henry 发自 凹非寺
量子位 | 公众号
继今年5月提出MeanFlow (MF) 之后,何恺明团队于近日推出了最新的改进版本——
Improved MeanFlow (iMF),iMF成功解决了原始MF在训练稳定性、指导灵活性和架构效率上的三大核心问题。

其通过将训练目标重新表述为更稳定的瞬时速度损失,同时引入灵活的无分类器指导(CFG)和高效的上下文内条件作用,大幅提升了模型性能。
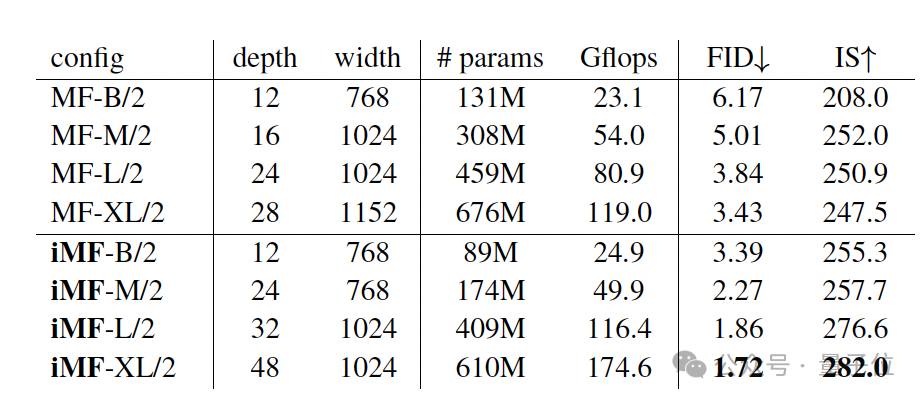
在ImageNet 256×256基准测试中,iMF-XL/2模型在 1-NFE(单步函数评估)中取得了1.72的FID成绩,相较于原始MF提升了50%,证明了从头开始训练的单步生成模型可以达到与多步扩散模型相媲美的结果。
MeanFlow一作耿正阳依旧,值得注意的是共同一作的Yiyang Lu目前还是大二学生——来自清华姚班,而何恺明也在最后署了名。
其他合作者包括:Adobe研究员Zongze Wu、Eli Shechtman,及CMU机器学习系主任Zico Kolter。
iMF (Improved MeanFlow) 的核心改进是通过重构预测函数,将训练过程转换为一个标准的回归问题。
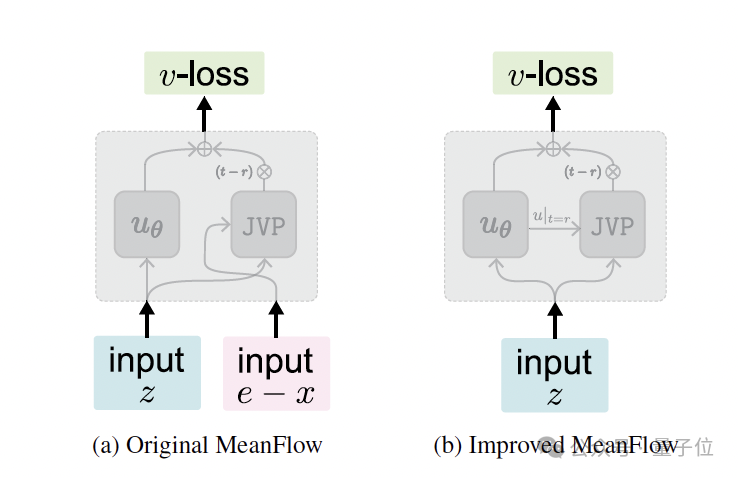
