1. 一眼概览:
H-MBA (Hierarchical MamBa Adaptation) 提出了一个创新的多模态视频理解框架,通过结合高低时域分辨率,显著提升了自动驾驶场景中的视频理解和风险物体检测性能。
2. 核心问题:
现有的多模态大语言模型(MLLMs)在处理自动驾驶中复杂的时空动态视频时,性能有限。特别是在捕捉背景变化、车辆和行人运动等方面,现有方法难以做到准确的时空理解。
3. 技术亮点:
- 引入了层次化的MamBa模型,通过高低时域分辨率分支捕捉视频中多粒度的时空特征。
- 提出了Q-Mamba(查询MamBa),通过灵活地转换当前帧为查询并适应性地整合多粒度视频上下文。
- 在DRAMA和BDD-X数据集上取得了领先的性能,特别是在风险物体检测任务中,相比现有最先进方法提升了5.5%的mIoU。
4. 方法框架:
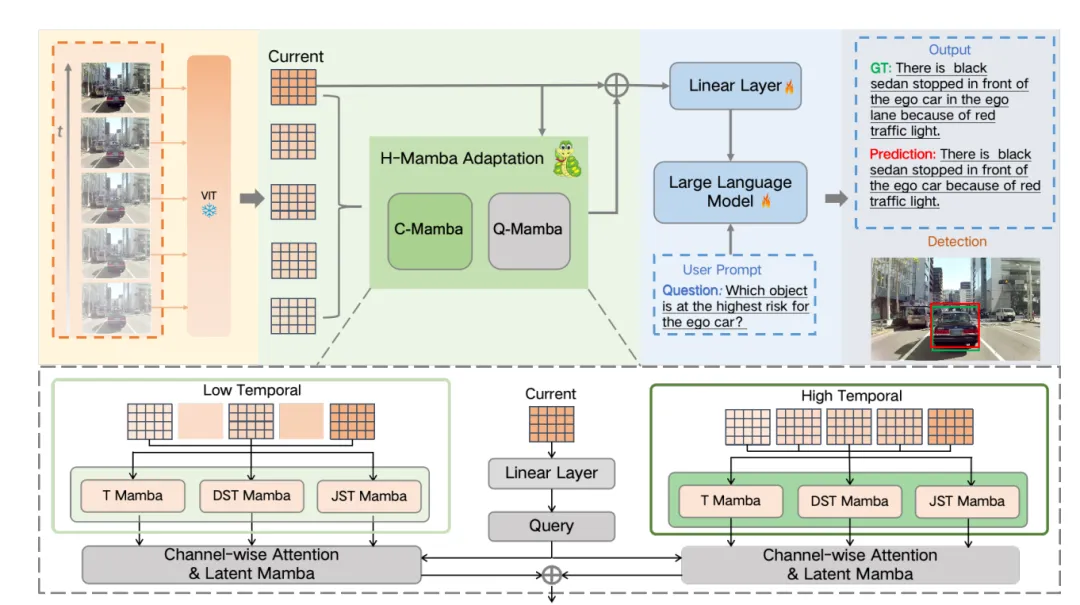
H-MBA框架由两大模块组成:
• Context Mamba (C-Mamba):使用不同时间分辨率的时空模型来捕获视频的多层次上下文,包括低分辨率分支和高分辨率分支,分别捕捉明显的运动变化和细节信息。
• Query Mamba (Q-Mamba):生成可学习的查询并适应性地整合来自C-Mamba的多粒度上下文,增强对视频的时空理解。
5. 实验结果速览:
- • 在DRAMA数据集上,H-MBA在风险物体定位任务上取得了66.9%的mIoU,比最先进的LCP方法提高了5.5%。
- • 在BDD-X数据集上,H-MBA在描述和解释任务中超越了BLIP-2、Video-Chat等方法,并在多个性能指标上表现优越。
6. 实用价值与应用:
H-MBA的设计使其具有强大的实际应用潜力,特别是在自动驾驶领域。其对复杂驾驶场景的高效理解和风险物体检测功能可显著提升自动驾驶系统的安全性和交互性,具有广泛的商业应用前景。
7. 开放问题:
• 如何应对在极为复杂或不连续的相机运动下,H-MBA的表现是否依然稳定?
• 是否可以将层次化的MamBa结构扩展到其他领域的时空建模任务中,例如医学影像分析或工业自动化?


