
大家好,我是肆〇柒。思维链,可能是大家刚接触“本届模型”(transformer 为架构的 LLM),学 prompt 时的一个必修课,大语言模型可以仿照人的链式思考模式来生成推理链,以辅助推理和解决问题。
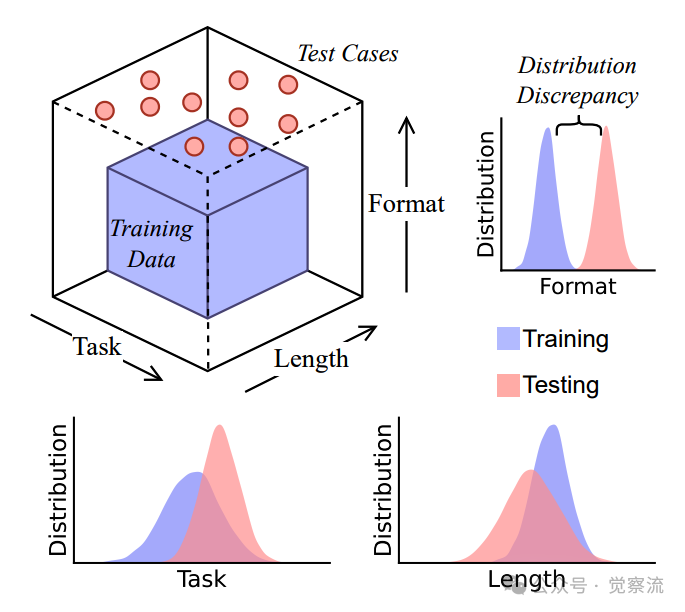
我看到一个研究论文,它从数据分布视角,深入剖析了大型语言模型(LLM)思维链(CoT)推理的本质,还挺有意思的,对我们理解 CoT 和模型推理边界,具有原理级的认知帮助。所以,下面我们就一起看看这篇论文,它是由亚利桑那州立大学数据挖掘和机器学习实验室的最新研究成果。这项发表在顶会上的研究,通过精心设计的受控实验环境DataAlchemy,揭示了CoT推理的"海市蜃楼"特性,挑战了当前对LLM推理能力的普遍认知。
核心发现:
在深入探讨前,让我们先了解本研究的三个关键发现:
- CoT推理本质是"脆弱的海市蜃楼":看似结构化的推理实则源于训练数据中模式的条件生成,而非真正的逻辑推断
- 三大泛化维度的严格限制:任务、长度和格式三个维度的分布差异都会导致CoT性能急剧下降
- 高风险领域的警示:在医疗、金融等关键领域,CoT产生的"流畅的胡言乱语"比直接错误更具欺骗性和危害性
CoT的幻觉本质
先看一个问题:"美国建国日是在闰年还是平年?"再看一个回答:"美国成立于1776年。1776能被4整除,但它不是世纪年,所以是闰年。因此,美国建国日是在平年。"
这是Gemini给出了这样一段看似合理却逻辑矛盾的回答。模型正确复述了闰年规则并阐述了中间推理步骤,却得出了逻辑不一致的结论(既声称1776是闰年又说是平年)。
这个例子完美展示了思维链(Chain-of-Thought, CoT)提示技术的悖论:通过简单的提示如"让我们一步步思考",大型语言模型(LLM)能够将复杂问题分解为中间步骤,产生看似人类推理的输出。这种方法在逻辑推理、数学问题求解和常识推理等任务中展现出显著效果,促使研究者和实践者普遍认为LLM具备了某种形式的"推理能力"。
然而,仔细观察会发现这种表面流畅但内在矛盾的现象揭示了一个关键问题:CoT推理是否反映了真正的推理能力,还是仅仅是模式匹配的幻觉?
研究者基于这一观察提出了核心论点:CoT推理的有效性根本受限于训练数据与测试查询之间的分布差异。当LLM面对与训练数据分布相似的查询时,它能够条件生成近似训练中见过的推理路径;但一旦超出这一分布,其"推理"能力就会迅速崩溃。这种现象被描述为"脆弱的海市蜃楼"——看似结构化的推理实则源于训练数据中模式的条件生成,而非真正的逻辑推断。
数据分布视角:CoT推理的有效性根本受限于训练数据与测试查询之间的分布差异
为系统研究这一现象,研究者开发了DataAlchemy——一个隔离且受控的实验环境,允许从头训练LLM并在各种分布条件下进行系统探测。与直接测试预训练模型不同,DataAlchemy通过合成数据精确控制分布差异,从而隔离关键变量,避免大规模预训练中复杂模式的干扰。这种方法使研究者能够明确区分CoT推理是源于真正的推理能力还是分布内模式匹配,为理解CoT的本质提供了前所未有的清晰视角。
你是否曾遇到过LLM在推理任务中给出看似合理但逻辑矛盾的答案?这种现象是否可能源于分布差异?
