在大语言模型的浪潮中,视频大语言模型(VideoLLMs)正以惊人的速度进化,生成的响应越来越精细。然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。视频序列中海量视觉token导致的二次方复杂度,让处理一个长视频往往需要漫长的等待,尤其在高分辨率或长序列场景下。
为了加速,人们通常会想到token压缩技术—剔除冗余,保留精华。但在视频领域,直接照搬这套逻辑却在视频理解领域翻车了:现有token压缩方法往往采用统一压缩策略,忽略帧间独特视觉信号,导致关键信息丢失、性能崩塌:如图1所示,移除24个冗余帧几乎不影响视频理解准确性,但丢弃仅8个独特帧即导致性能急剧下降,这凸显出视频中帧间信息分布的不均衡性,以及忽略这种差异可能带来的严重后果。
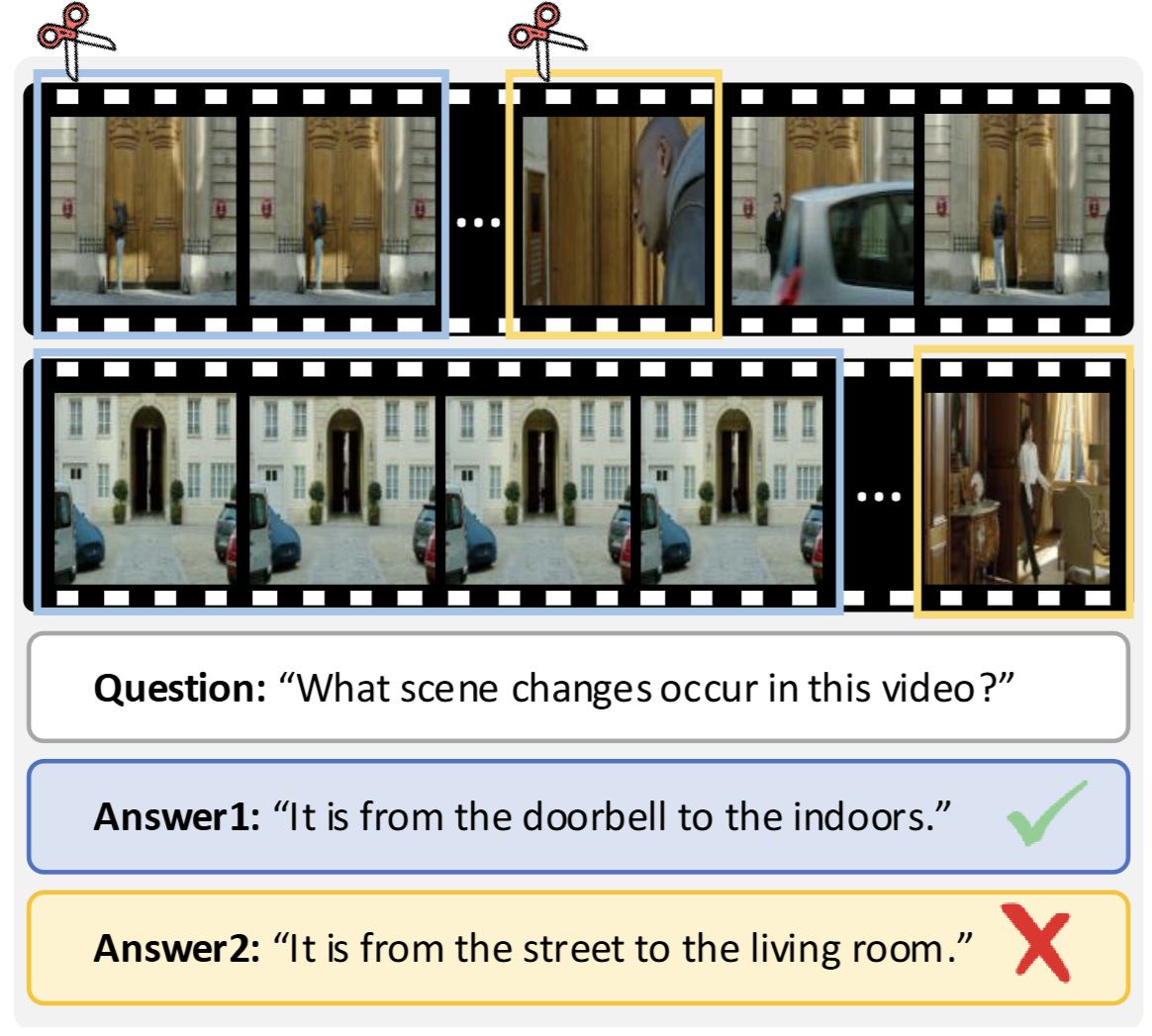
图1. 帧独特性的重要性
此外,现有的一些 token 压缩方法受限于其实现方式,往往依赖过时的 [CLS] token 或显式的注意力权重,难以与现代 SigLIP 编码器和 Flash Attention 兼容,反而导致内存占用激增,甚至适得其反。如图 2 所示,当前框架在处理视频 token 时,既未充分考虑各帧的独特性,也忽视了压缩方法在实际部署中的可行性,难以有效支持 VideoLLM 的即插即用式推理加速。

图2. 现有token压缩方法的问题
于是,上海交通大学EPIC实验室联合四川大学、复旦大学给出了解决方案-“视频压缩指挥官”Video Compression Commander(VidCom²),其可以在 LLaVA-OV 模型上,仅保留 25% token,即可实现 99.6% 原始性能,并减少 70.8% LLM 生成延迟。相关代码均已开源!
