基于海量数据训练得到的大语言模型(LLM)表现出强大的推理和解决问题的能力,但也深受海量数据带来的敏感信息(隐私、安全、伦理问题)困扰。机器反学习(Unlearning)旨在准确擦除目标知识,同时保持模型在其他目标任务上的能力。基于损失加权方法的诸多探索已表现出对于LLM反学习的益处,然而,它们的具体功能并不明确,最佳策略也是一个悬而未决的问题,因此阻碍了对现有方法的理解和改进。因此,香港浸会大学与悉尼大学、香港理工大学合作发表论文《Exploring Criteria of Loss Reweighting to Enhance LLM Unlearning》,深入探索和讨论了现有方法的效用本质,填补了加权去学习的研究空白,明确训练时诸多设定细节对模型性能的影响。基于以上发现,该论文提出了一种SatImp方法,更好地实现了大语言模型在知识遗忘和知识保存间的平衡。
论文已在ICML 2025发表:

论文标题:Exploring Criteria of Loss Reweighting to Enhance LLM Unlearning
论文链接:https://www.arxiv.org/abs/2505.11953
项目代码:https://github.com/tmlr-group/SatImp
引言
大型语言模型(LLMs)的卓越功能基于对源于网络的大规模数据集的使用。然而,这些数据集也带来了巨大的风险,因为它们可能隐含非法、隐私、敏感内容,导致潜在的法律和伦理风险。因此,研究者们提出了反学习(LLM Unlearning)这一问题,意图在不完全重新训练的条件下,针对性删除已参数化的不良知识,同时尽可能保持模型在其他任务上的性能。
在已有的探索方法中,梯度上升(Gradient Ascent,GA)方法作为经典的反学习方法,简单有效但易出现过度遗忘,即不但遗忘了不良知识,还遗忘了其他任务的知识。为了改善这一缺陷,近期的诸多探索,如负偏好优化(Negative Preference Optimization,NPO)、偏好优化(Preference Optimization,PO),表征误导遗忘(Representation Misdirection for Unlearning,RMU),加权梯度上升(Weighted Gradient Ascent,WGA)等,均通过在损失计算中添加权重实现改进。然而,这些加权机制发挥效能的具体原因上不明确,最优加权的发展方向仍然模糊,这些函待解决的问题迟滞了深层理解和提升相关技术的步伐。
为解决以上问题,作者首先总结现有损失加权机制,并将其总结为“基于饱和度的加权”:
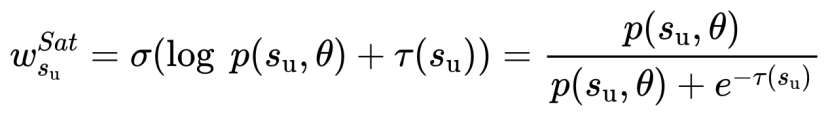
公式一 基于饱和度的加权方法
如公式1所示,现有方法均为该式的子式,当阈值 为一个受原始模型和遗忘模型影响的变量时,公式1可具体为任一现有方法,例如负偏好优化(Negative Preference Optimization,NPO):
为一个受原始模型和遗忘模型影响的变量时,公式1可具体为任一现有方法,例如负偏好优化(Negative Preference Optimization,NPO):
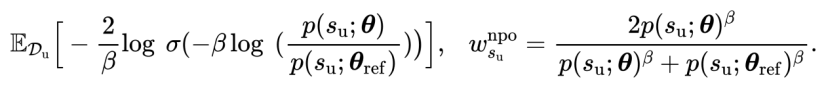
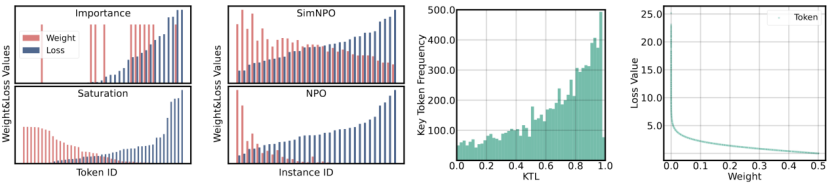
“基于饱和度的加权”通过表示所有遗忘单元(样本或单词)的遗忘程度并以之为权重,强调了对未充分遗忘单元的重点优化。然而,另一种加权机制认为,不是所有的遗忘单元都需要被遗忘,如图1所示,红色单词为该答案的关键词,人类无法理解关键词缺失下的答案。因此,只需完成对于关键词的遗忘即可。令人遗憾的是,现有方法忽略了这一“基于重要性的加权”方向。

本工作历史首次探索了“基于重要性的加权”方向,具体的,考虑到现有评测基准不包含关键词标注,本工作首先在常用的TOFU数据集上完成了相关标注。进一步的,考虑到在海量数据上完成标注费时费力,本工作尝试寻找一种近似表示。如图2所示,在对权重和负对数似然的相关性的探索中,一个令人惊喜的结论浮出水面:“基于饱和度的加权”倾向于将更大的权重分配给更小的负对数似然,“基于重要性的加权”则相反。
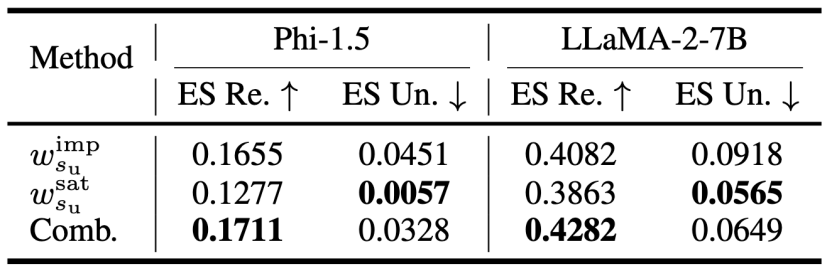
基于上述初步探索,本工作力求寻找更优的加权方向。首先,本工作对比两种加权方向的性能差异,如表1所示,“基于饱和度的加权”通常优于“基于重要性的加权”,且二者联合能取得更优的性能。
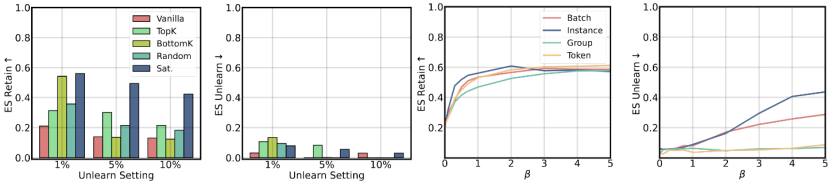
其次,本工作探索不同训练细节(包括平滑度、采样方式、颗粒度)对于训练结果的影响,如图3所示,使用软加权(左一、二)和更细粒度(右一、二)的训练策略是被推荐的。平滑度则须控制在一定范围内,否则将导致显著的欠/过遗忘问题(右一、二)。
最后,本工作提出一种新的加权方法SatImp,如式2所示,
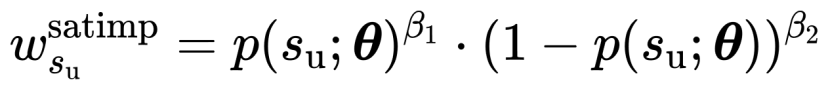
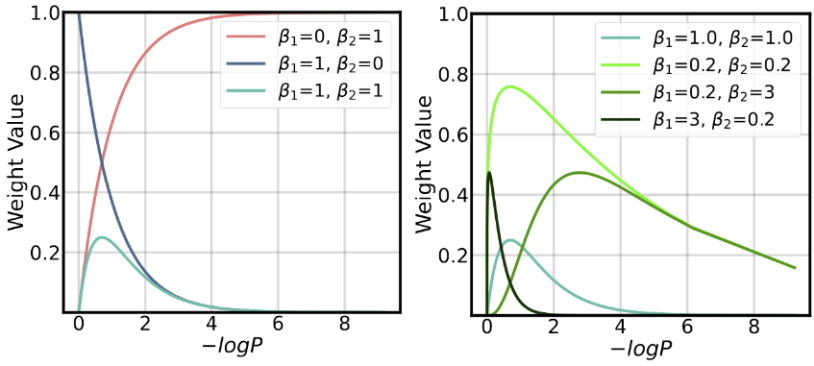
SatImp结合了饱和度、重要性的加权思想。不同于现有方法过度强调极大极小损失(图4左红色蓝色线),SatImp着重强调了负对数似然值居中的token(图4左绿色线)。双超参数也给SatImp带来了更多元的权重表示,有助于在不同场景需求下提供更优的权重选择(图4右)。
在多个测试基准上的实验结果表明了SatImp的优越性和泛化性。如表2,3所示,作者希望本工作能够带给大语言模型去学习一个全新的视角,吸引更多研究者对“基于重要性的加权”方向和“饱和度-重要性”结合方向进行深入探索,共同推动可信大语言模型的进一步发展。
课题组介绍
香港浸会大学可信机器学习和推理课题组 (TMLR Group) 由多名青年教授、博士后研究员、博士生、访问博士生和研究助理共同组成,课题组隶属于理学院计算机系。课题组专攻可信基础模型、可信表征学习、基于因果推理的可信学习等相关的算法,理论和系统设计以及在自然科学上的应用,具体研究方向和相关成果详见本组 Github https://github.com/tmlr-group。
课题组由政府科研基金以及工业界科研基金资助,如香港研究资助局新进学者协作研究补助金、优配研究金和杰出青年学者计划,国家自然科学基金面上项目和青年项目,以及微软、英伟达、字节跳动、百度、阿里、腾讯等企业的教职科研基金。青年教授和资深研究员手把手带,GPU 计算资源充足,长期招收多名博士后研究员、博士生、研究助理和研究实习生。此外,本组也欢迎自费的访问博士后研究员、博士生和研究助理申请,访问至少 3-6 个月,支持远程访问。有兴趣的同学请发送个人简历和初步研究计划到邮箱[email protected]。