数据分布视角:CoT有效性的根本限制
研究者提出了一种根本性的理论框架:将CoT视为一种受训练数据分布约束的条件生成过程,而非真正的推理机制。
在此框架下,设:

这一理论框架将CoT推理的分析聚焦于三个关键维度:
1. 任务泛化复杂度(TGC):任务"陌生度"评分器
衡量任务新颖性的指标,定义为:

以上公式表达有点多,我尝试举个例子来说明。虽然我不太会做菜,但下面这个例子很容易理解所谓泛化复杂度这个概念。
比如,你刚学会炒菜,但是只会做“番茄炒蛋”和“青椒肉丝”(模型训练后的能力)。而刚才我们所讲到的 TGC 就像是一个评分的系统,它可以用来衡量新菜谱(非训练出现的陌生数据)对你的“陌生度”。如下:
- 如果新菜谱是"番茄炒蛋加盐" → 陌生度低(元素都见过,只是微调)
- 如果新菜谱是"番茄炒牛肉" → 陌生度中等(部分元素见过,部分新元素)
- 如果新菜谱是"红烧鲤鱼" → 陌生度高(完全没见过的食材和流程)
2. 长度外推高斯退化模型:推理链长度的"甜蜜点"

这一段公式也有点复杂,我举个生活例子来说明吧。我们日常都会使用手机,不知道你是否有这样的经验,手机的温度会影响手机的续航时长,温度过高,或者冬天在室外温度过低,都会影响电池续航。我们假设手机电池在25°C时续航最长。LLM处理推理链长度也是这样的,在训练时常见的长度处表现最佳,偏离这个"甜蜜点"时,性能会像钟形的上凸曲线一样下降。
那么,这个“高斯退化模型”就解释了为何错误率在训练长度附近最低,并随长度差异增大呈高斯式上升。
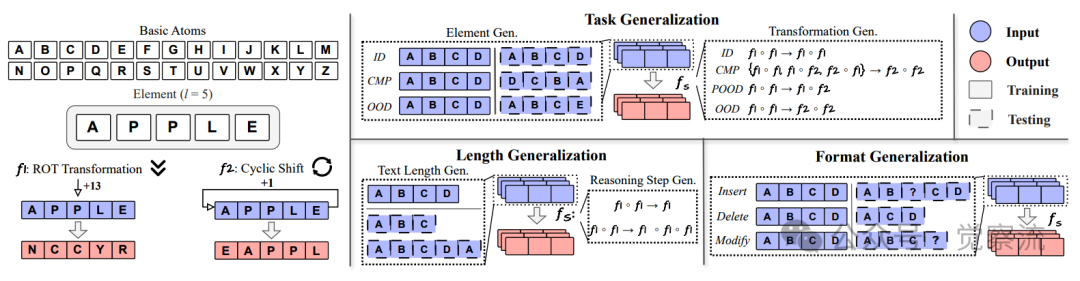
3. 格式对齐分数(PAS):提示"熟悉度"打分器
衡量提示相似性的指标:
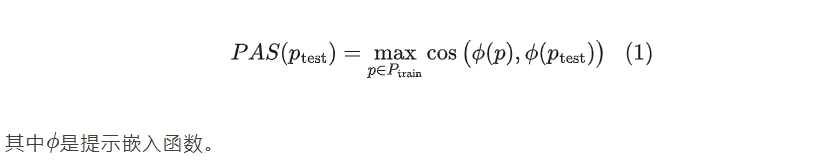
DataAlchemy框架,创建隔离受控环境来训练LLM并探测任务、长度和格式泛化
这一理论框架颠覆了传统观点:CoT并非代表LLM的"推理能力",而是反映了一种结构化归纳偏置——模型从分布内数据中学习到的模式,使其能够条件生成近似训练中见过的推理路径。当面对分布外查询时,LLM往往产生"流畅的胡言乱语":表面连贯但逻辑不一致的推理步骤。
怎么理解这个格式对其分数?PAS就像是一个“提示熟悉度”的打分器,衡量新提示与模型训练时见过的提示有多相似。你可以想象你习惯用特定格式接收指令,比如"请做X,步骤:1,,,2,,,3,,,"。如果突然改成"X怎么做?按顺序说",即使意思相同,你也可能需要时间来反应那个 123 是啥。
