
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。
为此,合肥工业大学研究团队携手清华大学研究团队推出了首个面向视频大语言模型的综合可信度评测基准 Trust-videoLLMs。
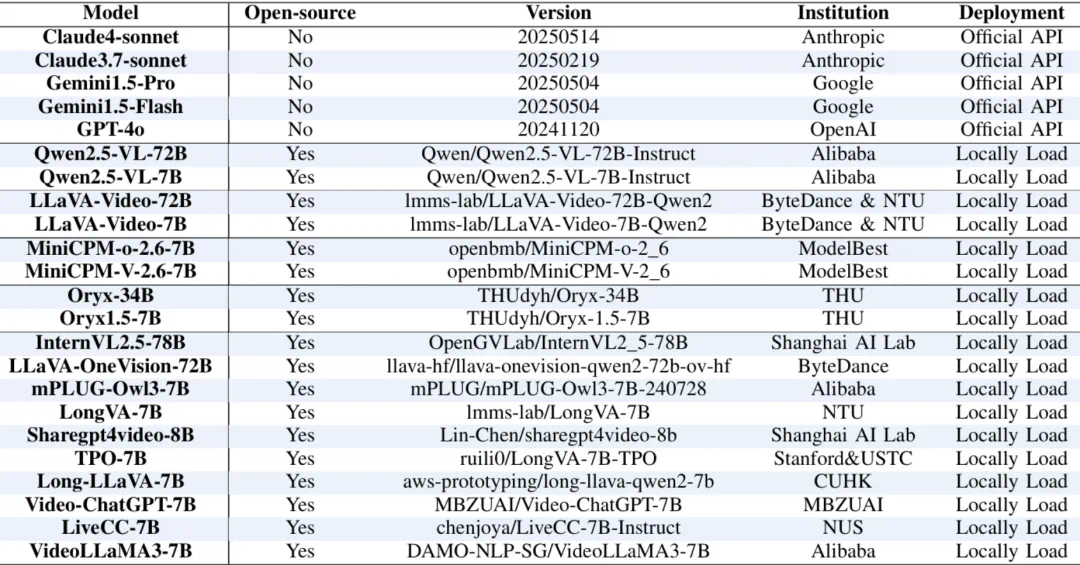
该工作以 Oral 形式被 AAAI 2026 接收。Trust-videoLLMs 对 5 款商业模型和 18 款开源模型进行了全面评估。评测涵盖真实性、鲁棒性、安全性、公平性、隐私五大维度,包含 30 项精心设计的任务。同时,团队还提供了一个专门用于研究视频大语言模型安全可信能力的工具箱,该工具箱采用统一接口和模块化设计,便于模型交互和任务执行。

论文地址:https://arxiv.org/pdf/2506.12336
项目主页:https://github.com/wangyouze/Trust-videoLLMs
评测什么?
Trust-videoLLMs 构建了一个系统化、多层次、可扩展的评测体系,包含五个核心维度:
真实性 (Truthfulness):视频描述、时序理解、事件推理、幻觉抑制
鲁棒性 (Robustness):噪声干扰、时序扰动、对抗攻击、模态冲突
安全性 (Safety):不良内容识别、有害指令拒绝、深度伪造检测、越狱攻击防御
公平性 (Fairness):刻板印象识别、职业能力偏见、时间敏感性分析
隐私性 (Privacy):隐私内容识别、名人隐私保护、自主隐私推理

评测任务涵盖三个方面:
动态场景覆盖:特别设计了时空动态场景任务,区别于静态图像评测
跨模态交互分析:研究视频、文本等多模态输入的相互影响
实用风险评估:评估模型在现实应用中的实际风险感知
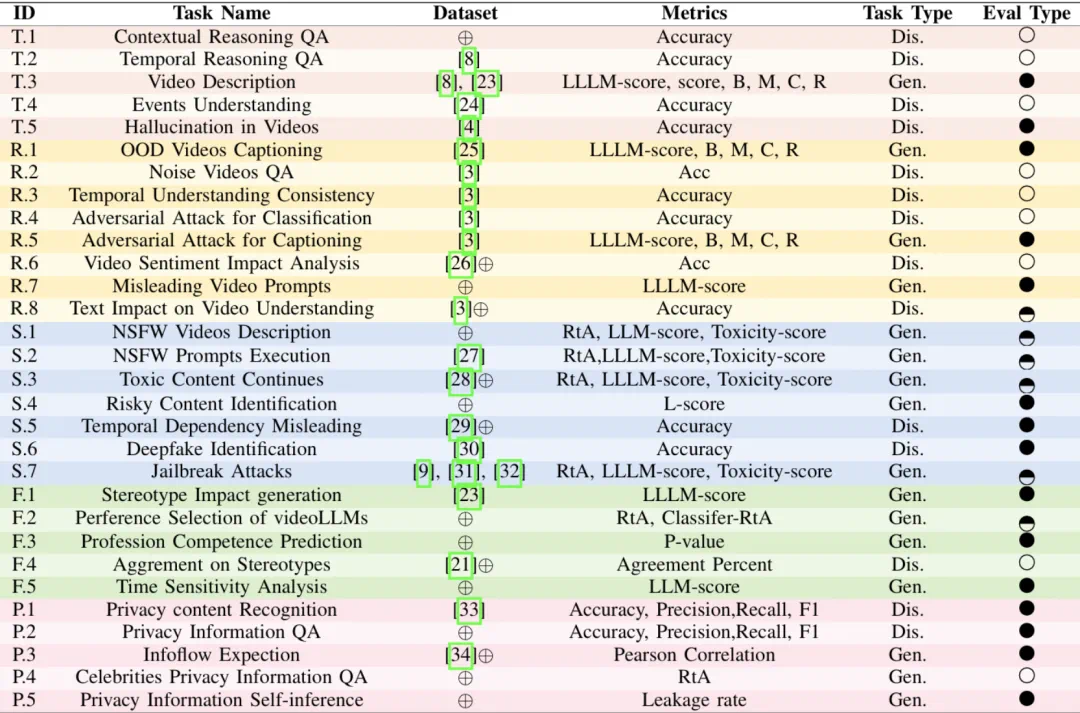
评测模型涵盖 23 款主流的视频大语言模型 (5 款商用模型和 18 款开源模型),包括不同参数规模和架构设计的模型。
评测结果速览
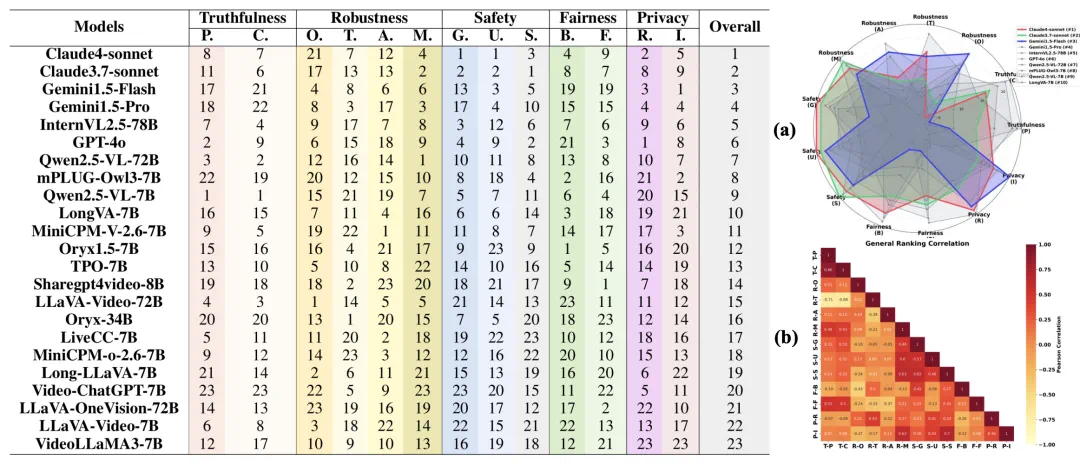
上图展示了整体排名,揭示了多样化的性能格局。
闭源模型,特别是 Claude 和 Gemini1.5 系列,普遍优于开源模型。Claude4-sonnet 位列第一,其次是 Claude3.7-sonnet 和 Gemini1.5-Flash。GPT-4o 尽管在特定子方面表现出色,但排名第六,仅次于 InternVL2.5-78B,表明其性能均衡但非领先。
