一、回顾下 RAG
RAG 的基本工作流程
RAG 的全称是 "Retrieval-Augmented Generation" ,翻译成人话就是"检索增强生成"。听起来还是很专业对吧?让我用一个生活中的例子来解释。
想象你是一个刚入职的新员工,老板突然问你:"咱们公司去年第三季度的销售数据怎么样?"作为新人,你肯定不知道答案。这时候你会怎么办?当然是先去查资料啊!你可能会翻翻公司的财务报表、问问其他同事、查查内部系统,然后把找到的信息整理一下,给老板一个完整的回答。
RAG 就是让 AI 做同样的事情。当你问 AI 一个问题时,它不会直接凭空编造答案(那样容易"胡说八道"),而是会先去"查资料"——从庞大的知识库中搜索相关信息,然后基于这些真实可靠的资料来回答你的问题。这样一来,AI 的回答就有了依据,准确性大大提高。
让我们用一个简单的流程图来看看 RAG 是怎么工作的:
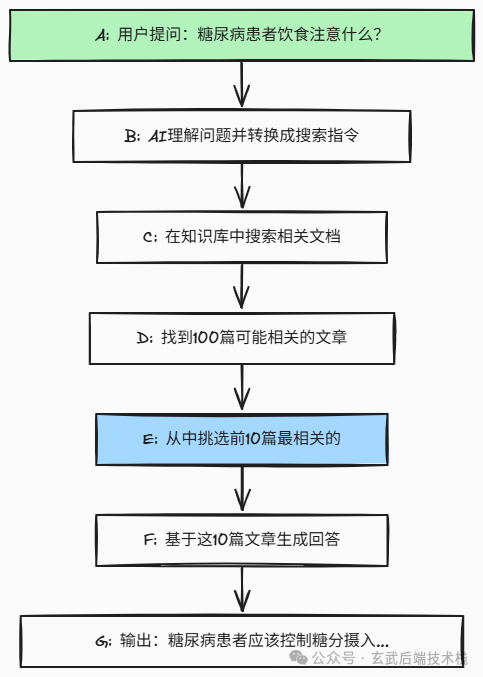 图片
图片
一切都看起来很完美对吧?但实际上,这个流程有一个很大的问题:在第 E 步"挑选前 10 篇最相关的"这里,AI 经常会"挑错"。 它可能把一篇讲糖尿病发病机理的学术论文排在第一位,而把真正实用的饮食指南排在第八位。这就是为什么我们需要 Rerank 技术的原因。
二、Rerank 是什么?
如果把 RAG 比作一个找资料的过程,那么 Rerank 就像是一个经验丰富的智能秘书。当 AI 初步找到了一堆可能有用的资料后,这个"智能秘书"会仔细审查每一份资料,评估它们与你的问题到底有多匹配,计算其相关性,然后重新排列顺序,把最有用的放在最前面。
举个具体例子:你问"如何治疗失眠?" 没有 Rerank 的情况下,AI 可能会这样排序:
- 《睡眠障碍的神经生物学机制研究》(学术性太强)
- 《安眠药的药理作用分析》(太专业)
- 《改善睡眠质量的 10 个小贴士》(这个才是你真正需要的!)