所以,这种现象解释了为什么LLM在看似合理的推理后仍可能得出错误结论——它们并非在进行逻辑推断,而是在复现训练数据中的模式。
三个泛化维度的实证发现
任务泛化:模式匹配而非真正推理
研究者通过DataAlchemy设计了系统性实验,将任务泛化分解为转换泛化和元素泛化两个方面。在转换泛化实验中,定义了四个分布偏移级别:

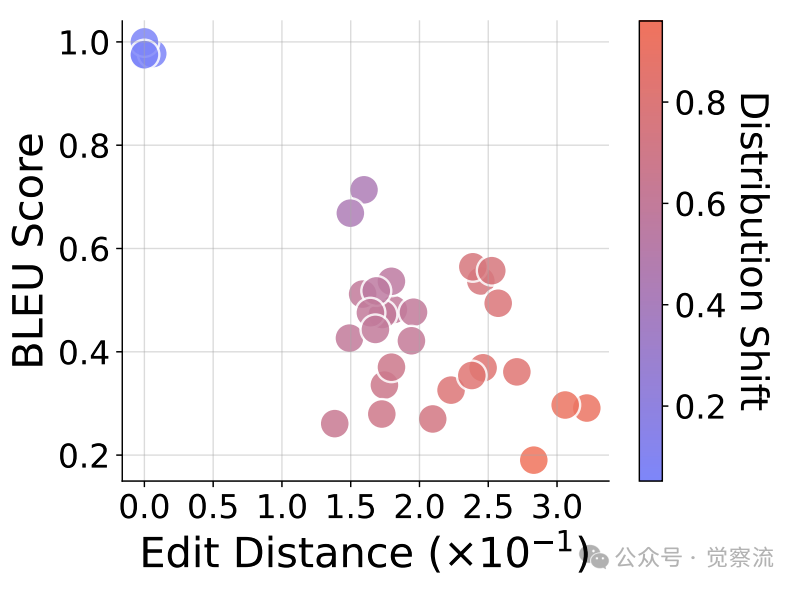
转换泛化性能,CoT推理的有效性随分布差异增大而下降

论文提供了一个具体案例:
Prompt: 'A A A B[F1][F2]'Generated: 'B A A A[F1] O N N N'Expected: 'O N N N'
此例中,模型在f₂◦f₁转换上产生正确答案但错误推理步骤,因为A A A B经f₁◦f₂和f₂◦f₁恰好得到相同结果,这是正交转换导致的巧合。
更深入的分析揭示了推理步骤与答案不一致的典型模式。论文表2和附录D.1.2显示,当模型在{f₁◦f₁, f₁◦f₂, f₂◦f₁}上预训练并在f₂◦f₂上测试时,推理步骤完全正确(100%精确匹配),但答案错误(仅0.01%精确匹配)。具体案例:
Prompt: 'A A A D[R1][R1]<think>'Generated: 'N N N Q[R1]<answer> N N Q N'Expected: 'N N N Q[R1]<answer> A A A D'
这表明模型无法真正理解任务逻辑,而是依赖于训练数据中相似模式的匹配。这种"修补"式泛化进一步证实了CoT推理的模式匹配本质。
研究者进一步发现,通过监督微调(SFT)引入少量未见数据(仅占训练集的0.015%),模型就能迅速适应新的分布。这表明LLM并非真正理解任务逻辑,而是依赖于训练数据中相似模式的匹配。这种"修补"式泛化进一步证实了CoT推理的模式匹配本质。
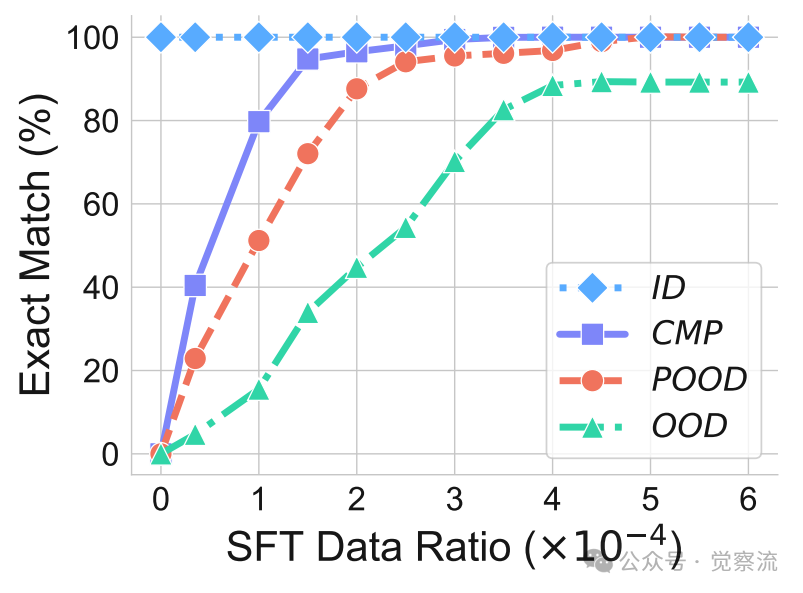
通过SFT在不同分布偏移级别上处理未见转换的性能,引入少量未见数据有助于CoT推理在不同场景中泛化
注意:SFT能"修补"分布差异,但仅限于与训练数据有某种程度相似性的任务。当面对完全新颖的元素组合时,情况会如何?