论文标题:Video Compression Commander: Plug-and-Play Inference Acceleration for Video Large Language Models
论文机构:上交EPIC Lab、川大、复旦
论文链接:https://arxiv.org/abs/2505.14454
代码链接:https://github.com/xuyang-liu16/VidCom2
核心方法VidCom²框架
本文提出“视频压缩指挥官”Video Compression Commander (VidCom²),一种即插即用推理加速框架,通过量化帧独特性,自适应调整帧级压缩强度,显著降低冗余同时保留关键信息。VidCom² 提炼三大设计原则:模型适应性、帧独特性和高效算子兼容性。
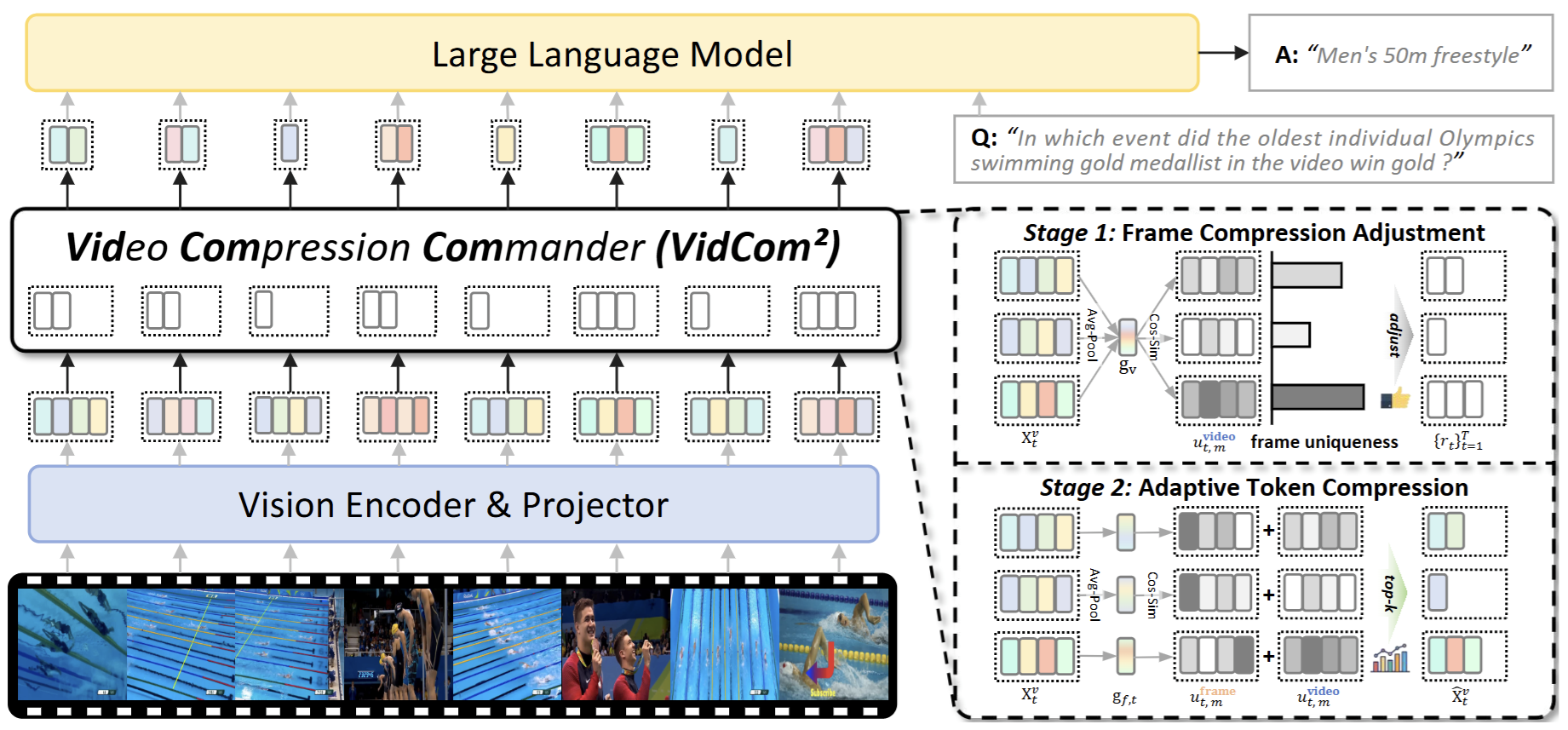
图3. VidCom² 整体框架
VidCom²通过两阶段实现视频 token 压缩:(1)帧级压缩调整,根据帧独特性,动态分配 token 预算,确保独特帧获得更多计算资源;(2)自适应 token 压缩,结合帧内独特性和帧间独特性,以保留最具信息价值的视觉 token。如图 3所示,该框架首先计算全局视频表示,然后通过余弦相似度量化每个帧的独特性分数(图4),并据此调整每帧的保留比率。随后,在第二阶段,结合帧内全局表示和综合独特性分数,自适应选择 token。