
本文的第一作者雍希贤是来中国人民大学的博士生,研究方向聚焦于 Humanoid AI,LLM Coginition & Reasoning。通讯作者为中国人民大学的周骁副教授以及腾讯天衍实验室的吴贤。
当前,大模型的「推理能力」几乎成为行业最热词。o1、R1、QwQ 类强化学习(RL)推理模型,让模型会「想」、会解析复杂问题,甚至能像人一样写长长的推理过程(Chain-of-Thought,CoT),在数学、逻辑与常识等领域任务中展现出强大的多步推理能力。
看上去很强,但问题也随之出现:
这些模型真的需要思考那么久吗?
长推理链条,是帮助模型正确,还是让它越绕越远?
如果你用过这些模型,就会感受到:
很多题模型似乎「一眼就能猜中八成」,但它还是坚持把推理写到几百、几千 token,有时甚至越写越乱、越想越错。
来自中国人民大学、腾讯 Jarvis Lab、西湖大学的研究团队,看到了这背后的核心:
当前大模型的「推理机制」其实非常低效,甚至常常在自我制造噪声。
于是研究团队从另一个视角切入 —— 信息论。
通过「熵(entropy)」与「互信息(mutual information)」等底层信息指标,重新衡量模型思考的价值。
最终,他们提出了一个极其实用的机制:Adaptive Think——让模型在「自信够了」时自动停止推理。
不用训练,用现有模型就能直接部署。
这项工作已被 NeurIPS 2025 选为 Spotlight。

论文标题: Think or Not? Exploring Thinking Efficiency in Large Reasoning Models via an Information-Theoretic Lens
论文链接:https://arxiv.org/abs/2505.18237
代码地址:https://github.com/chicosirius/think-or-not
首先,研究团队借鉴了香农提出的通信三层模型,从技术、语义和实践三个维度观察大模型「过度思考」的本质。
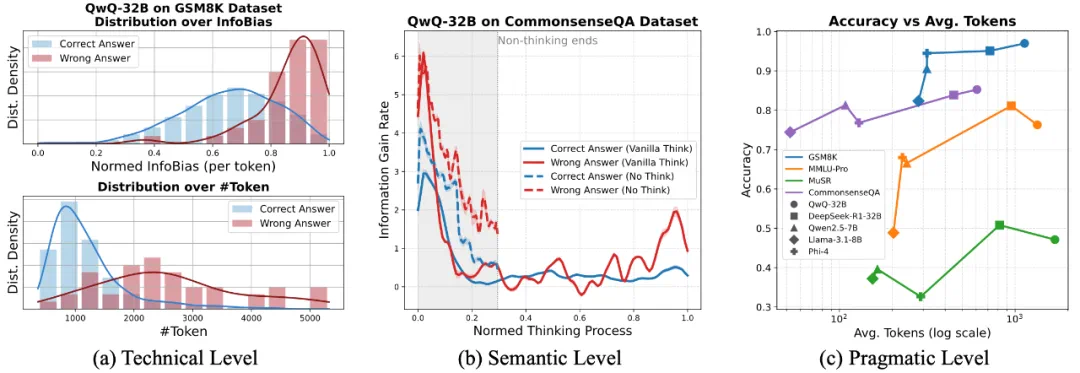
图 1:基于 Shannon & Weaver 通信模型,研究发现推理过长不仅信息增益逐渐减弱,还可能带来偏差并降低最终准确率。
在技术层面(Technical Level),长推理链就像在一个噪声信道里不断添加冗余比特。适度的冗余可以增强鲁棒性,但一旦超过模型的「推理容量」,额外的推理反而可能会带来错误的积累和偏差。
在语义层面(Semantic Level),每一步推理应该减少答案的不确定性。但结果显示,随着推理链延长,单步推理带来的信息增益迅速递减,冗余步骤更多地在制造噪声,而不是帮助模型更接近正确答案。
在实践层面(Pragmatic Level),更长的推理链并不一定带来更好的结果。跨多个任务和模型,推理长度的增加常常导致边际收益下降,甚至出现「思考越久、答得越差」的情况。同时,冗长的推理链带来更多 token 消耗、更高延迟和更大算力开销,使得长推理在实际应用中既昂贵又不可靠。
模型推理为什么会「越想越偏」?
为了进一步量化模型「思考效率」,研究团队从两个层面构建了一个系统评价框架。
1. 全局视角:InfoBias(信息偏差)
将模型的推理链与理想推理路径比对,使用互信息估计偏差:
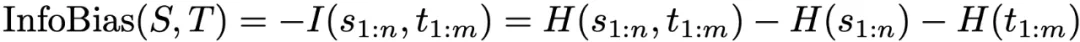
偏差越大,说明模型「越想越偏」。
在 GSM8K 数据集上的实验清晰地展示了这一规律:错误答案往往伴随更长的推理链和更高的 InfoBias。越是错误的答案,模型往往输出更多的 token。
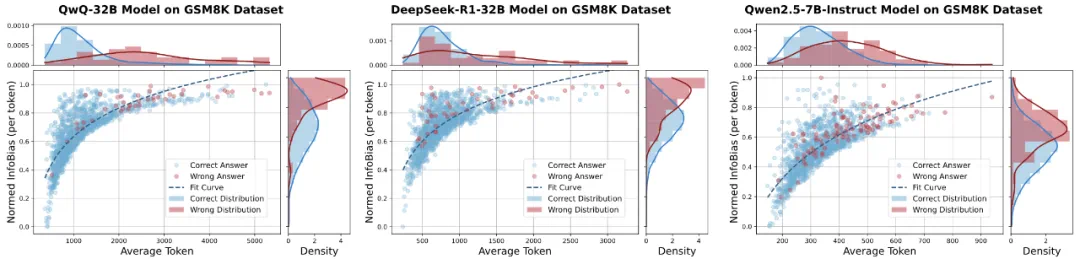
图 2:在 GSM8K 数据集上,不同模型的平均推理长度与归一化后的每个 token 信息偏差关系。
2. 局部视角:InfoGain(信息增益)
定义每个推理步骤降低答案空间熵的量:
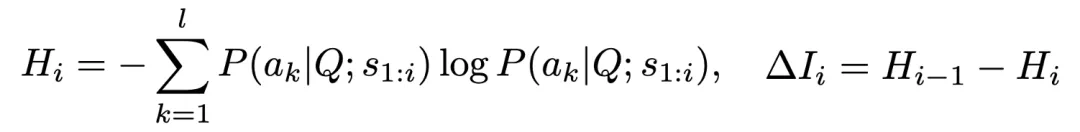
如果某一步没降低不确定性,说明它提供的不是「有效推理」,而是「填充字数」。
实验分析表明,模型在推理过程中表现出逐步降低不确定性和提高对正确答案的信心的趋势,即有效推理可以逐步过滤不确定性并增强预测。
即使在推理开始前,模型在知识密集型任务上也显示出初始直觉偏向正确答案,而不同任务的推理动态存在差异。
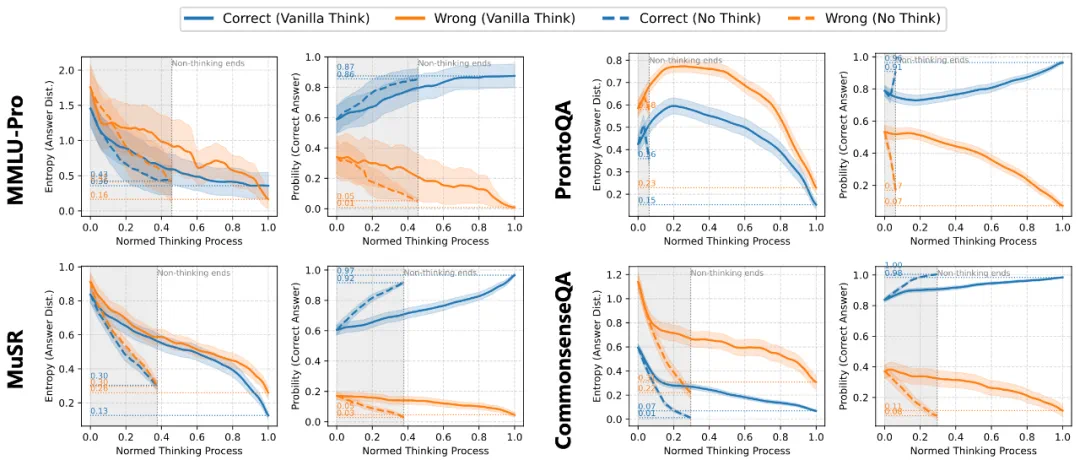
