近日,上海人工智能实验室(上海 AI 实验室)开源了生成式世界模型 AETHER。该模型全部由合成数据训练而成,不仅在传统重建与生成任务中表现领先,更首次赋予大模型在真实世界中的 3D 空间决策与规划能力,可助力机器人完成目标导向的视觉规划、4D 动态重建、动作条件的视频预测等复杂任务。
研究团队将几何重建与生成式建模深度融合,首创「重建 — 预测 — 规划」 一体化框架,通过 AETHER 使大模型能够感知周围环境,理解物体之间的位置、运动和因果关系,从而做出更智能的行动决策。
实验表明,传统世界模型通常聚焦于 RGB 图像的预测而忽略了背后隐含的几何信息,引入空间建模后,各项指标均显著提升,其中视频一致性指标提升约 4%。更重要的是,即使只使用合成数据进行训练,模型在真实环境中依然展现出强大的零样本泛化能力。
论文与模型已经同步开源。

论文标题:AETHER: Geometric-Aware Unified World Modeling
论文链接:https://arxiv.org/abs/2503.18945
项目主页:https://aether-world.github.io
 三大核心技术 攻克动态环境中的智能决策困境
三大核心技术 攻克动态环境中的智能决策困境
传统世界模型主要应用于自动驾驶与游戏开发等领域,通过其丰富的动作标签来预测接下来的视觉画面。
但由于缺乏对真实三维空间的建模能力,这容易导致模型预测结果出现不符合物理规律的现象。同时,由于依赖且缺乏真实数据,面对更复杂多变的场景时,其泛化能力也明显不足。
针对以上问题,研究团队提出了生成式世界模型 AETHER,基于三维时空建模,通过引入并构建几何空间,大幅提升了模型空间推理的准确性与一致性。
具体而言,研究团队利用海量仿真 RGBD 数据,开发了一套完整的数据清洗与动态重建流程,并标注了丰富的动作序列。同时,他们提出一种多模态数据的动态融合机制,首次将动态重建、视频预测和动作规划这三项任务融合在一个统一的框架中进行优化,从而实现了真正的一体化多任务协同,大幅提高了模型的稳定性与鲁棒性。
面对复杂多变的现实世界,如何让具身智能系统实现可靠、高效的决策是人工智能领域的一项重大挑战。研究团队在 AETHER 框架中通过三项关键技术突破,显著提升了具身系统在动态环境中的感知、建模与决策能力。
目标导向视觉规划:可根据起始与目标场景,自动生成一条实现视觉目标的合理路径,并以视频形式呈现全过程。通过联合优化重建与预测目标,AETHER 内嵌空间几何先验知识,使生成结果兼具物理合理性。这使得具身智能系统能像人类一样「看路规划」—— 通过摄像头观察环境后,自动生成既安全又符合物理规律的行动路线。
4D 动态重建:通过自动标注流水线,构建合成 4D 数据集,无需真实世界数据即可实现零样本迁移,精准捕捉并重建时空环境的动态变化。例如,输入一段街景视频,系统即可重建包含时间维度的三维场景模型,精确呈现行人行走、车辆运动等动态过程,建模精度可达毫米级。
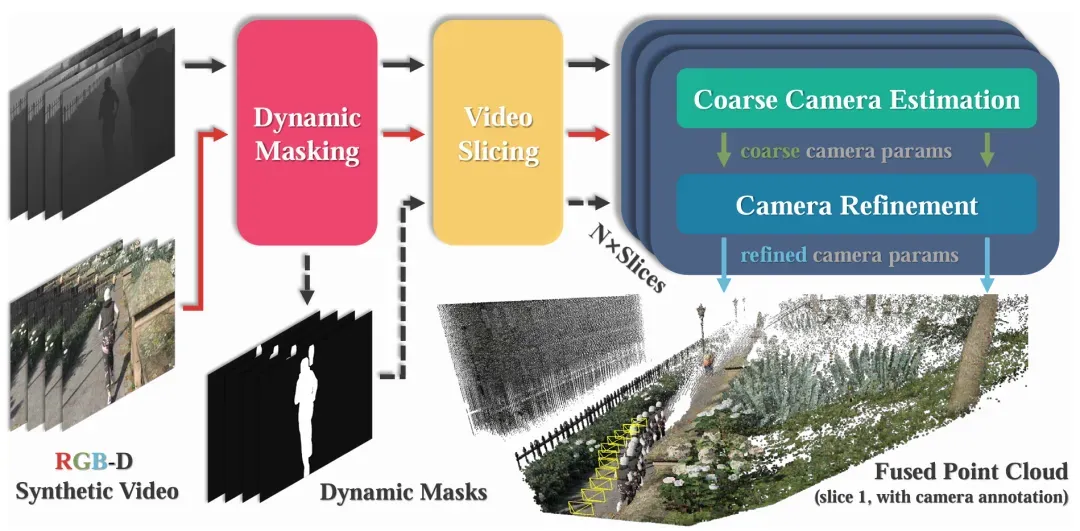
自动相机标注 pipeline。
动作条件视频预测:创新性地采用相机轨迹作为全局动作表征,可直接基于初始视觉观察和潜在动作,预测未来场景的变化趋势。相当于给具身智能系统装上了预测未来的「镜头」。
可零样本泛化至真实场景
不同于传统仅预测图像变化的世界模型,AETHER 不仅能同时完成四维时空的重建与预测,还支持由动作控制驱动的场景推演与路径规划。值得强调的是,该方法完全在虚拟数据上训练,即可实现对真实世界的零样本泛化,展现出强大的跨域迁移能力。
具体流程如下图所示,图中黄色、蓝色和红色分别表示图像、动作与深度的潜在变量,灰色表示噪声项,白色框为零填充区域。模型通过组合不同的条件输入(如观察帧、目标帧和动作轨迹),结合扩散过程,实现对多种任务的统一建模与生成。
就像在拼一副完整的动态拼图,观察帧提供了「现在的样子」,目标帧给出了「未来的样子」,动作轨迹则是「怎么从这里走到那里」,而扩散过程则像是拼图的拼接逻辑,把这些零散信息有序组合起来,最终还原出一个连续、合理且可预测的时空过程。
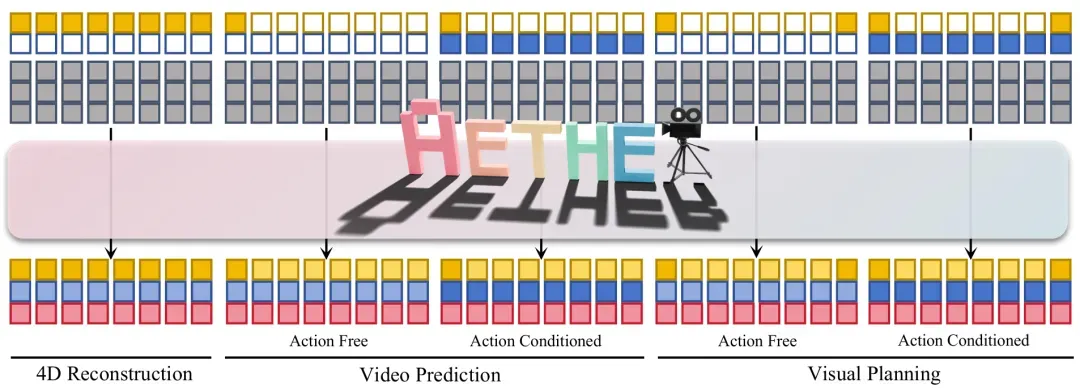
为了支持同时完成重建、预测和规划这三类不同任务,AETHER 设计了一种统一的多任务框架,首次实现在同一个系统中整合动态重建、视频预测和动作规划。
其核心在于:能够融合图像、动作、深度等多模态信息,建立一个跨模态共享的时空一致性建模空间,实现不同任务在同一认知基础上的协同优化。
实验结果
在多个实验任务中,AETHER 在动态场景重建方面已达到甚至超过现有 SOTA 水平。同时发现在多任务框架下,各个任务有很好的促进,尤其在动作跟随的准确度上面有较大的提升。
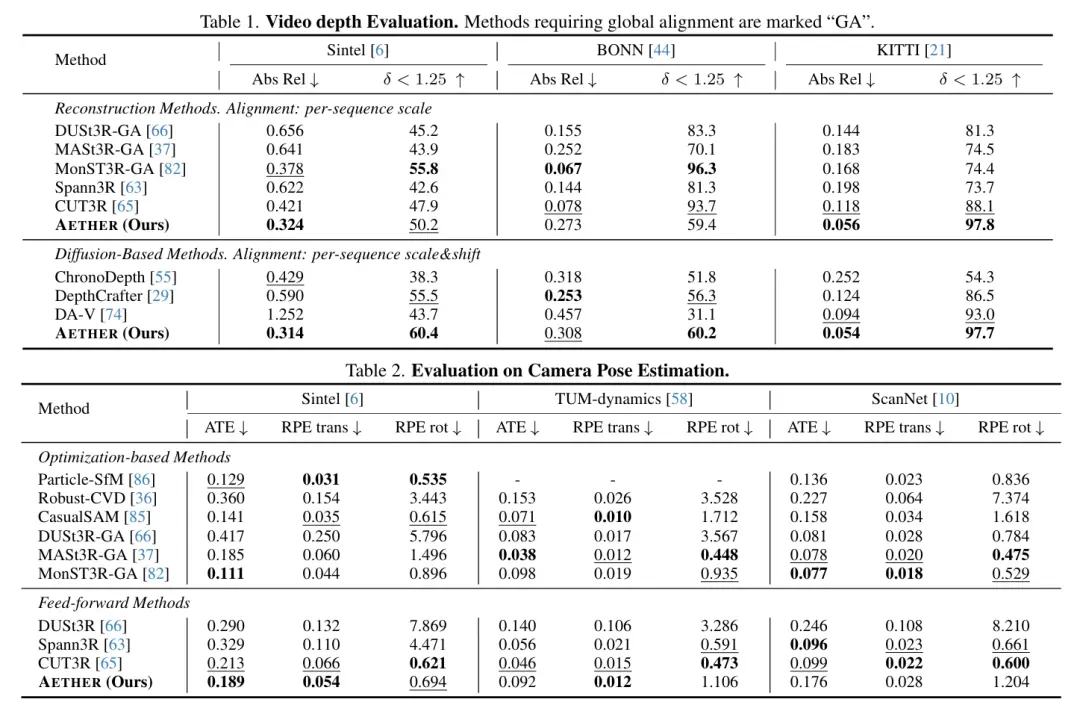
该方法有望为具身智能大模型在数据增强、路径规划以及基于模型的强化学习等方向研究提供技术支撑。