该设计兼容 Flash Attention,无需额外训练,确保高效集成到 VideoLLM 推理过程中,实现即插即用推理加速。同时,如图 4所示,通过柱状图可视化帧独特性分数(高度和深度表示分数大小),VidCom² 优先为独特帧分配更多 token,与人类感知一致,从而在压缩过程中有效保留关键视觉信号。

图4. 帧独特性可视化
实验结果
在多个基准(如 MVBench、MLVU、VideoMME)和多个 VideoLLM(LLaVA-OV、LLaVA-Video、Qwen2-VL)上,VidCom² 优于 DyCoke、SparseVLM、PDrop等基线。LLaVA-OV-7B上,在 25% Token 保留率下,LLaVA-OV 性能达 99.6%(DyCoke 仅 87.0%);15% 下,领先 SparseVLM 3.9%!
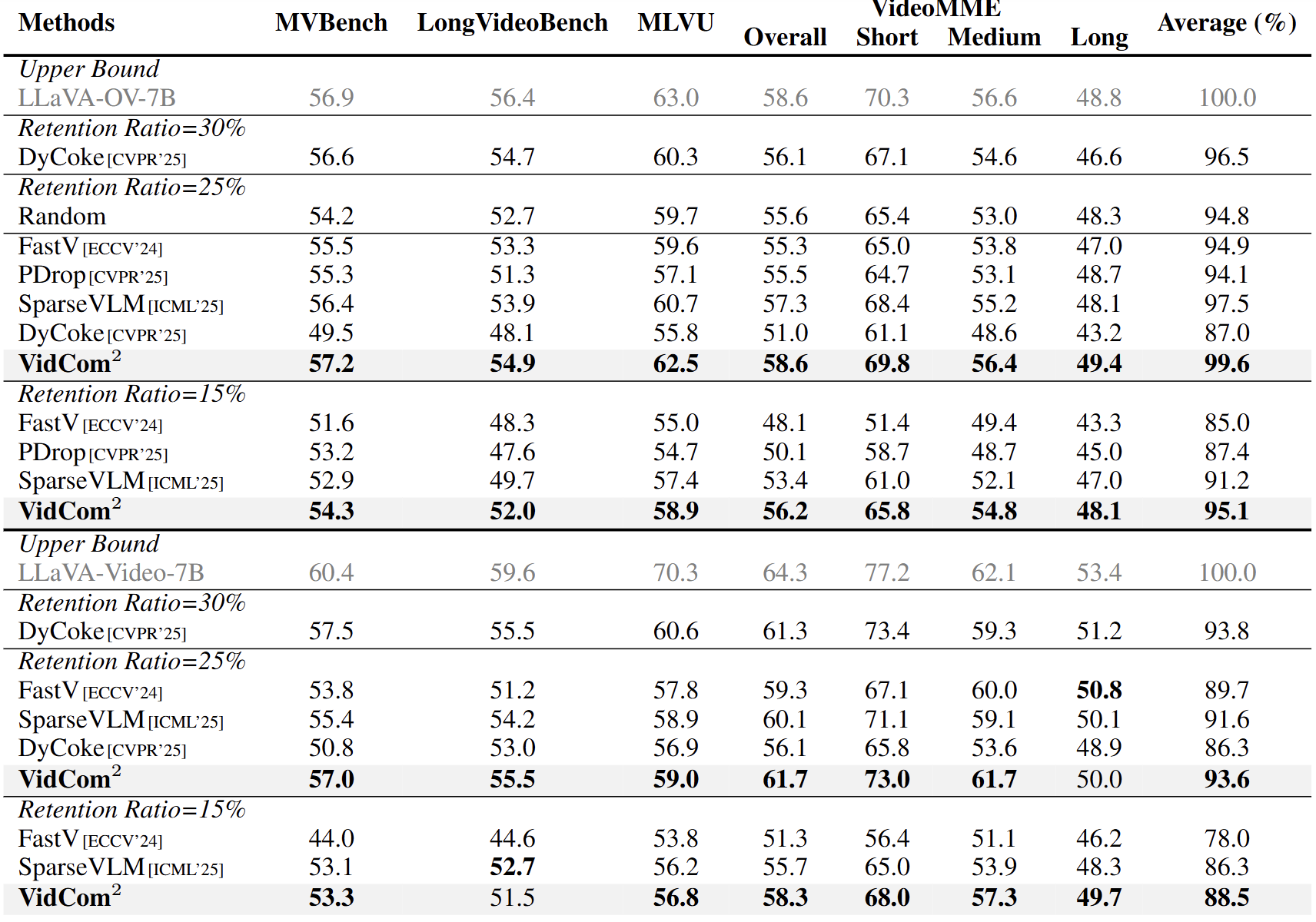
图5. 在 LLaVA 系列模型上的性能对比
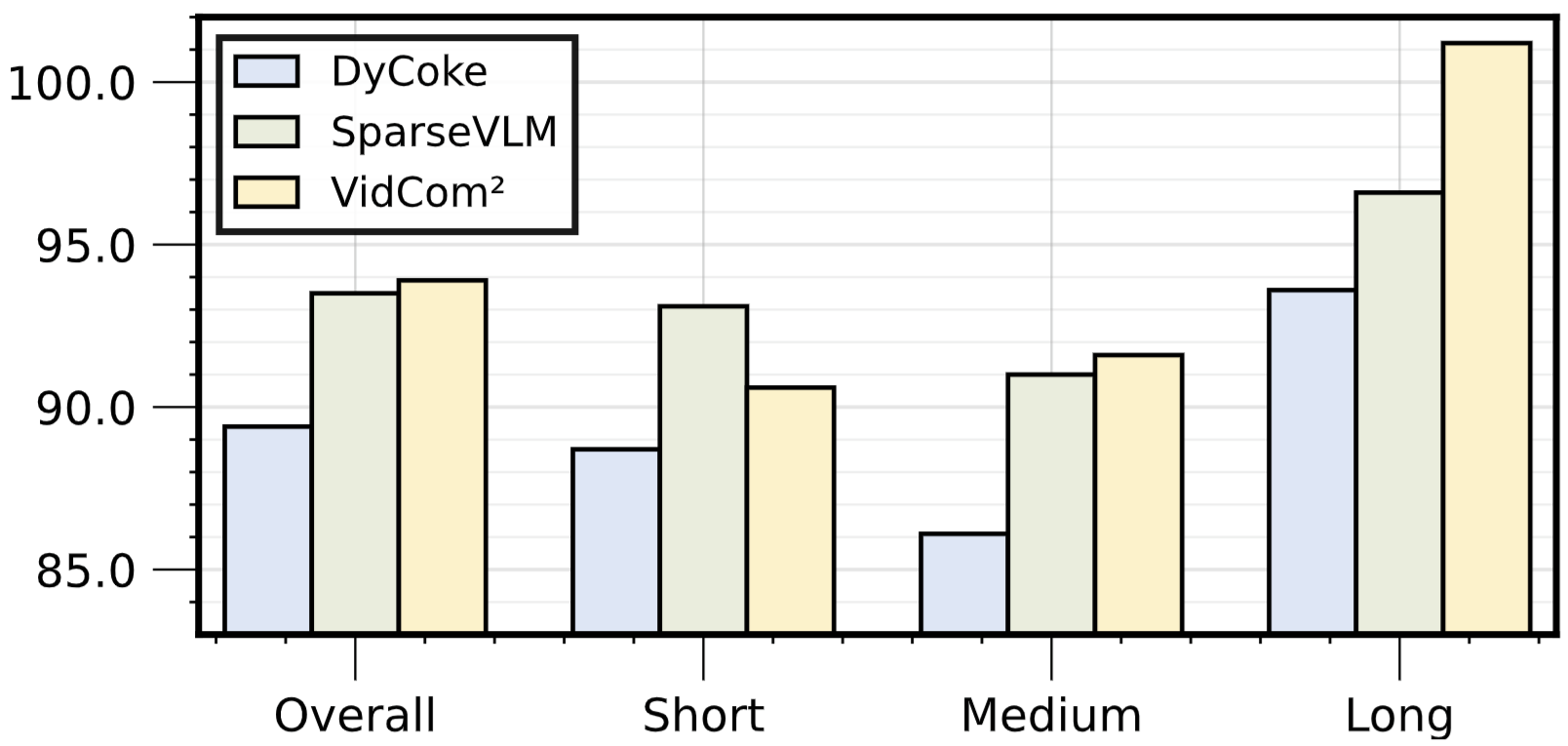
图6. 在 Qwen2-VL 模型上的性能对比
此外,效率测试显示,VidCom² 将 LLM 生成延迟减少 70.8%,吞吐量提升 1.38×,兼容Flash Attention 的同时还可降低峰值显存。
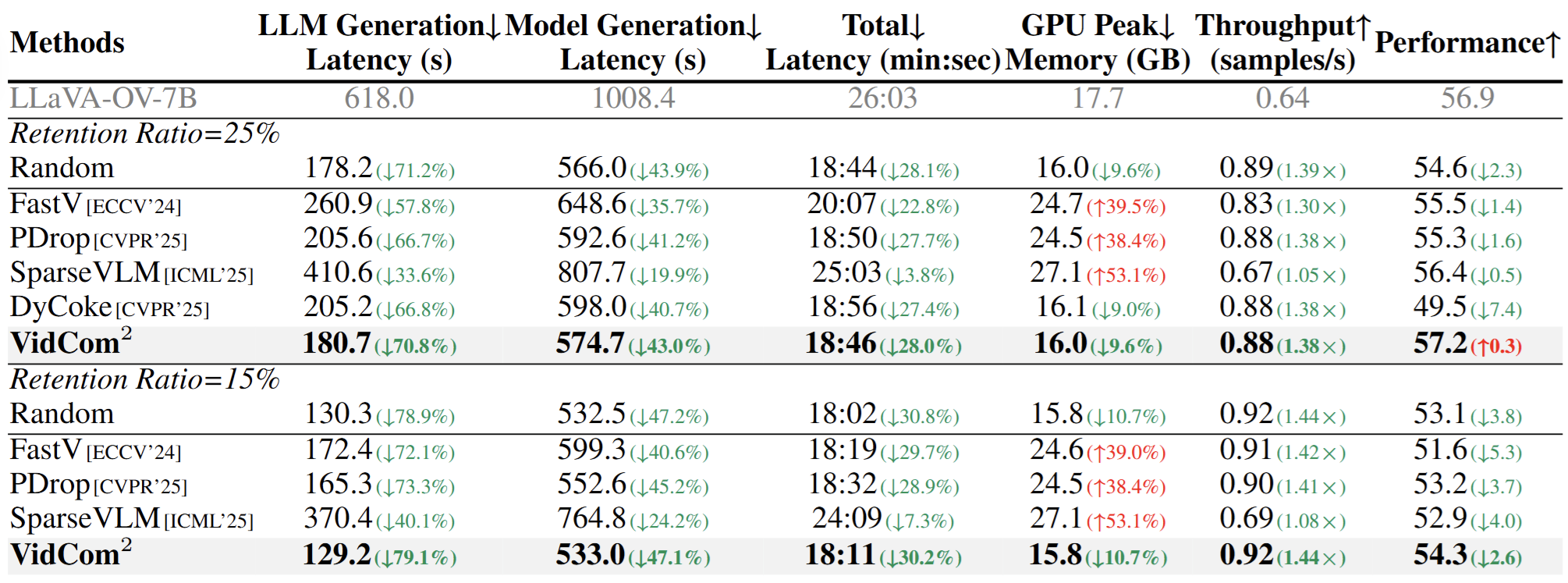
图7. token 压缩效率分析实验