有了 Rerank 之后,排序变成了:
- 《改善睡眠质量的 10 个小贴士》
- 《失眠患者的日常调理方法》
- 《睡前放松技巧大全》 看到区别了吗?Rerank 就像一个懂你的朋友,知道你真正想要的是什么。
三、Rerank 的工作原理:从"粗筛"到"精选"
Rerank 采用的是"两步走"策略,我们用公司招聘过程举例:
第一步:海选(初步检索)
就像公司招聘时先通过简历筛选一样,AI 会快速浏览整个知识库,把所有可能相关的文档都找出来。这一步追求的是"宁可错杀一千,不可放过一个",所以会找到很多文档,几十上百篇,甚至更多。
第二步:面试(Rerank 精选)
接下来就是 Rerank 的主场了。它会像面试官一样,仔细"面试"每一篇文档,问它们:"你真的能回答用户的问题吗?你的内容有多相关?你的信息有多可靠?"然后给每篇文档打分,重新排序。
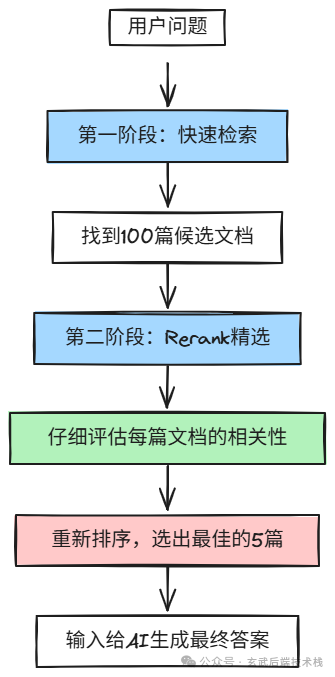 图片
图片
这种"两步走"的好处是既保证了速度(第一步很快),又保证了质量(第二步很准)。
三、Rerank 的特性
语义理解能力
传统的搜索方式主要靠"关键词匹配",就像古代的"对暗号"一样死板。比如你搜"手机发热",它只会找包含"手机"和"发热"这两个词的文章。 但 Rerank 不一样,它具备强大的语义理解能力。即使你问的是"手机烫手怎么办?",它也能理解你说的"烫手"其实就是"发热"的意思,从而找到真正相关的解决方案。
上下文关联分析
