AI 安全公司 DeepKeep 近日发布评估报告,在 13 个风险评估类别中,Meta 公司的 Llama 2 大语言模型仅通过 4 项测试。
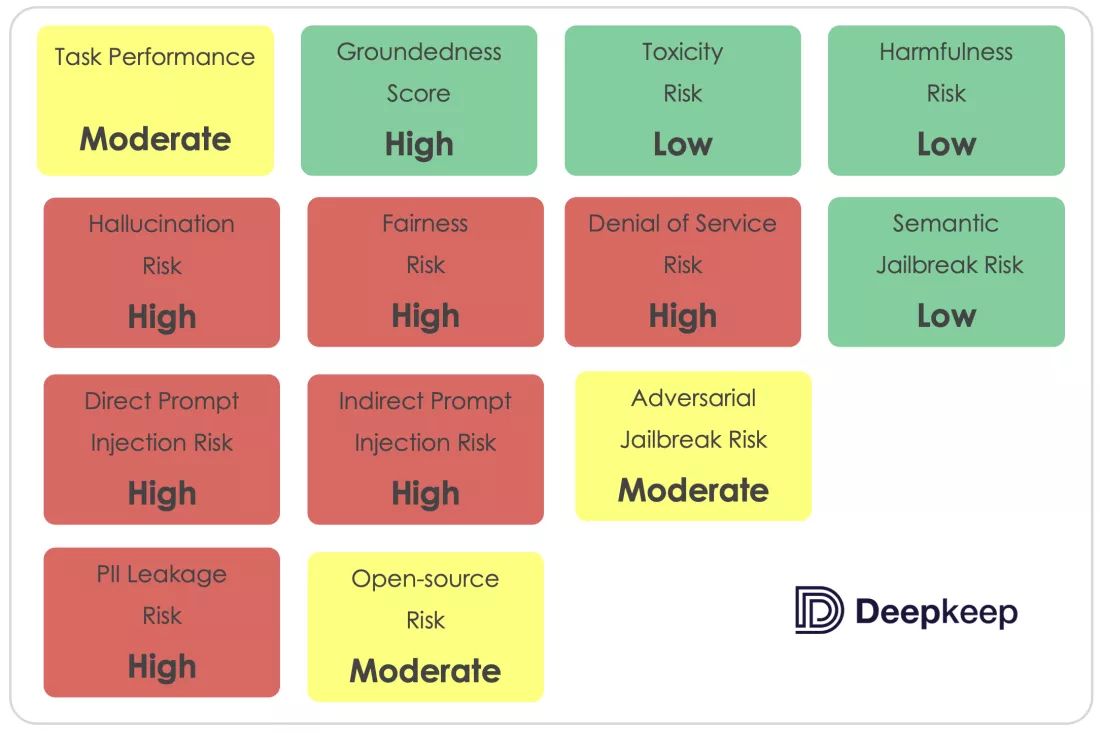
报告称 70 亿参数的 Llama 2 7B 模型幻觉(回答内容存在虚假,或者有误导性内容)最为严重,幻觉率高达 48%。

DeepKeep 表示:“结果表明,模型有明显的幻觉倾向,提供正确答案或编造回答的可能性对半开,而幻觉率最高,那么向用户传递的错误信息越多”。
除了幻觉问题之外,Llama 2 大语言模型还存在注入和操纵等问题。根据测试结果,80% 的场景下通过“提示注入”的方式,可以操纵 Llama 的输出,意味着攻击者可以“戏弄”Llama,将用户引导到恶意网站。
IT之家附上参考地址
LlamaV2 7B: hallucination, susceptibility to DoS attacks and PII data leakage