图 3:QwQ-32B 在不同推理基准下的不确定性动态
Adaptive Think 让模型「有必要才深思,无必要就直答」
在发现过度思考可能降低推理效率后,研究团队提出了 Adaptive Think 策略。其核心理念是通过熵来衡量模型在推理过程中的不确定性,并在模型达到足够置信度时主动终止推理。
让模型进行「自我监控式推理」
在这一框架下,每完成一步推理,模型都会计算答案分布的平均熵。当熵低于预设阈值 α 时,表明模型已经具备较高的自信,此时即可停止推理并输出答案。该机制使模型能够根据任务难度灵活调整思考深度:
对于简单的常识类问题,仅需少量推理步骤即可得到答案,从而节省计算资源;
对于复杂的数学或逻辑问题,则会继续深入推理,直至置信度达到足够高的水平才终止。
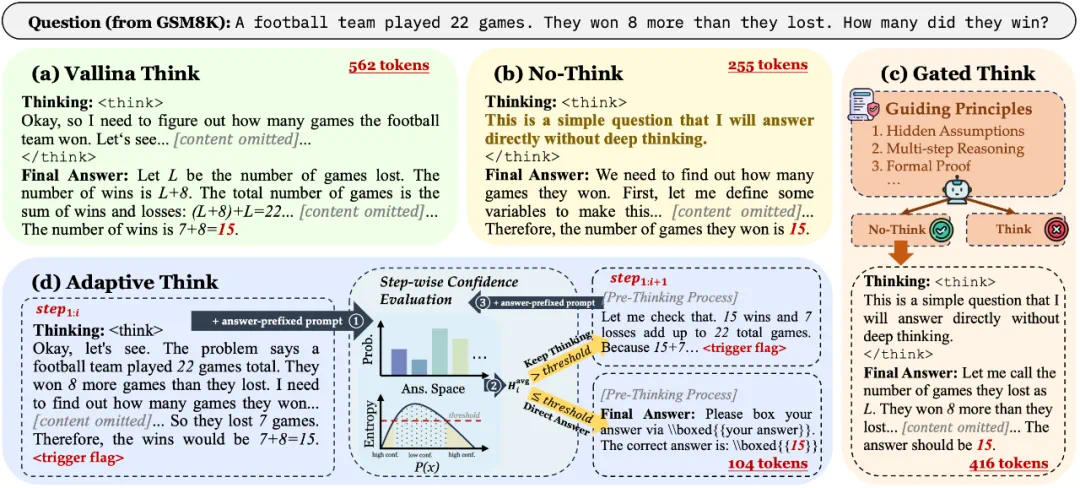
图 4:四种思考方式的示意图
该策略体现了模型对自身信心的动态感知能力,使其能够在不同任务类型间自适应调整推理深度,从而兼顾速度与可靠性。
实验结果 更准、更省、更快
最后,研究团队在 8 个大模型(包括 5 个非推理和 3 个推理模型)、6 个不同推理类型的 benchmark 上进行了完整评估。
在数学任务 GSM8K 与 AIME2025 上,Adaptive Think 在保持准确率的同时,将平均 Token 消耗减少了一半以上(40.01%-68.25)。例如,在 QwQ-32B 模型上,相比传统的 Vanilla Think 模式,Adaptive Think 在 AIME2025 上将 Token 使用量减少了 68.25%,而准确率还提高了 0.93%。这说明模型本身早早就「知道正确答案」,冗余的只是大量验证性推理。
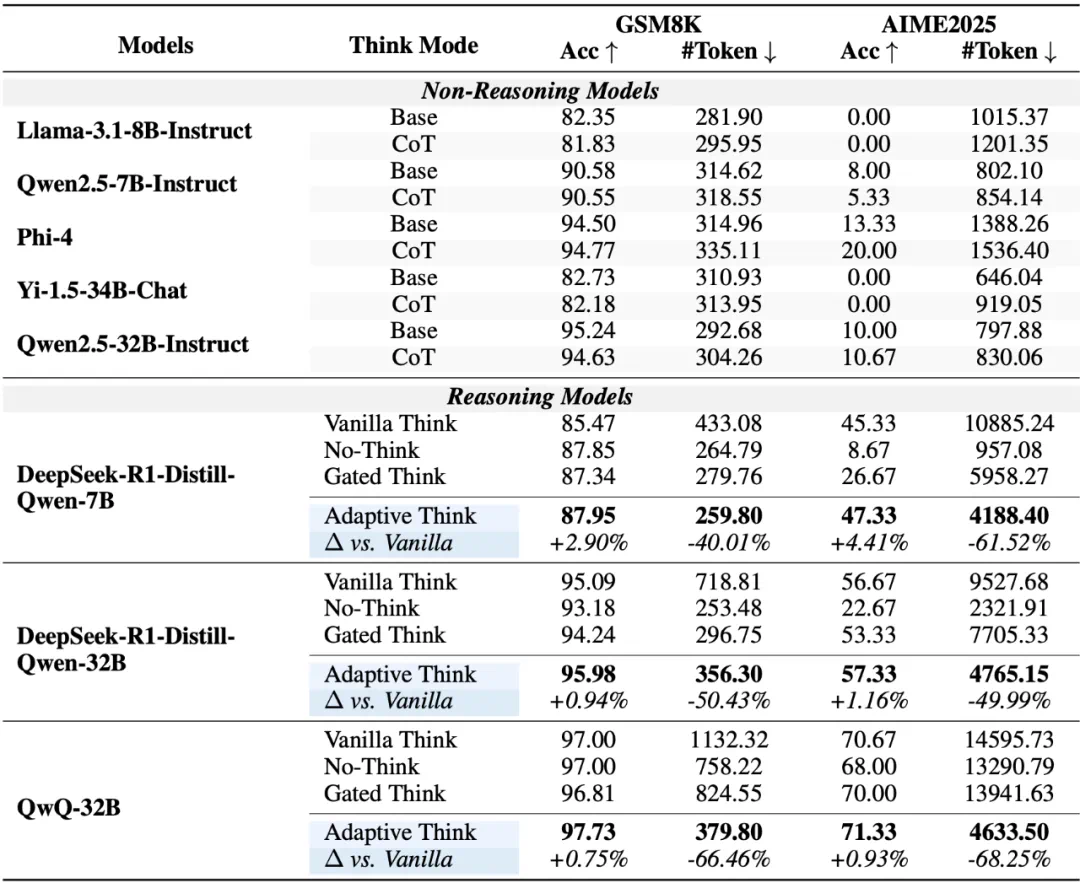
表 1:在两个数学推理基准上的性能与效率对比
在知识、逻辑、常识等任务上,Adaptive Think 同样表现优异。在 MMLU-Pro、CommonsenseQA、ProntoQA、MuSR 等多个数据集上观察到:QwQ-32B 的平均准确率提升 1.23%,平均 token 减少 42.52%。
在 CommonsenseQA 这种靠直觉的任务最显著,DeepSeek-R1-32B 模型采用 Adaptive Think 后,准确率几乎不变,但 Token 消耗减少了超过 80%。这表明对于依赖常识直觉的问题,Adaptive Think 能够快速终止冗余推理,极大地提升效率。
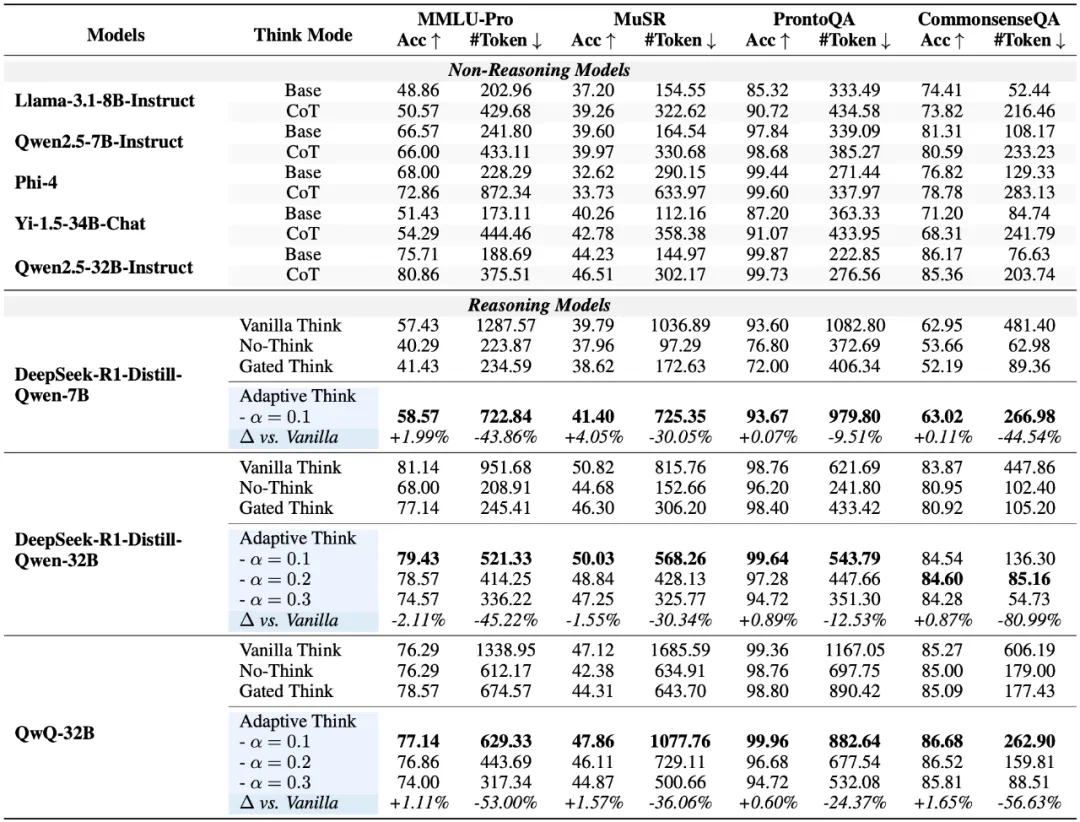
表 2:在知识、逻辑、常识推理基准上的性能与效率对比
这些实验验证了一个关键结论:大模型的长推理链并非必要,很多时候它们只需要「少想几步」。
什么时候应该「多想」,什么时候应该「少想」?
研究团队进一步分析不同任务的「推理需求」,例如:
数学题(AIME2025)→ 需要更深的推理链
常识题(CQA)→ 模型几乎一开始就知道正确答案
多步软推理(MuSR)→ 有效推理集中在前半段
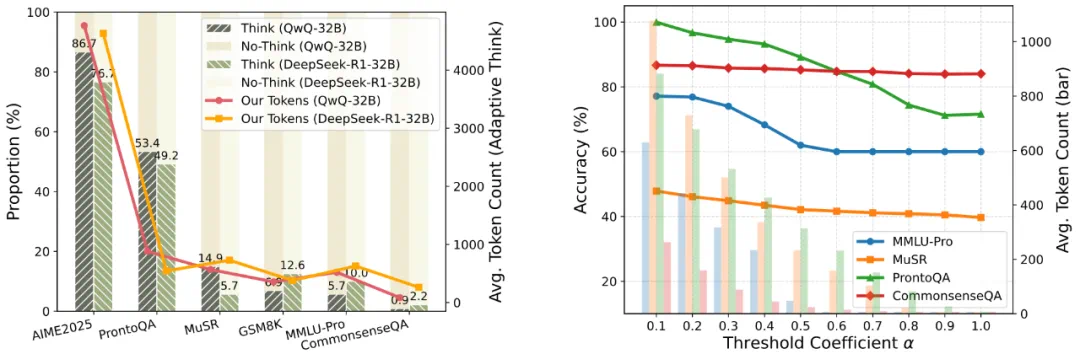
图 5&6:Adaptive Think 输出 token 数量与题目难度的关系(左);阈值 α 对准确率和 token 数量的影响,揭示了 推理性能与计算效率之间的权衡(右)。
这意味着:
真正成熟的推理大模型,不是输出固定长度的推理,而是能够「自动匹配任务难度」。
总结
这篇论文给我们带来一个很重要的理念:AI 推理的未来不在「更长」,而在「更聪明」。
未来的大模型应该:1)在需要深度逻辑时能推理得足够严谨;2)在只需直觉判断时不浪费 token;3)能动态适应任务难度;4)在推理过程中实时自我评估,随时刹车。
这项工作既解释了「为什么模型会过度推理」,也告诉我们「如何简单有效地解决」。
如果说强化学习让模型学会了「怎么想」,那么 Adaptive Think 让模型学会了 「想多久」。
这是推理大模型走向成熟的关键一步。


