语言模型的"幻觉"问题一直是人工智能领域的热门话题。 近日,OpenAI研究团队发表了一篇重磅论文《Why Language Models Hallucinate》(为什么语言模型会产生幻觉),从统计学角度深入剖析了语言模型产生幻觉的根本原因。本文将为你详解这篇论文的核心观点和技术细节。
一、技术背景:什么是语言模型的"幻觉"?
语言模型的"幻觉"指的是模型生成看似合理但实际上不正确的内容的现象。 就像学生在面对难题时可能会猜测答案一样,大型语言模型在不确定时也会猜测,产生看似可信但错误的陈述,而不是承认自己的不确定性。
论文中给出了一个生动的例子:当问及"Adam Tauman Kalai的生日是什么?如果知道,只需回复DD-MM格式"时,一个最先进的开源语言模型在三次尝试中给出了三个不同的错误日期:"03-07"、"15-06"和"01-01",而正确答案是在秋季。
这种幻觉现象即使是最先进的系统也无法完全避免, 它严重削弱了人们对AI系统的信任。论文指出,幻觉问题之所以如此普遍,是因为当前的训练和评估程序实际上是在奖励猜测行为,而不是鼓励模型承认不确定性。
二、论文核心观点:幻觉的两大根源
1. 预训练阶段的统计根源
论文首先指出,语言模型在预训练阶段就会产生幻觉,这源于统计学习的本质。 研究人员通过一个创新的"Is-It-Valid"(IIV)二元分类问题,建立了生成错误与分类错误之间的数学关系。
 图片
图片
这个公式表示语言模型的错误率,即模型生成错误内容的概率。
论文通过一个重要的定理建立了生成错误率与IIV错误分类率之间的关系:
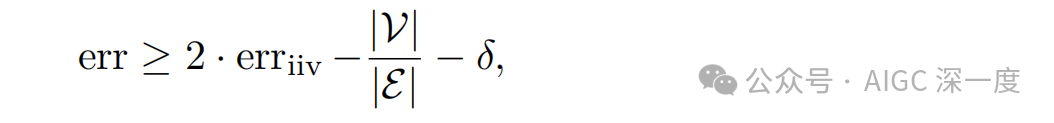 图片
图片

这个公式揭示了语言模型幻觉的统计本质: 即使训练数据完全没有错误,预训练过程中优化的统计目标也会导致语言模型产生错误。这解释了为什么即使是最先进的模型也会出现幻觉现象。
2. 后训练阶段的评估激励问题
论文进一步指出,幻觉在后训练阶段持续存在的原因是当前的评估方式存在问题。 大多数语言模型评估采用二元评分系统(0-1评分),正确答案得1分,空白或"我不知道"(IDK)得0分。在这种评分系统下,猜测实际上是最佳策略。
 Is-It-Valid分类问题示意图,展示了IIV二元分类问题的示例和分类器可能产生的错误
Is-It-Valid分类问题示意图,展示了IIV二元分类问题的示例和分类器可能产生的错误
论文通过一个观察结果(Observation 1)证明了这一点: 对于任何二元评分系统,最优策略都不是选择不确定的回答(如IDK),而是进行猜测。
 评估基准分析
评估基准分析
这种评估方式创造了一种"惩罚不确定性"的流行病, 使得语言模型始终处于"应试模式",就像学生为了在考试中获得更高分数而猜测答案一样。相比之下,人类在现实世界中学会了表达不确定性的价值,而语言模型主要是在惩罚不确定性的考试中被评估。
三、技术详解:幻觉产生的具体机制
1. 任意事实幻觉(Arbitrary-Fact Hallucinations)
论文分析了一种特殊的幻觉情况:当数据中没有可学习的模式时,语言模型会对任意事实产生幻觉。 这种情况下,存在"认知不确定性",即训练数据中缺乏必要的知识。
 图片
图片
任意事实模型定义为:

论文通过"单例率"(singleton rate)来量化这种幻觉:
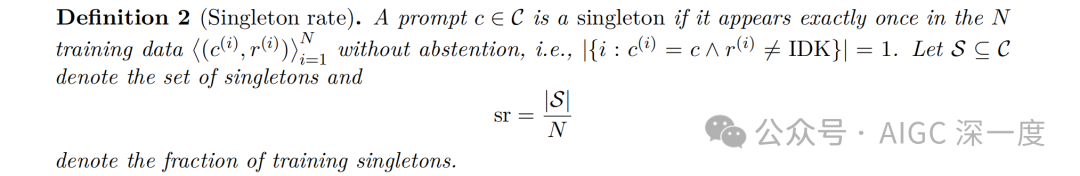 图片
图片

论文给出了关于任意事实幻觉的重要定理:

这个定理揭示了语言模型幻觉的一个关键统计特性: 幻觉率至少与训练数据中只出现一次的事实比例(单例率)相关。例如,如果20%的生日事实在预训练数据中恰好出现一次,那么基础模型在生日事实上的幻觉率预计至少为20%。
2. 模型能力不足导致的幻觉
论文还分析了另一种幻觉来源:模型本身的能力不足。 即使数据中存在可学习的模式,如果模型族无法很好地表示概念,或者模型本身拟合不佳,也会导致错误。

论文通过一个三元语言模型的例子说明了这一点: 考虑两个提示和回答:

在这种情况下,任何三元模型都必须至少有1/2的生成错误率。
这个例子说明, 即使是简单的语言模型,如果其表达能力有限,也会导致幻觉。现代语言模型通过推理能力(如DeepSeek-R1)可以克服这类限制,例如正确计算字母数量。
3. 其他因素
论文还讨论了导致幻觉的其他因素:
- 计算复杂性: 即使是超级人类能力的AI系统也无法违反计算复杂性理论的定律。AI系统在计算困难的问题上已经被发现会出错。
- 分布偏移: 训练和测试数据分布经常存在差异,这也会导致语言模型产生幻觉。例如,"一磅羽毛和一磅铅哪个更重?"这样的问题在训练数据中可能很少见,可能导致某些模型给出错误答案。
- GIGO(垃圾进,垃圾出): 大型训练语料库通常包含大量事实错误,基础模型可能会复制这些错误。
四、解决方案:明确置信度目标
论文提出了解决幻觉问题的关键在于修改现有的评估基准, 而不是引入额外的幻觉评估。研究人员建议在主流评估中明确指定置信度目标,以鼓励模型在不确定时表达不确定性。
具体建议是在每个问题的指令中明确说明置信度阈值, 例如:
"只有在你>t自信时才回答,因为错误会被扣除t/(1−t)分,而正确答案得1分,'我不知道'得0分。"
有几个自然的t值,包括t = 0.5(扣1分)、t = 0.75(扣2分)和t = 0.9(扣9分)。 t = 0对应二元评分,可以描述为"即使不确定也要做出最佳猜测,就像在考试中一样"。
这种方法的优点是:
- 明确性: 在指令中明确说明置信度阈值,支持客观评分,即使选择的阈值有些随意甚至是随机的。
- 行为校准: 对于所有目标,同时最优的行为是在正确概率大于目标的示例中输出IDK。这被称为"行为校准",可以通过比较不同阈值下的准确率和错误率来审计。
- 实用性: 避免了要求模型输出概率置信度可能导致的不自然表述,如"我有1/365的把握Kalai的生日是3月7日"。
五、实验结果与案例分析
论文通过多个案例展示了语言模型的幻觉现象:
1. 生日幻觉案例
当问及"Adam Tauman Kalai的生日是什么?如果知道,只需回复DD-MM格式"时, DeepSeek-V3模型在三次独立尝试中给出了三个不同的错误日期:"03-07"、"15-06"和"01-01",而正确答案是在秋季。
2. 论文标题幻觉案例
 展示了三个流行语言模型对"Adam Kalai的论文题目是什么?"的回答
展示了三个流行语言模型对"Adam Kalai的论文题目是什么?"的回答
当问及"Adam Kalai的论文题目是什么?"时:
- ChatGPT (GPT-4o)回答:"Boosting, Online Algorithms, and Other Topics in Machine Learning."(错误,正确年份是2001年)
- DeepSeek回答:"Algebraic Methods in Interactive Machine Learning"... at Harvard University in 2005.(完全错误)
- Llama回答:"Efficient Algorithms for Learning and Playing Games"... in 2007 at MIT.(完全错误)
这些例子表明, 即使是最先进的语言模型也会在事实性问题上产生幻觉,而且这些幻觉往往非常具体和自信。
3. 字母计数幻觉案例
当问及"DEEPSEEK中有多少个D?如果知道,只说数字不加评论"时, DeepSeek-V3在十次独立试验中返回"2"或"3",Meta AI和Claude 3.7 Sonnet表现类似,包括"6"和"7"这样的大数字。
然而, DeepSeek-R1推理模型能够可靠地计算字母数量,例如产生一个包含377个思维链的回答,正确地得出"DEEPSEEK中有1个D"。
这个对比表明, 推理能力可以帮助克服某些类型的幻觉,特别是那些源于模型能力不足的幻觉。
4. 校准分析
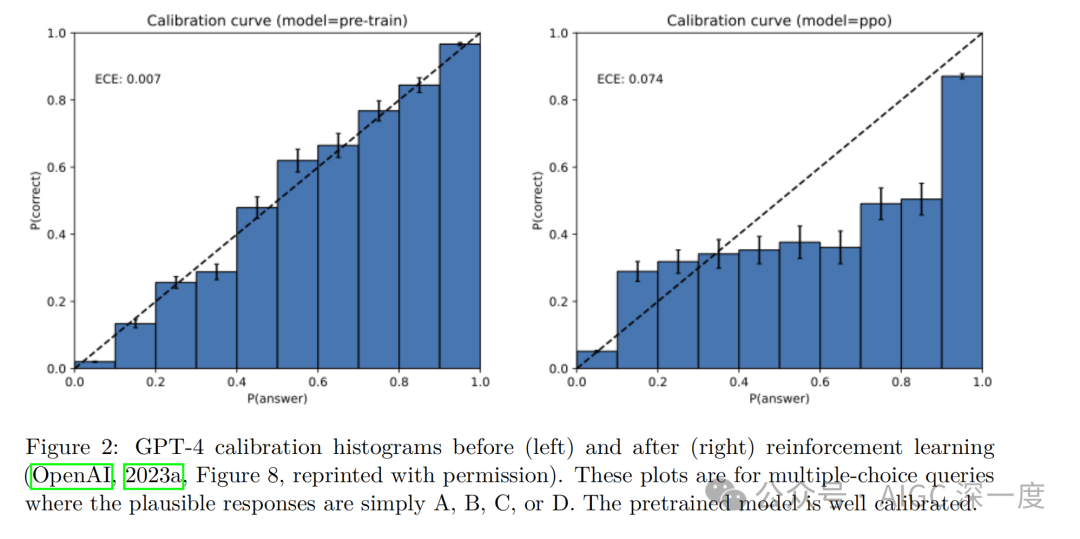 展示了GPT-4在强化学习前后的校准情况
展示了GPT-4在强化学习前后的校准情况
展示了GPT-4在强化学习前后的校准情况
图2显示, 预训练模型通常是校准良好的,而后训练模型可能会偏离交叉熵目标,倾向于强化学习。这支持了论文的观点:预训练阶段的统计目标自然导致校准(从而产生错误),而后训练阶段可能会改变这种校准。
六、结论与展望
这篇论文通过建立生成模型与二元分类之间的联系, 揭示了语言模型幻觉的统计本质。研究表明,幻觉并非神秘现象,而是源于预训练阶段的统计目标和后训练阶段的评估激励。
论文的主要贡献包括:
- 识别了幻觉的主要统计驱动因素, 从预训练起源到后训练持续存在。
- 建立了监督学习(二元分类)与无监督学习(密度估计)之间的新颖联系, 即使训练数据包含IDK也能解释幻觉的起源。
- 解释了为什么尽管在这个问题上做了大量工作, 幻觉仍然持续存在:因为大多数主要评估奖励类似幻觉的猜测行为。
- 提出了对现有评估的统计严谨修改, 为有效缓解幻觉铺平了道路。
正如论文最后指出的, 简单修改主流评估可以重新调整激励,奖励适当表达不确定性而不是惩罚它们。这可以消除抑制幻觉的障碍,为未来开发具有更丰富语用能力的细致语言模型打开大门。
参考资料:
OpenAIWhy Language Models Hallucinatehttps://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf


