谷歌 DeepMind 的研究团队近日推出了 Gemma Scope2,这是一个开放的可解释性工具套件,旨在深入了解 Gemma3语言模型在各层次上的信息处理和表现,涵盖从2.7亿到270亿参数的模型。
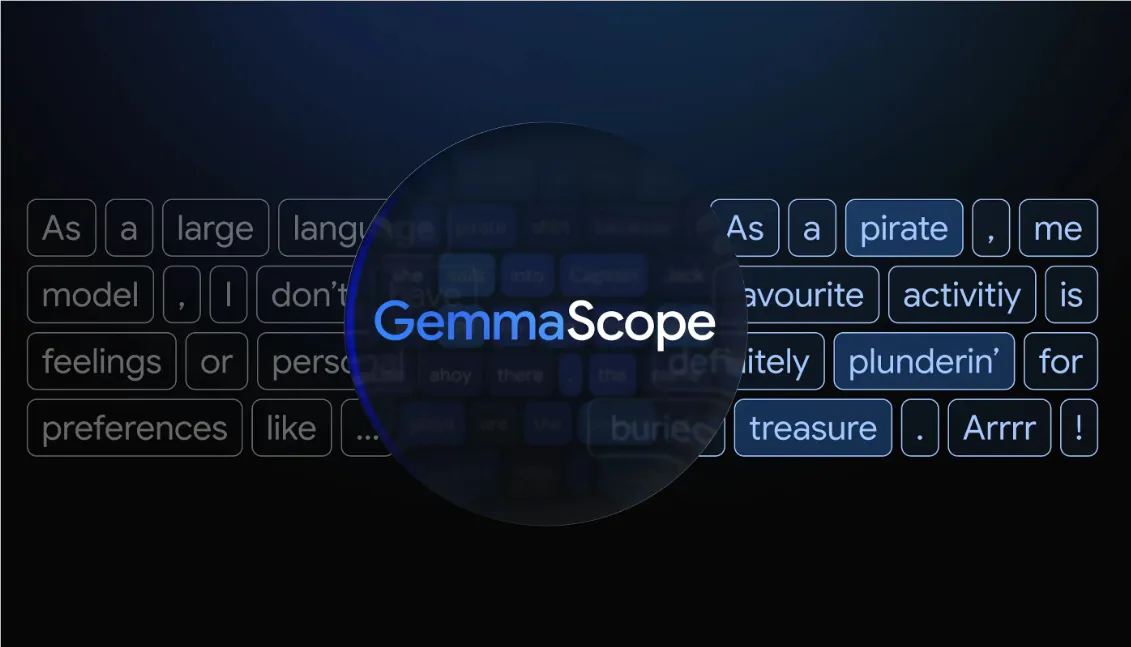
该工具的核心目标是为人工智能安全与对齐团队提供一种实用的方法,以便追踪模型行为回到内部特征,而不仅仅依赖输入与输出的分析。当 Gemma3模型出现 “越狱”、幻觉或表现出拍马屁的行为时,研究人员可以利用 Gemma Scope2检查哪些内部特征被激活以及这些激活在网络中的流动情况。
Gemma Scope2是一个全面的、开放的稀疏自编码器和相关工具的集合,专门训练于 Gemma3模型系列的内部激活。稀疏自编码器(SAE)就像一台显微镜,将高维激活分解为一组稀疏的人类可检视特征,这些特征对应于概念或行为。Gemma Scope2的训练需要存储大约110PB 的激活数据,并在所有可解释性模型中适配超过1万亿的总参数。
与之前的 Gemma Scope 相比,Gemma Scope2在四个主要方面进行了扩展。首先,该工具涵盖了整个 Gemma3系列,支持最大至270亿参数的模型,特别适用于研究在较大规模模型中观察到的突现行为。
其次,Gemma Scope2包含训练于 Gemma3每一层的稀疏自编码器和转码器,帮助追踪跨层的多步骤计算。此外,新的 “马特 ryoshka” 训练技术的应用,使得稀疏自编码器能够学习更有用和稳定的特征,减少了早期版本中的一些缺陷。最后,该套件为针对聊天的 Gemma3模型提供了专用的可解释性工具,使得分析诸如越狱、拒绝机制和思维链信度等多步骤行为成为可能。
项目介绍:https://deepmind.google/blog/gemma-scope-2-helping-the-ai-safety-community-deepen-understanding-of-complex-language-model-behavior/
划重点:
🔍 Gemma Scope2是一个开放的可解释性工具套件,支持从2.7亿到270亿参数的 Gemma3模型。
🛠️ 新版本的工具包括稀疏自编码器和转码器,帮助分析模型的内部特征和行为。
🔒 该工具特别适用于人工智能安全领域,能深入研究模型的幻觉、越狱和其他安全相关的行为。