Rerank 还能理解词语之间的关联关系。比如当你问"糖尿病患者能吃什么水果?"时,它不仅知道你在问糖尿病,还能理解这个问题涉及到血糖控制、营养成分、水果的糖分含量等多个相关概念,从而找到最全面、最准确的答案。
个性化推荐
更厉害的是,先进的 Rerank 系统还能根据你的提问习惯和背景来调整排序。比如,如果系统发现你经常问一些基础性的健康问题,它就会优先推荐通俗易懂的科普文章,而不是专业的医学论文。
四、Rerank 的技术原理
双编码器 vs 交叉编码器
Rerank 主要用到两种技术方法:
双编码器(就像两个独立的翻译官):
想象有两个翻译官,一个专门翻译你的问题,另一个专门翻译文档内容。他们各自工作,然后比较翻译结果的相似度。这种方法速度快,但有时候会"理解偏差"。
交叉编码器(就像一个全能的分析师):
这就像一个既懂你的问题又懂文档内容的全能分析师,他会把你的问题和每篇文档放在一起综合分析,判断它们的匹配度。虽然慢一点,但准确性更高。
Rerank 通常使用交叉编码器,因为在候选文档数量不多的情况下(比如只有几十篇),准确性比速度更重要。
Rerank 的评分机制
Rerank 给每篇文档打分的过程,就像老师给学生作文打分一样:
- 相关性得分:这篇文档和问题有多相关?(占 40%)
- 完整性得分:这篇文档的信息是否完整?(占 30%)
- 可读性得分:这篇文档是否容易理解?(占 20%)
- 时效性得分:这篇文档的信息是否是最新的?(占 10%) 最后把所有得分加起来,分数最高的文档排在最前面。比如你向 AI 提出"美联储加息对 A 股的影响",通过 Rerank 会得出更可靠的回答。
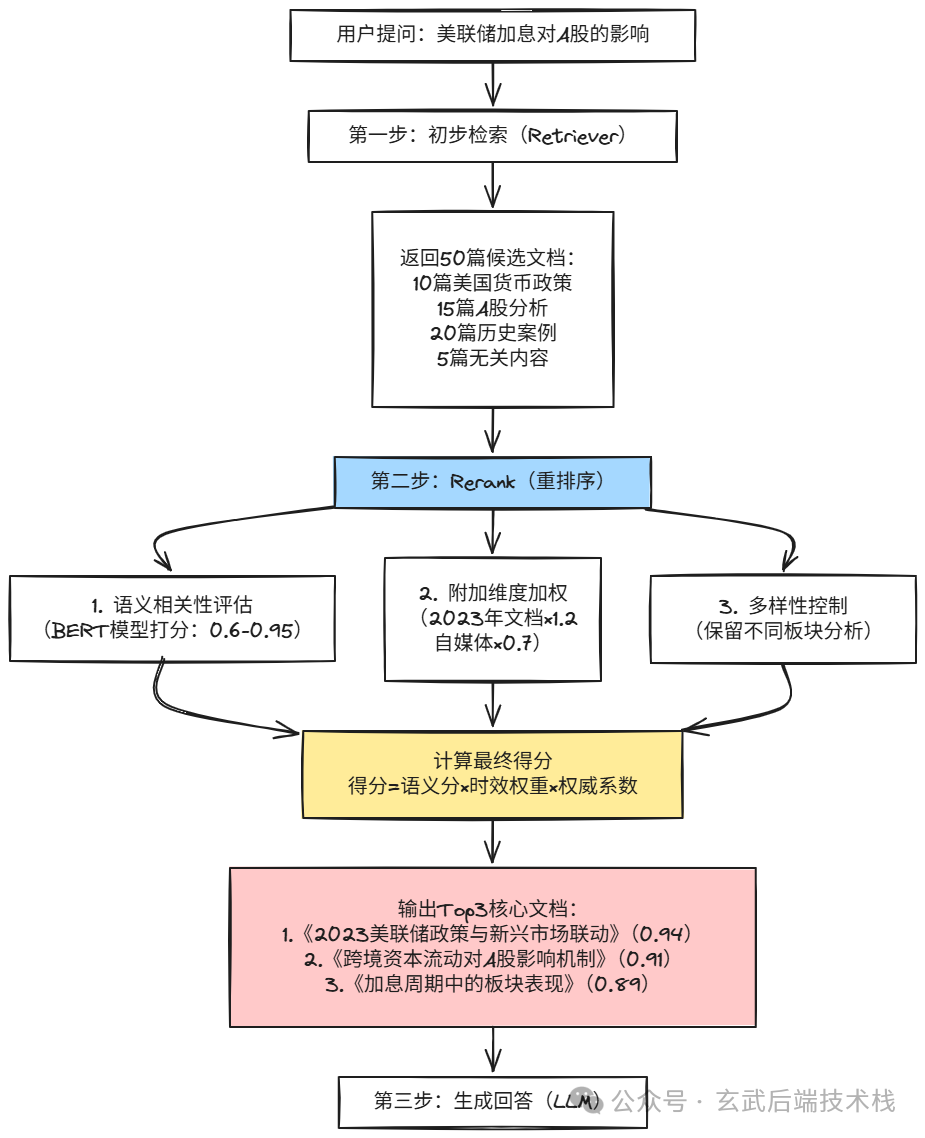 图片
图片
五、常见 Rerank 模型
目前市面上有很多优秀的 Rerank 模型,每个都有自己的特点:
模型对比表
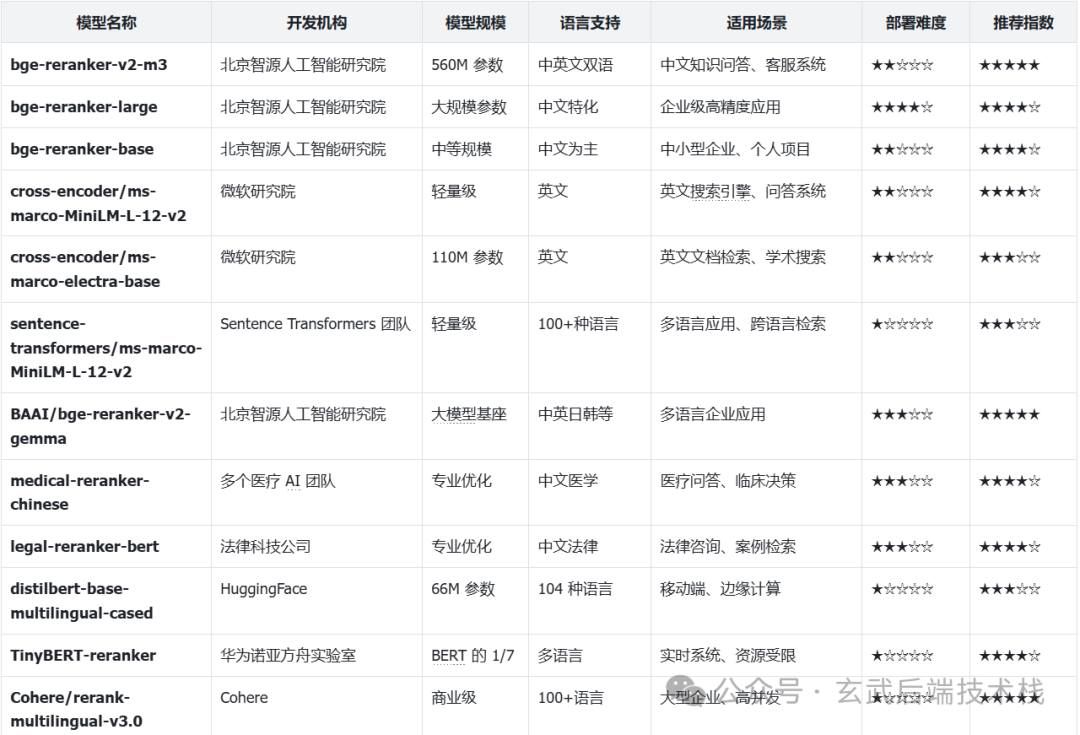 图片
图片
选择建议速查表
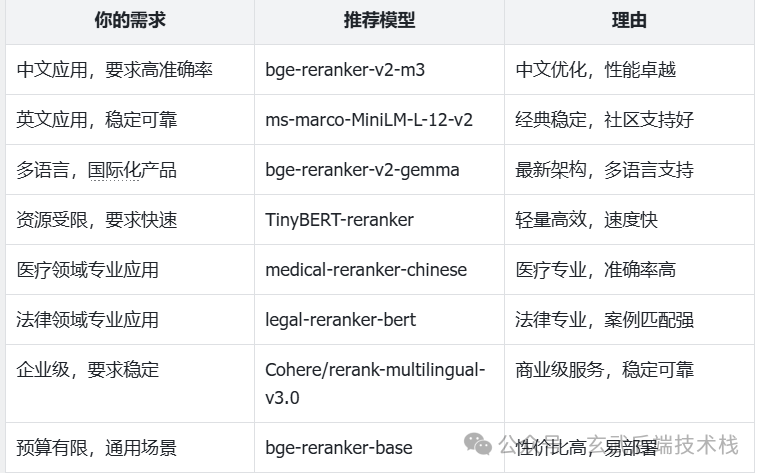 图片
图片
推荐模型详解
bge-reranker-v2-m3
- 优势:中英文双语优化,在中文场景下表现卓越
- 适用场景:中文知识问答、客服系统、文档检索
- 技术特点:560M 参数,支持多语言,部署友好
- 性能指标:NDCG@10 达到 0.67,在中文检索任务中表现优异
Cohere/rerank-multilingual-v3.0
- 优势:商业级稳定性,API 服务便捷
- 适用场景:大型企业应用,高并发场景
- 技术特点:支持 100+语言,云端 API 调用
- 性能指标:多项基准测试中排名前列
TinyBERT-reranker
- 优势:极致轻量,推理速度快
- 适用场景:移动端应用,边缘计算,实时系统
- 技术特点:模型大小仅为 BERT 的 1/7,速度提升 9 倍
- 性能指标:在保持较高准确率的同时大幅提升速度


