MM-HELIX团队 投稿
量子位 | 公众号 QbitAI
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。
无论是生成代码、分析图表还是回答问题,诸多多模态大模型(MLLM)都倾向于给出一个“一步到位”的答案。它们就像一个从不检查作业的“学霸”,虽然知识渊博,但一旦在复杂的、需要反复试错的问题上走错一步,就很难回头。这种能力的缺失,正是阻碍AI从“知识容器”迈向“问题解决大师”的关键瓶颈。
现在,来自上海交通大学和上海人工智能实验室的研究团队,带来了新的解决方案——MM-HELIX。
MM-HELIX不仅是一个项目,更是一个完整的生态体系,旨在赋予AI一种最接近人类智慧的能力:长链反思性推理(long-chain reflective reasoning)。

多种多模态反思任务
我们无法提升我们无法衡量的东西。为了精准评估AI的反思推理能力,团队首先构建了一个前所未有的“终极考场”——MM-HELIX Benchmark。
它不再是简单的看图说话或数学计算,而是包含了42种横跨算法、图论、谜题和策略游戏的超高难度任务,例如:
- 逻辑的迷宫:在“扫雷”中根据数字线索进行缜密推理与回溯。
- 策略的博弈:在“推箱子”中规划长远,避免一步走错,满盘皆输。
- 算法的具象:寻找图中的“哈密顿路径”,需要在脑海中进行多次路径规划与剪枝。
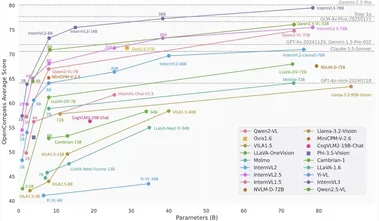
团队搭建了42个任务的Sandbox,包含Generator,Solver,Validator等多个关键部件,并根据题目复杂度区分了五层难度,并最终收集了1260道题目,对当前的多模态大模型进行了细粒度的评估,评估结果如下:

MM-HELIX评估结果
测试结果令人震惊:即便是当前最顶尖的闭源和开源模型,在这份考卷上也纷纷“折戟”,准确率惨淡,仅有GPT5超过了50分;不具有反思能力的模型更是只有10分左右的准确率。与此同时,模型在面对多模态输入时,准确率相比于纯文本输入有大幅的下降。这有力地证明了,教会多模态大模型反思,刻不容缓!
如何教会多模态大模型“三思而后行”?你需要一本好的教科书。
为此,团队采用“步骤启发式响应生成”(Step-Elicited Response Generation, SERG)流程,基于MM-HELIX Sandbox数据引擎,通过给模型提供解题的关键步骤(key step)来生成解题过程,不仅相比直接让模型解题(rollout)推理时间减少了90%,同时还大幅降低了解题过程中过度反思带来的冗余度,高效高质地生成了多模态反思性思维链。
基于SERG流水线,作者团队打造了MM-HELIX-100K,一个包含10万个高质量样本的“反思推理秘籍”。这种充满“自我纠错”和“灵光一闪”的数据,是教会多模态学会反思与复盘的完美养料。
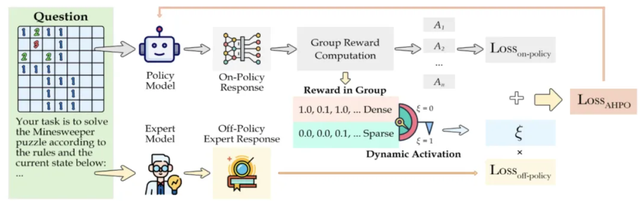
AHPO算法示意图
有了“考场”和“秘籍”,还需要一位懂得因材施教的“导师”。
直接微调方法(SFT)容易导致模型在通用能力上“灾难性遗忘”,而On-policy强化学习则因任务难度过高,奖励稀疏而“学不会”。
为此,团队提出了创新的自适应混合策略优化算法(Adaptive Hybrid Policy Optimization, AHPO)。
AHPO算法的智慧之处在于它的“动态教学”:
- 当模型是“新手”时:在复杂任务上屡屡碰壁,奖励稀疏,AHPO会引入“专家数据”进行强力指导,相当于手把手教学,帮模型快速入门。
- 当模型变“熟练”后:成功率提高,奖励密集,AHPO会逐渐“放手”,减少专家干预,鼓励模型自由探索,发现比标准答案更优、更巧妙的解法。
这种“扶上马、送一程、再放手”的自适应机制,完美解决了学习过程中的两难问题,让模型既能学到专家的智慧,又能发展出自己的独立思考能力。
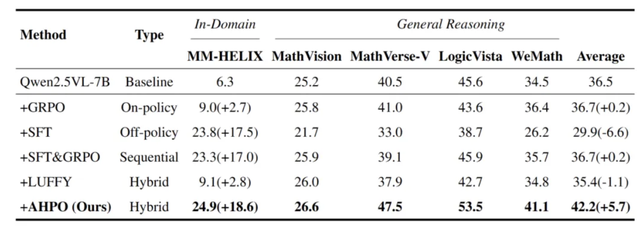
实验结果
搭载了MM-HELIX-100K和AHPO的Qwen2.5-VL-7B模型,实现了惊人的蜕变:
- 在MM-HELIX基准测试上,准确率飙升+18.6%,一举超越了体量远大于自身的SOTA模型。
- 更令人振奋的是,这种反思能力展现出了强大的泛化性!在多个通用的数学和逻辑推理任务上,模型平均性能提升了+5.7%。
这证明,MM-HELIX教会模型的不是如何“背题”,而是真正掌握了“反思”这一可迁移的元能力。
MM-HELIX Benchmark,MM-HELIX 100k,MM-HELIX Sandbox Environment目前均已开源。
项目主页: https://mm-helix.github.io/