元素泛化的挑战
除转换泛化外,元素泛化也是任务泛化的重要维度。与转换泛化不同,元素泛化测试的是模型对全新元素组合的适应能力,定义了三个分布偏移级别:
- 分布内(ID):测试元素与训练相同
- 组合(CMP):测试样本包含新组合的已知元素
- 分布外(OOD):测试集包含训练中完全未见的元素
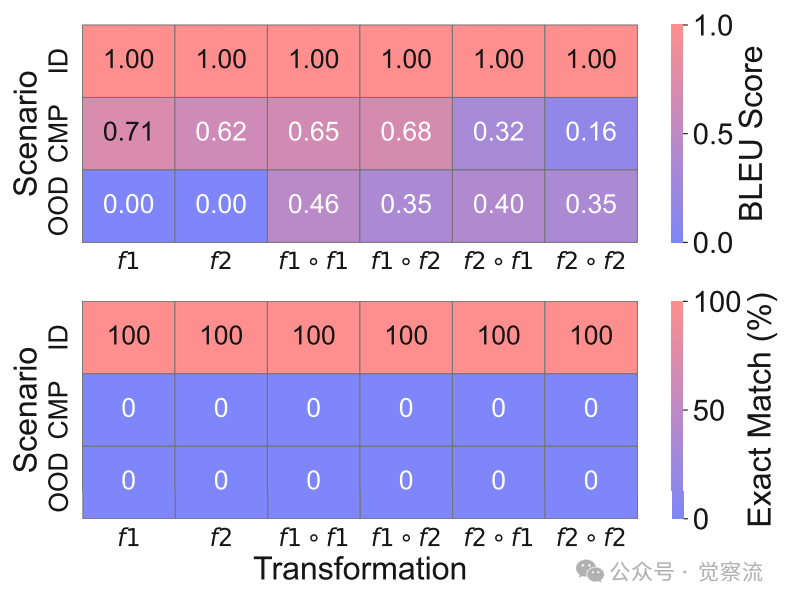
元素泛化性能,CoT推理对全新元素组合的处理能力极为有限
如上图所示,随着元素分布差异增加,CoT性能急剧下降。从ID到CMP和OOD,精确匹配率从100%降至0%,尤其在f₁和f₂转换下,BLEU分数降至0,表明模型完全无法处理全新的元素组合。论文附录D.1.3提供了一个具体案例:
Prompt: 'N N N O[F1][F1]<think>'Generated: 'R V Q S[F1]<answer> E I D F'Expected: 'A A A B[F1]<answer> N N N O'
此例中,模型对训练中未见过的元素(N、O)完全无法正确处理,生成了毫无关联的输出。
研究者进一步探索了如何通过监督微调(SFT)提升模型对新元素的泛化能力。如下图a所示,即使引入少量(约0.1%)与测试数据相似的训练样本,模型性能也能迅速提升。特别值得注意的是,当编辑距离n=3时,CoT推理的准确率与下游任务表现基本一致,表明模型对新元素的泛化能力非常有限。下图b进一步揭示了在训练过程中,答案准确率与推理步骤准确率之间的不匹配现象,这解释了为何CoT在某些情况下会出现推理与答案不一致的问题。
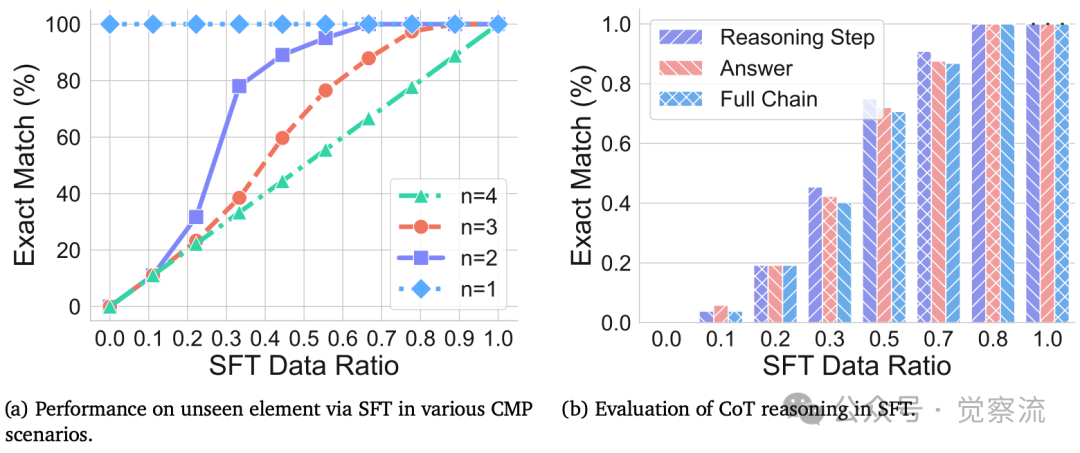
