VLMs 在多模态推理中虽表现强大,但在处理特定场景时易产生 “幻觉”,如:复杂场景适配问题:面对第一视角图像(如智能眼镜拍摄的实时画面)、长尾实体(罕见物体 / 概念)、多跳推理问题(需多步逻辑推导)时,模型易因知识不足或误判生成错误结论;知识时效性问题:模型依赖内部先验知识,对涉及时效性的内容(如实时事件、动态变化的信息)易输出过时答案。
 图片
图片
比赛链接:https://www.aicrowd.com/challenges/meta-crag-mm-challenge-2025
方法
 方法pipline
方法pipline
针对多模态RAG中幻觉问题设计了一个多阶段验证中心框架。该框架通过四个核心阶段的协同运作,实现“减少幻觉”与“保证信息量”的平衡,同时兼顾效率与可靠性。
1、轻量级查询路由
目标是通过预先判断查询是否需要外部知识,避免不必要的检索操作,减少 latency(延迟)并降低对模型先验知识的过度依赖。
方法:使用轻量级语言模型 LLaMA-3.2-1B-Instruct (选择小参数量模型(1B参数)而非大模型,在保证分类准确性的同时显著降低计算成本,确保单轮响应符合10秒限时要求)对输入查询进行分类,输出两个关键决策:
- 是否需要外部信息:判断查询是否可仅通过模型内部知识回答(如常识性问题“天空是什么颜色”),若无需外部信息则直接跳过检索阶段,减少无效计算。
- 是否需要实时信息:判断查询是否涉及时效性内容(如“今天的天气”),若需实时信息则优先触发web搜索API,避免依赖模型中过时的知识。
提示词:
 图片
图片
2、查询感知检索
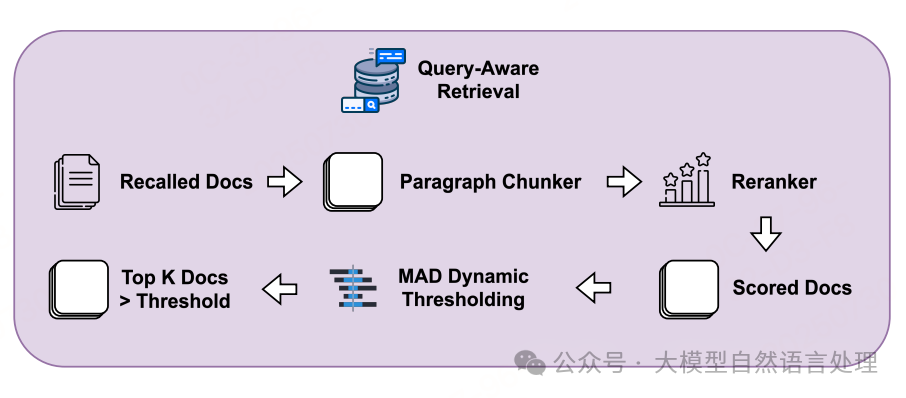 Query-Aware 检索模块
Query-Aware 检索模块
Query-Aware 检索模块
传统固定阈值检索易受数据分布影响(如部分场景下相似度整体偏低),而MAD动态阈值可自适应不同场景。基于查询语义动态优化检索结果,减少噪声信息干扰,构建高质量上下文。
- 步骤1:检索词生成对于需要图像知识的查询,先通过 BLIP-2(视觉语言模型) 为候选图像生成简洁摘要(如“一张包含红色自行车和蓝色围栏的街道照片”)(提示词如下),再将图像摘要与原始查询融合,生成更精准的检索词(而非直接使用原始查询),提升检索与查询的语义匹配度。
 图片
图片
- 步骤2:动态重排序初始检索通过API返回Top-K相似结果后,引入 MAD(中位数绝对偏差) 动态阈值过滤异常值:
计算所有检索结果与查询的相似度得分的中位数,再通过MAD公式(MAD = median(|x - median|))确定合理阈值范围,剔除得分远低于阈值的噪声样本。
最终保留的结果按相似度排序,构建检索上下文(图像元数据+相关文本片段)。
3、双路径生成
目的是通过对比两种生成路径的一致性,初步验证答案可靠性,为后续验证提供依据。 提到单一路径生成易受检索噪声或模型偏见影响,双路径对比可暴露知识冲突(如检索上下文显示“自行车是红色”,但模型先验认为“常见自行车为黑色”),为验证阶段提供明确检查方向。
- RAG路径:基于检索上下文(图像+文本知识),使用 LLaVA-1.5 生成答案,强制模型优先依赖外部知识。
- 非RAG路径:仅使用模型内部先验知识(不输入检索上下文),同样通过LLaVA-1.5生成答案,作为对照基准。
最后对两条路径的输出进行语义一致性评分(使用 Sentence-BERT 计算余弦相似度),若相似度≥0.8则视为“初步一致”,否则标记为“潜在冲突”,需进入后续深度验证。
提示词:
 图片
图片
4、验证与最终确定
CoV通过“整体-局部”两级验证,可有效识别细微错误(如混淆相似实体);而双阈值规则平衡了“准确性”与“可用性”,通过多层验证消除潜在幻觉,基于置信度动态决策最终输出,避免过度保守(滥用“不知道”)或过度自信(错误答案)。
- 步骤1:Chain-of-Verification(CoV)验证采用两阶段验证逻辑:
整体检查:使用 GPT-4o(强推理模型) 作为验证器,检查答案是否符合事实准确性(与检索上下文一致)、逻辑自洽性(无内部矛盾)、完整性(覆盖查询关键点)。
子问题分解:若整体检查不通过,将原始查询分解为多个子问题(如“这张照片中自行车的颜色是什么?”→“照片中是否有自行车?”“自行车的颜色是红色吗?”),逐一验证子问题答案与检索上下文的匹配度,定位错误来源。
- 步骤2:置信度阈值决策验证器输出每个答案的置信度分数(0-1.0),并设定双阈值规则:
高置信度(≥1.0):直接输出RAG路径答案(此时一致性检查与CoV均通过)。
中置信度(0.9-1.0):若双路径一致,输出RAG答案;若不一致,返回“部分信息:[可靠片段]”。
低置信度(<0.9):返回“不知道”,避免幻觉输出。
提示词:
 图片
图片
 图片
图片
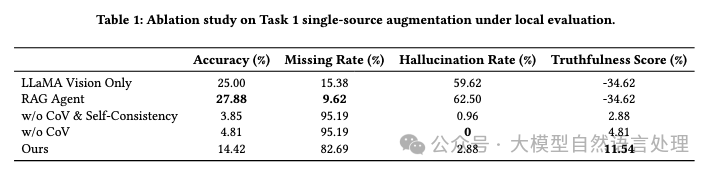
实验性能
 图片
图片
参考文献:Multi-Stage Verification-Centric Framework for Mitigating Hallucination in Multi-Modal RAG,https://arxiv.org/pdf/2507.20136v1repo:https://github.com/Breezelled/KDD-Cup-2025-Meta-CRAG-MM


