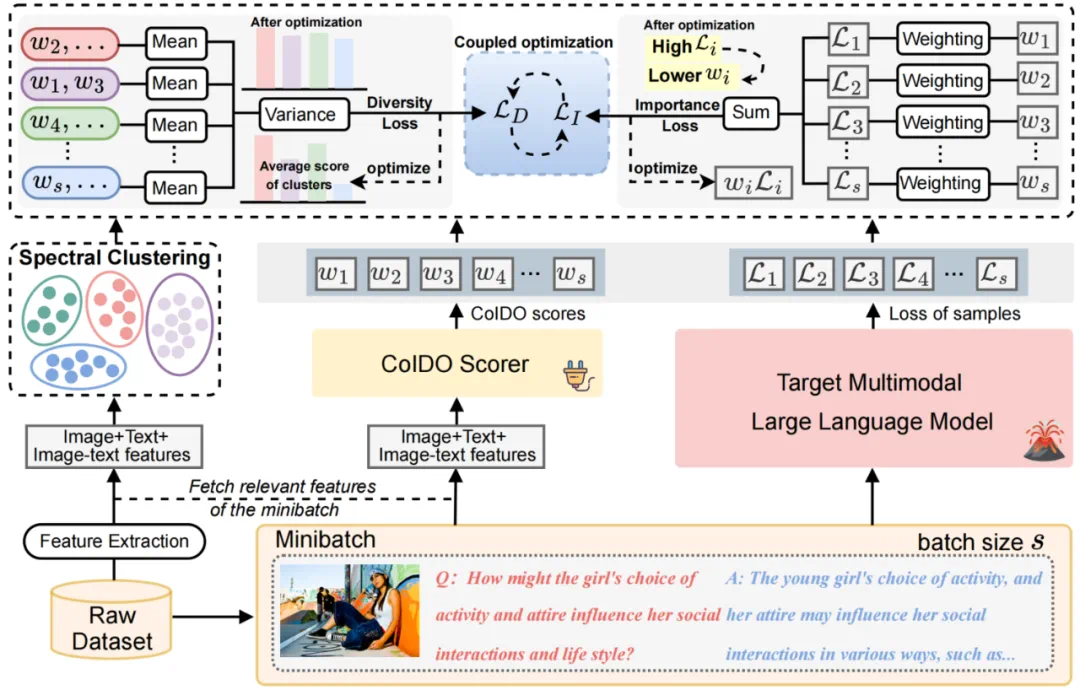
1. 轻量级评分器与小样本学习:不同于需要全量微调 MLLM 的方法,COIDO 引入了一个轻量级的插件评分器(COIDO Scorer)。我们仅从全量数据中随机采样一小部分(例如 20%)作为训练集。评分器通过这部分数据学习整个数据集的分布特征,从而能够对剩余数据进行泛化评分,无需遍历全集进行训练 。
2. 重要性与多样性的耦合优化 (Coupled Optimization) :这是本论文的核心创新点。本文将重要性和多样性的优化统一在了一个联合训练框架中,而非分阶段进行:
重要性损失 (L_I):基于 Cross-Entropy Loss 的重加权。我们将评分器输出的得分 w 加权作用于 MLLM 的预测 Loss。根据反向传播原理,模型会自动降低高难度(高 Loss)样本的权重以最小化整体 Loss,从而使得评分器隐式地学习到样本的重要性(即:分数越低,样本越重要 / 越难)
多样性损失 (L_D):基于谱聚类(Spectral Clustering)的方差最小化。我们在特征空间将数据聚类,并计算各簇(Cluster)平均得分的方差。通过最小化该方差,迫使模型在挑选高分样本时,不会过度集中于某一类,从而保证了数据的多样性分布。
3. 基于同方差不确定性的自动加权:为了解决多目标优化中权重超参数难以调节的问题,本文引入了基于同方差不确定性(Homoscedastic Uncertainty)的加权机制。该机制能够根据训练过程中的不确定性,动态调整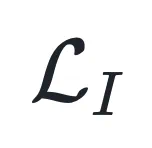 和
和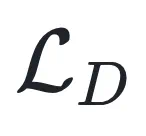 的权重,实现二者的自动平衡,即漫画中提到的「黄金平衡点」。本文设置了
的权重,实现二者的自动平衡,即漫画中提到的「黄金平衡点」。本文设置了 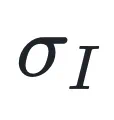 和
和 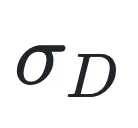 两个不确定参数来,分别指代重要性目标和多样性目标在大模型训练过程中的内在不确定性(或噪声水平)。
两个不确定参数来,分别指代重要性目标和多样性目标在大模型训练过程中的内在不确定性(或噪声水平)。
重要性目标的推导:对于重要性损失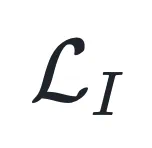 ,本文将其构建在一个实例加权的极大似然估计(MLE)框架下,采用加权玻尔兹曼分布(Boltzmann Distribution)来建模样本预测概率 。在推导其负对数似然函数时,针对其中的对数配分函数项,本文进行了二阶泰勒展开(Second-order Taylor Expansion)。这一展开过程自然地引入了预测分布的熵(Entropy)H (p)。由于在大模型生成任务中,有效的候选 Token 数量远小于词表大小,根据熵的定义本文能推导出展开式的一阶误差项有一个很小的上界,因此该项可以被忽略。最终,重要性目标被简化为由