SFT在元素泛化中的表现,揭示了CoT推理与答案准确率的不匹配现象
长度泛化:推理链长度的限制
在长度泛化方面,研究者区分了文本长度泛化和推理步骤泛化:

论文提供了一个具体案例:
Prompt: 'A A B D[f1]<answer>'Generated: 'N O A Z N N O Q[f1]<answer> A A B D'Expected: 'N N O Q'
这表明模型试图通过添加额外标记来匹配训练数据中的长度,导致推理链不准确。
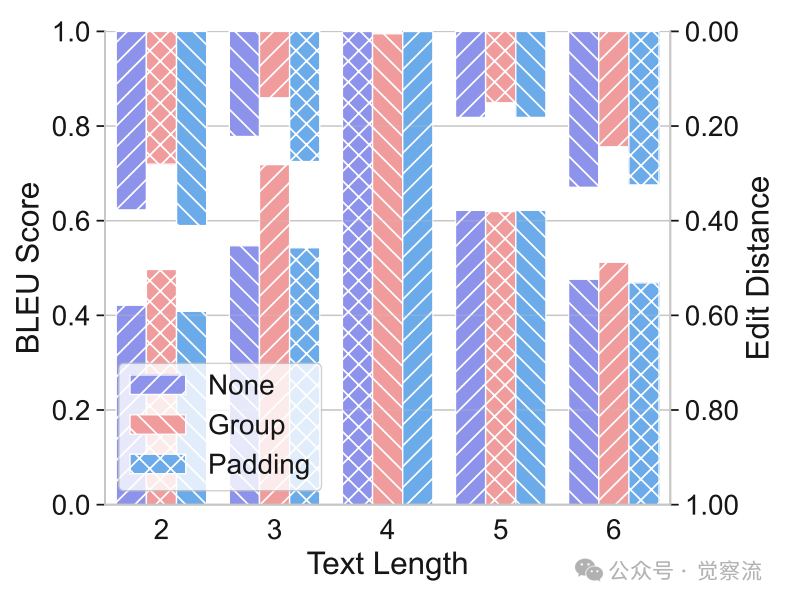
不同填充策略下的文本长度泛化性能,分组策略有助于长度泛化
研究者测试了三种填充策略的影响:无填充、填充至最大长度和分组策略。结果表明,分组策略(将文本分组并截断为最大长度段)比简单填充更有效,说明适当的数据处理可以缓解但无法根本解决长度泛化问题。
推理步骤泛化研究模型能否推广到需要不同推理步骤k的链。在仅训练k=2步骤的情况下测试k=1和k=3,结果同样显示泛化失败。当逐渐增加未见数据比例时,模型在目标数据集上的性能提高,但在原始训练数据上的性能下降,形成明显的权衡。这验证了长度外推高斯退化模型:模型对训练序列长度过度拟合,其位置编码和注意力模式对长度变化高度敏感。
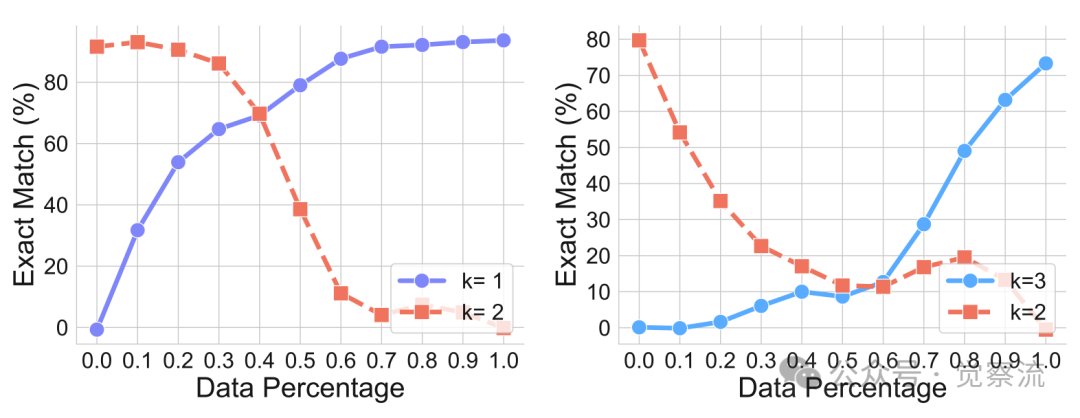
推理步骤泛化在不同训练数据组成下的测试性能,性能随训练数据分布变化而系统变化
格式泛化:表面形式的敏感性
格式泛化实验评估了CoT对测试查询表面变化的鲁棒性。研究者引入四种扰动模式:
- 插入:在每个原始标记前插入噪声标记