在原始的MeanFlow (MF) (上图左)中,其直接最小化平均速度的损失。其中,Utgt是根据MeanFlow恒等式和条件速度e-x推导出来的目标平均速度。
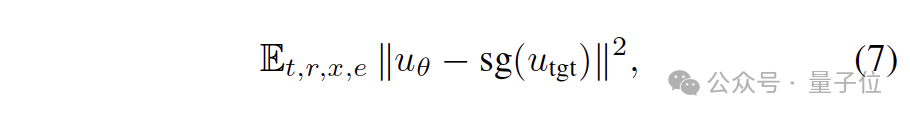
这里的问题在于,推导出来的目标Utgt包含网络自身预测输出的导数项,而这种“目标自依赖”的结构使得优化极不稳定、方差极大。
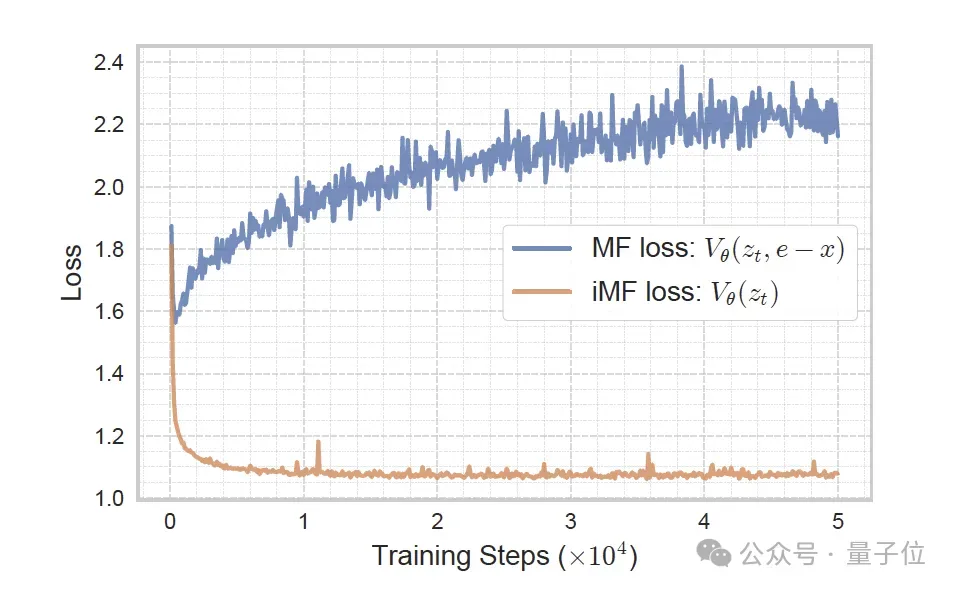
基于此,iMF从瞬时速度的角度去构建损失,使整个训练就变得稳定。
值得注意的是,网络输出仍然是平均速度,而训练损失则变成了瞬时速度损失,以获得稳定的、标准的回归训练。
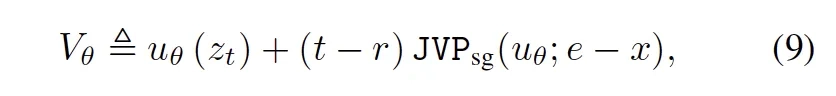
它首先将输入简化为单一的含噪数据z,并在内部巧妙地修改了预测函数的计算方式。
具体来说,iMF让用于计算复合预测函数V(代表对瞬时速度的预测)中,雅可比向量积(JVP)项所需的切向量输入不再是外部的e-x,而是由网络自身预测的边缘速度。
通过这一系列步骤,iMF成功移除了复合预测函数V对目标近似值e-x的依赖。此时,iMF再将损失函数的目标设定为稳定的条件速度e-x。
最终,iMF 成功将训练流程转换成了一个稳定的、标准的回归问题,为平均速度的学习提供了坚实的优化基础。
除了对训练目标进行改良外,iMF还通过以下两大突破,全面提升了MeanFlow框架的实用性和效率:
灵活的无分类器指导(CFG)。