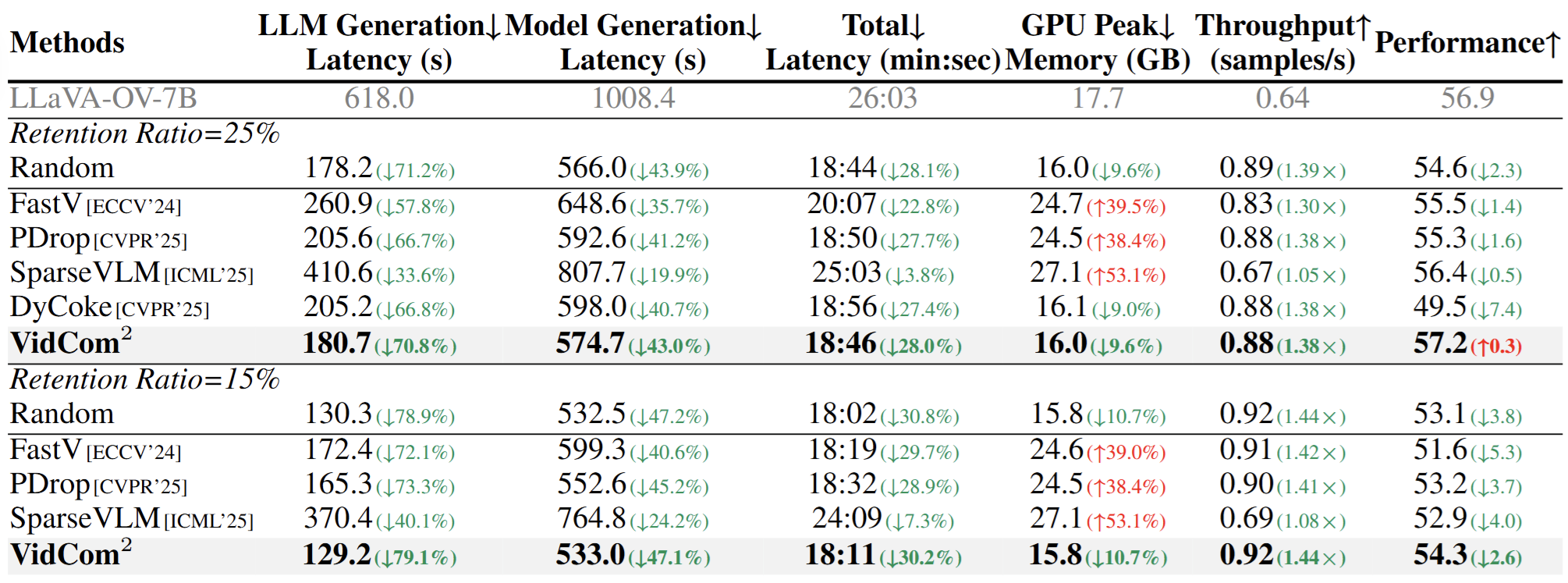
图8. 与其它 token 压缩方法结合使用的效果
在MVBench、MLVU和VideoMME-L基准上,添加VidCom²的帧压缩强度调整后,其它压缩方法的性能表现出显著提升,证明其通用性与鲁棒性。
结语
本工作提出VidCom²框架,一种即插即用视频Token压缩方法,用于加速视频大语言模型推理。通过量化帧独特性,自适应调整压缩强度,在LLaVA-OV模型上,仅保留25% Token即可实现99.6%原始性能,并减少70.8% LLM生成延迟。框架提炼模型适应性、帧独特性和操作符兼容性三大原则,在MVBench等基准上优于DyCoke和SparseVLM,提供高效、鲁棒的视频理解新范式。