- 删除:删除原始标记
- 修改:用噪声标记替换原始标记
- 混合:结合多种扰动
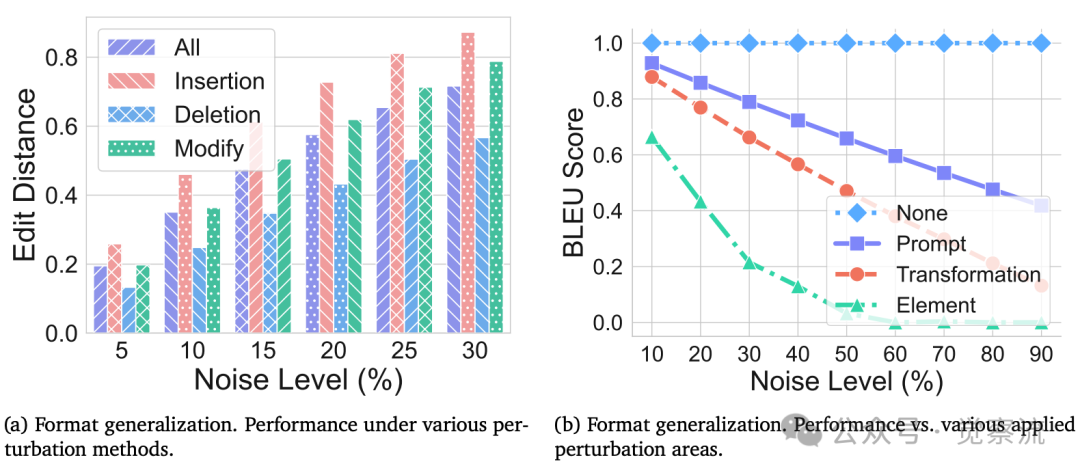
格式泛化性能,测试性能随噪声水平和应用区域的不同而变化
实验发现,即使微小的格式变化也会显著影响CoT性能。插入扰动影响最大,删除扰动影响相对较小。更关键的是,当扰动应用于查询的关键部分(元素和转换)时,性能下降尤为明显;而对其他提示词的修改影响较小。图9b的结果清晰展示了这一点:当扰动应用于元素和转换部分时,性能急剧下降;而对其他提示词的修改影响较小。
这一发现具有重要实践意义:在实际应用中,即使看似无关的提示词变化也可能破坏CoT推理,而关键元素和转换部分的格式稳定性对保持CoT有效性至关重要。这也解释了为什么提示工程(Prompt Engineering)在实际应用中如此重要——它本质上是在寻找与训练分布最匹配的提示格式。
练习一下:本文开头那个例子。我们尝试修改以下提示,观察哪些变化会导致CoT推理失败:"计算美国建国年份1776是否为闰年。让我们一步步思考:首先,判断是否为世纪年..."
对实践的启发:何时信任CoT,何时警惕
CoT使用检查清单
为帮助大家评估CoT在特定任务上的可靠性,可以使用以下分布差异检查清单:
□ 任务元素检查:问题中的关键元素(如数字、概念、实体)是否在训练数据分布内?□ 转换结构检查:推理步骤的逻辑结构是否与训练数据中的模式相似?□ 长度匹配检查:所需推理步骤数量是否接近模型训练时的典型长度?□ TGC评估:任务泛化复杂度是否低于阈值τ?□ 格式稳定性检查:提示格式是否与训练数据高度相似,特别是关键元素和转换部分?