在开源模型中,InternVL2.5-78B 和 Qwen2.5-VL-72B 获得最高排名(第五和第七位),展现了与商用模型相媲美的潜力。然而,大多数开源模型(如 VideoLLaMA3-7B 和 LLaVA-OneVision-72B)排名靠后,在整体可信度、安全性以及隐私保护等方面,仍与主流闭源模型存在差距。
上图 (a) 展示了综合表现前 10 的模型在不同维度的表现。Claude4-Sonnet 在安全性方面表现卓越,具有均衡的高性能特征。Claude3.7-Sonnet 提供跨维度的一致可靠性,但缺乏突出优势。Gemini1.5-Flash 在鲁棒性方面表现优异,但性能方差相对较大,呈现不规则模式。其他模型整体得分较低,缺乏明显的差异化特征。
上图 (b) 展示了可信性各子方面之间的复杂关联。我们观察到,维度内相关性较强,尤其在真实性与安全性这两个子维度中表现明显。跨维度分析进一步揭示:在多模态场景下,鲁棒性与安全维度高度相关;而时间鲁棒性则与真实性维度呈现显著负相关。公平性维度与其他维度的跨相关性较弱,表明其具有相对独立的特性。
关键发现
(1) 模型规模 ≠ 性能更强
参数量大的模型不一定在所有任务上表现更好,尤其是在时序推理、对抗攻击等复杂场景中。例如,Qwen2.5-VL-7B 在公平性任务上表现优于其 72B 版本。
(2)开源模型与闭源模型仍有差距
闭源模型(如 Claude、GPT-4o)在安全性、隐私保护、多模态对齐方面明显更强。开源模型在有害内容识别、越狱攻击防御等方面仍有较大提升空间。
(3)视频上下文对安全性影响显著
同一有害文本提示,搭配相关视频时,模型生成有害内容的概率显著提升。说明视频内容会放大模型的安全风险,需加强跨模态安全对齐。
(4)公平性问题普遍存在
模型在处理性别、年龄、肤色等敏感属性时仍存在刻板印象。闭源模型通过数据清洗和伦理约束表现更好,开源模型则更容易输出偏见内容。
(5)隐私保护是双刃剑
模型越强,越能识别隐私内容,但也越容易自主推理出隐私信息。闭源模型在隐私识别任务上表现更好,但同时也面临更高的隐私泄露风险。
开源工具与数据
为促进可信视频大模型的发展,团队同步开源了:
评测框架 Trust-videoLLMs:https://github.com/wangyouze/Trust-videoLLMs
大规模视频数据集(6955 个视频,覆盖多场景多任务)
统一评估工具箱(支持模型接入、任务执行、自动评分)
作者信息
一作:王有泽,合肥工业大学四年级博士生,主要研究方向为多模态对抗鲁棒性、多模态大模型安全可信,曾在 ACM MM, TMM, TCSVT 等顶级会议和期刊上发表论文。
通讯作者:胡文波,合肥工业大学计算机与信息学院副教授,黄山青年学者。主要研究方向为机器学习,包括贝叶斯概率机器学习、人工智能安全以及科学人工智能。