原始MeanFlow框架的一大局限是:为了支持单步生成,无分类器指导(CFG)的指导尺度在训练时必须被固定,这极大地限制了在推理时通过调整尺度来优化图像质量或多样性的能力。
iMF通过将指导尺度内化为一个可学习的条件来解决此问题。
具体来说,iMF直接将指导尺度作为一个输入条件提供给网络。
在训练阶段,模型会从一个偏向较小值的幂分布中随机采样不同的指导尺度。这种处理方式使得网络能够适应并学习不同指导强度下的平均速度场,从而在推理时解锁了CFG的全部灵活性。
此外,iMF 还将这种灵活的条件作用扩展到支持CFG区间,进一步增强了模型对样本多样性的控制。
高效的上下文内条件作用(In-context Conditioning)架构
原始MF依赖于参数量巨大的adaLN-zero机制来处理多种异构条件(如时间步、类别标签和指导尺度)。
当条件数量增多时,简单地对所有条件嵌入进行求和并交给adaLN-zero处理,会变得效率低下且参数冗余。
iMF引入了改进的上下文内条件作用来解决此问题。
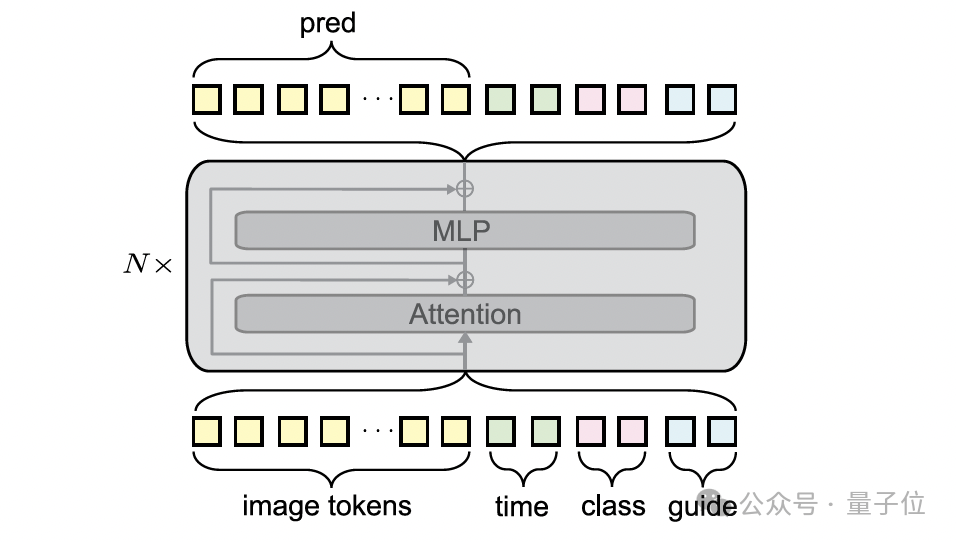
它的创新点在于:它将所有条件(包括时间步、类别以及 CFG 因子等)编码成多个可学习的Token(而非单一向量),并将这些条件Token直接沿序列轴与图像潜在空间的Token进行拼接,然后一起输入到 Transformer 块中进行联合处理。
这一架构调整带来的最大益处是:iMF可以彻底移除参数量巨大的adaLN-zero模块。
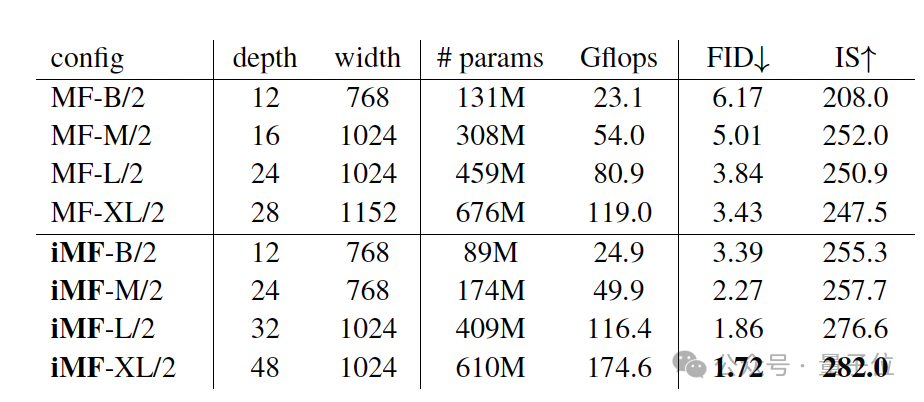
这使得iMF在性能提升的同时,模型尺寸得到了大幅优化,例如 iMF-Base 模型尺寸减小了约1/3(从 133M 降至 89M),极大地提升了模型的效率和设计灵活性。
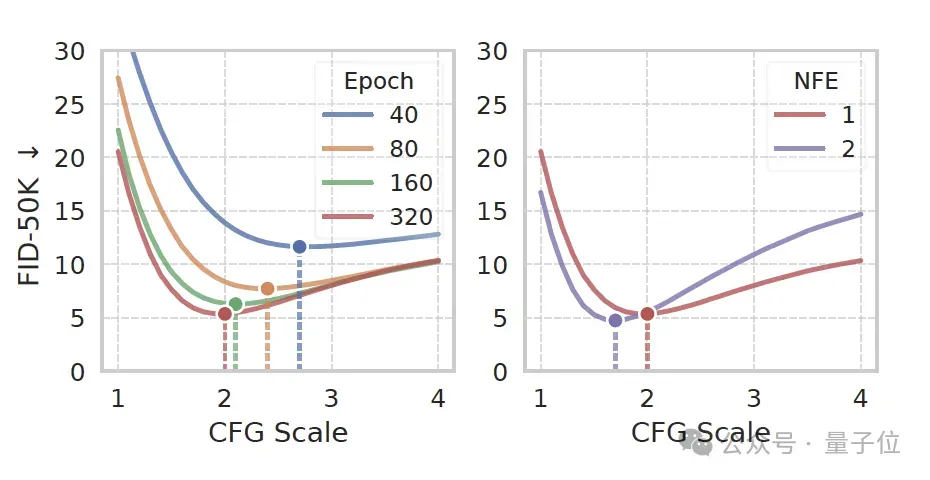
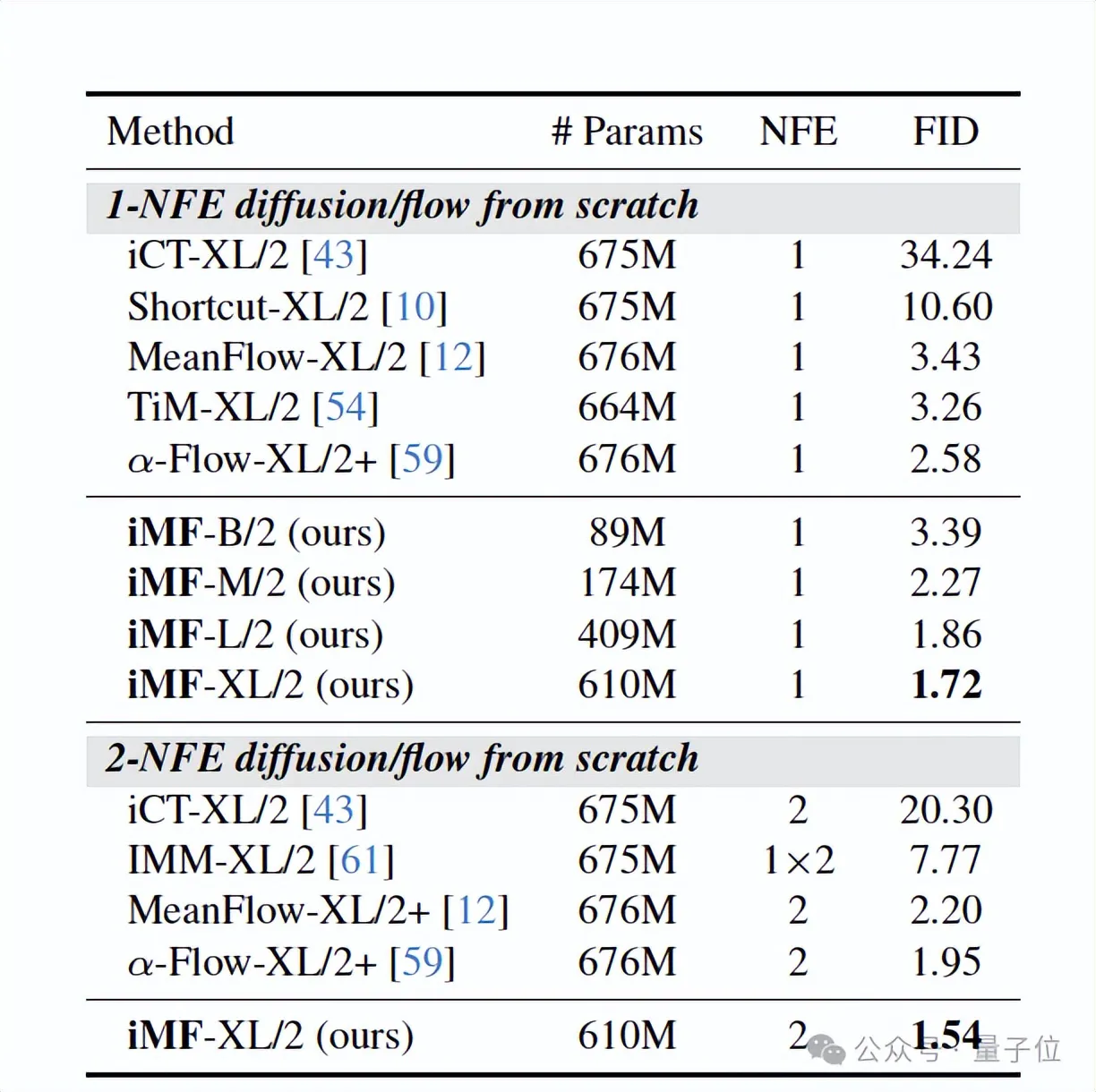
iMF在最具挑战性的ImageNet 256×256上的1-NFE中展示了卓越的性能。
iMF-XL/2在1-NFE下的FID达到了1.72,将单步生成模型的性能推到了一个新的高度。
iMF从头开始训练的性能甚至优于许多从预训练多步模型中蒸馏而来的快进模型,证明了 iMF 框架在基础训练上的优越性。
下图在ImageNet 256×256上进行1-NFE(单步函数评估)生成的结果。

iMF在2-NFE时的FID达到1.54,将单步模型与多步扩散模型(FID约1.4-1.7)的差距进一步缩小。
如前文所述,IMF 一作延续前作Mean Flow(已入选 NeurIPS 2025 Oral)的核心班底——耿正阳。
他本科毕业于四川大学,目前在CMU攻读博士,师从Zico Kolter教授。

共一作者为清华姚班大二学生Yiyang Lu,现于MIT跟随何恺明教授研究计算机视觉,此前曾在清华叉院许华哲教授指导下研究机器人方向。

这篇论文部分的内容由他们在MIT期间,于何恺明教授指导下完成。
此外,论文的其他作者还包括:Adobe研究员Zongze Wu、Eli Shechtman,CMU机器学习系主任J. Zico Kolter以及何恺明教授。
其中,Zongze Wu本科毕业于同济大学,并在Hebrew University of Jerusalem获得博士学位,他目前在Adobe旧金山研究院担任研究科学家,

同样的,Eli Shechtman也同样来自Adobe,他是Adobe Research图像实验室的高级首席科学家。他于2007加入 Adobe,并于2007–2010年间在华盛顿大学担任博士后研究员。

J. Zico Kolter是论文一作耿正阳的导师,他是CMU计算机科学学院教授,并担任机器学习系主任。

论文的尾作则是著名的机器学习科学家何恺明教授,他目前是MIT的终身副教授。
他最出名的工作是ResNet,是21世纪被引用次数最多的论文。

就在最近的NeurIPS放榜中,何恺明参与的FastCNN还拿下了时间检验奖。
参考链接;
[1]https://arxiv.org/pdf/2505.13447
[2]https://gsunshine.github.io/
[3]https://arxiv.org/pdf/2512.02012