识别CoT幻觉的实用技巧
识别"流畅但不一致"的推理是避免CoT陷阱的关键。首要方法是检查推理步骤与答案的一致性:当推理步骤看似合理但结论矛盾时(如论文中的美国建国年份案例),很可能存在CoT幻觉。不一致推理的典型模式包括:正确复述规则但错误应用、中间步骤与结论逻辑断裂、以及在组合任务中偶然得出正确答案但推理路径错误。
测试轻微扰动下的稳定性是另一种有效方法。对查询进行微小但语义无关的修改(如添加无关短语、改变符号形式),观察CoT输出是否发生显著变化。如果轻微扰动导致结果大幅波动,说明CoT依赖于表面模式而非真正推理。
交叉验证也是重要策略。使用多种提示方式(如不同CoT模板、零样本与少样本CoT)验证关键结论。当不同提示方式产生不一致结果时,应特别警惕CoT输出的可靠性。
高风险领域风险评估
在医疗、金融和法律等高风险领域,CoT幻觉可能导致严重后果,比如:
- 医疗诊断:模型可能正确复述医学规则但错误应用于特定患者症状,导致危险的治疗建议
- 金融决策:在投资分析中,模型可能正确引用财务指标但错误解读其含义,造成重大经济损失
- 法律分析:模型可能准确引用法律条文但错误应用于具体案件事实,导致不当法律建议
风险等级评估框架:
- 🔴 红色区域:任务分布明显偏离训练数据,高风险决策(如医疗诊断、投资建议)
- 🟠 橙色区域:中等分布差异,需专家验证的决策(如合同审查、内容审核)
- 🟢 绿色区域:分布内或接近分布内任务,低风险应用(如格式化文本生成、简单问答)
基于论文发现的合理推断
开发更可靠的推理能力评估方法
当前LLM研究存在"能力展示"偏见——倾向于展示模型在特定任务上的成功,而忽视其能力边界。未来研究应转向"能力边界"研究,系统探索模型在分布外条件下的表现。评估框架应明确包含分布差异维度,而不仅关注分布内性能。
基于DataAlchemy方法,可以构建标准化的分布外泛化能力测试套件,涵盖任务、长度和格式三个维度。这种测试套件应成为评估新模型或提示技术的必要组成部分,帮助研究者区分真正的推理能力与分布内模式匹配。
改进LLM推理能力的可能路径
研究显示,适当的监督微调(SFT)可以快速提升模型在特定分布上的性能,但这只是"修补"而非根本解决方案。SFT本质上扩展了模型的"分布内"范围,而非赋予其真正的推理能力。未来工作应探索如何在不依赖大量特定数据的情况下提升泛化能力。
研究者还探索了温度和模型大小对CoT泛化的影响。
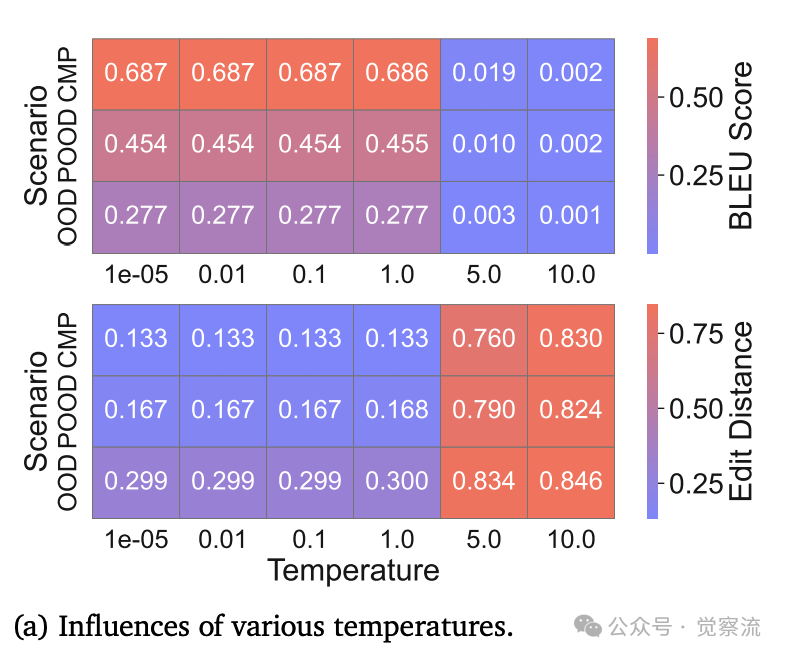
温度和模型大小影响,不同温度和模型大小下,研究结果保持一致
上图a显示,LLM在温度1e⁻⁵到1范围内生成的CoT推理保持一致可靠,即使在分布偏移条件下。这表明温度变化对CoT泛化能力影响有限,挑战了"温度调节能改善推理"的常见假设。
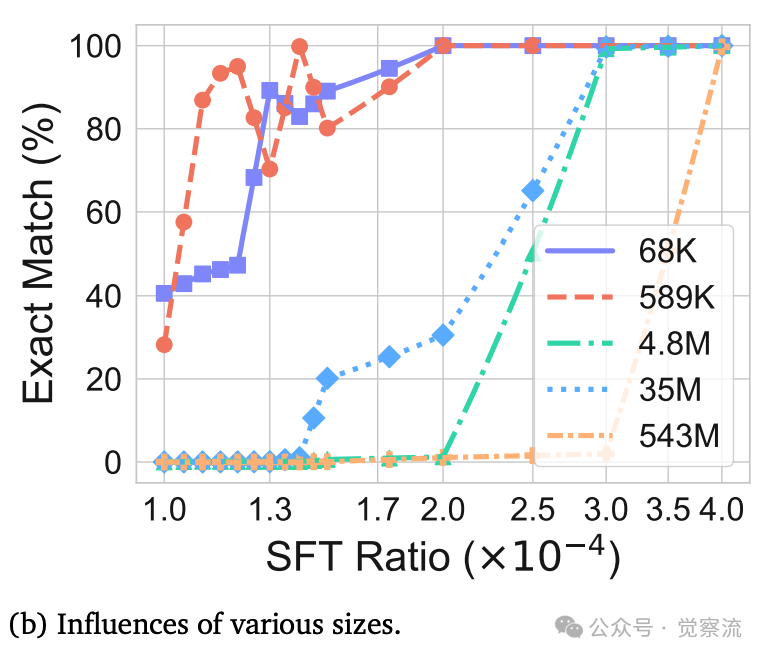