,本文将其构建在一个实例加权的极大似然估计(MLE)框架下,采用加权玻尔兹曼分布(Boltzmann Distribution)来建模样本预测概率 。在推导其负对数似然函数时,针对其中的对数配分函数项,本文进行了二阶泰勒展开(Second-order Taylor Expansion)。这一展开过程自然地引入了预测分布的熵(Entropy)H (p)。由于在大模型生成任务中,有效的候选 Token 数量远小于词表大小,根据熵的定义本文能推导出展开式的一阶误差项有一个很小的上界,因此该项可以被忽略。最终,重要性目标被简化为由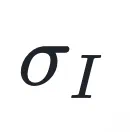 缩放的交叉熵损失形式。
缩放的交叉熵损失形式。
多样性目标的推导:对于多样性损失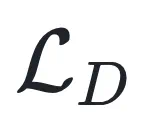 ,本文将其建模为一个满足高斯分布的回归问题,假设不同聚类簇的平均权重服从方差为
,本文将其建模为一个满足高斯分布的回归问题,假设不同聚类簇的平均权重服从方差为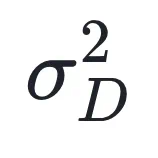 的高斯分布。通过最大化该分布的对数似然,导出多样性目标形式。
的高斯分布。通过最大化该分布的对数似然,导出多样性目标形式。
最终耦合损失函数:结合上述两部分,最终的总损失函数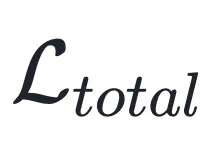 定义为:
定义为:
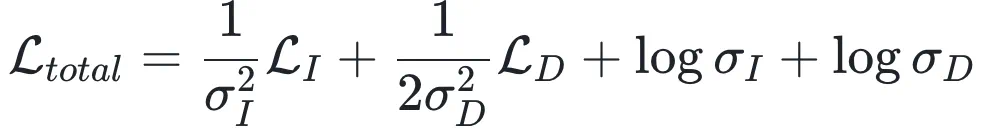
当某项任务的不确定性(噪声)较高时,模型会自动增大对应的 ,从而降低该项损失在总梯度中的占比,实现重要性与多样性的自适应「黄金平衡」。
,从而降低该项损失在总梯度中的占比,实现重要性与多样性的自适应「黄金平衡」。
05 实验 (Experiments)
本文在 LLaVA-1.5-7B 模型及 LLaVA-665K 数据集上进行了广泛验证,并在 10 个主流多模态基准(包括 VQAv2, GQA, MMBench 等)上进行了测试。
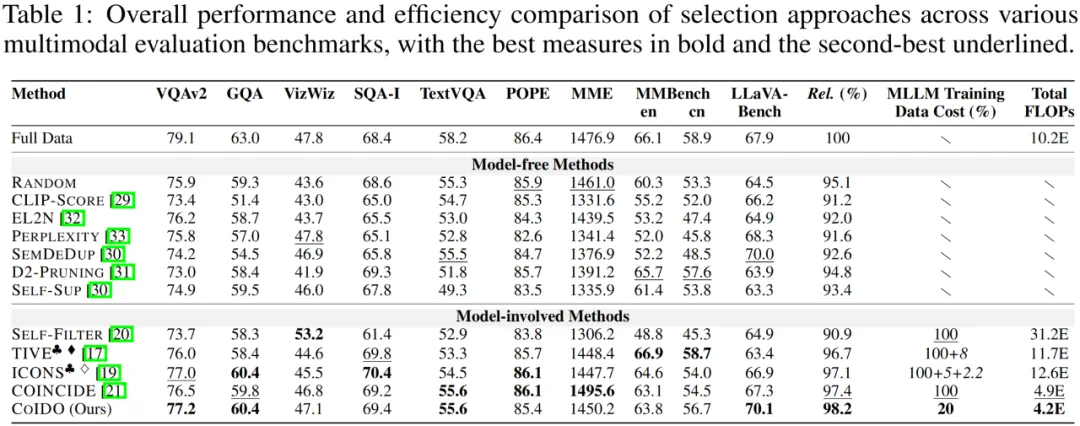
1. 性能与效率的双重 SOTA:实验结果表明,COIDO 仅利用 20% 的数据进行训练和筛选,即可达到全量数据微调 98.2% 的平均性能。与现有的 SOTA 方法(如 ICONS、TIVE、COINCIDE)相比:
计算效率最高:COIDO 拥有最低的 Total FLOPs (4.2E),显著优于需要全量遍历的方法。
筛选质量最优:在相同的数据留存率下,COIDO 在各个 Benchmark 上均取得了极具竞争力的结果。

2. 强大的泛化性与迁移性:将在 LLaVA-665K 上训练好的 COIDO Scorer 直接应用于 Vision-Flan 数据集(Zero-shot Transfer),其表现甚至优于在该数据集上从头训练的评分器,证明了 COIDO 能够学习到通用的数据价值评估标准。
06 总结 (Conclusion)
COIDO 提供了一种全新的多模态数据筛选范式。它打破了「数据筛选必须昂贵」的刻板印象,证明了通过耦合优化和小样本学习,我们可以「以简驭繁」,用极小的计算代价精准定位高价值的视觉指令数据。这不仅为资源受限的研究者提供了高效微调 MLLM 的可能,也为未来大规模多模态数据的自动化清洗与治理提供了新的思路。
关注项目主页获取更多细节与代码实现!