温度和模型大小影响,不同温度和模型大小下,研究结果保持一致
上图b进一步揭示,不同规模模型(从65K到543M参数)在SFT后的表现趋势相似。这表明模型大小并非解决分布外泛化的关键因素,提示我们需要重新思考提升LLM推理能力的有效路径。
模型架构对分布外泛化的影响也值得关注。研究发现,不同温度和模型大小下,分布外泛化表现相似,表明当前架构存在根本限制。未来模型设计可能需要更注重抽象表示和结构化归纳偏置,而非单纯扩大规模。
研究范式的转变:超越表面现象
当前LLM研究需要从"展示能力"转向"理解失败模式"。理解模型何时以及为何失败,比展示其成功更能推动真正推理能力的发展。研究者应更加关注能力边界而非仅展示能力,因为这有助于构建更可靠的系统。
实现真正推理能力的关键在于超越分布依赖。未来模型需要能够处理训练中未见过的结构和关系,而不仅限于插值和外推已知模式。这可能需要新的归纳偏置、更结构化的表示学习,或与符号推理系统的深度融合。
总结:重新认识LLM的"推理"能力
研究清晰表明,CoT推理本质上是一种"脆弱的海市蜃楼":在分布内或接近分布内的数据上有效,但在分布外条件下迅速失效。三个维度(任务、长度和格式)的系统性实验一致证明,CoT的有效性根本受限于训练与测试数据的分布差异,而非代表真正的推理能力。
这一发现警示我们避免过度拟人化LLM的"推理"能力。应从数据分布角度重新评估LLM的推理能力,并采用更严格的实验设计来研究真正推理。将CoT视为模式匹配而非推理机制,有助于更准确地理解LLM的能力和局限。
对我们而言,关键警示是:高风险领域(如医疗、金融或法律分析)中不应将CoT视为"即插即用"的可靠推理模块。LLM产生"流畅的胡言乱语"——看似合理但逻辑错误的推理链——可能比直接错误更具欺骗性和危害性,因为它投射出一种虚假的可靠性光环。在这些领域,充分的领域专家审计是必不可少的。
构建稳健LLM应用需要充分认识CoT的分布依赖性,并实施严格的分布外测试和验证机制。标准验证实践(测试集与训练集高度相似)不足以评估CoT系统的真正鲁棒性。我们必须实施严格的对抗性和分布外测试,系统探测任务、长度和格式三个维度的漏洞。
这一研究可以为我们带来思考:什么是真正的推理?LLM的"推理"与人类推理的根本区别在于前者依赖于分布内模式匹配,而后者能够处理前所未见的情况并进行抽象推断。实现真正推理能力的关键挑战在于超越分布依赖,发展能够处理新颖结构和关系的模型。这不仅是技术挑战,也是对AI系统设计的根本反思——我们应追求的不是表面的"推理"模仿,而是能够真正理解和推断的智能系统。
最后,一句话总结:CoT 的思维链只是训练分布内的条件模式匹配,一旦任务、长度或格式偏离分布便立即失效(任务泛化);它在完全未见任务上出现“流畅胡言”式幻觉(长度泛化);对提示格式最微小的扰动也高度敏感(格式泛化)。


