
大家好,我是肆零柒。今天,我们一起来了解一篇由OPPO AI Agent Team研究的论文。这项工作名为Chain-of-Agents(CoA),它不只是一个新的AI框架,更是一次对"智能体"本质的深刻探索。研究团队通过多智能体蒸馏和智能体强化学习,成功地将一个由多个专家组成的"智囊团"压缩进了一个单一的、可端到端优化的基础模型中,这究竟是如何做到的?让我们一起了解一下。

一个看似不可能完成的任务
想象这样一个任务:你需要找出某位匿名博主的第一篇博客发布日期,该博客需满足多个严格条件——博主当时是8年级学生、博客发表于2005-2013年间、内容提及因观看某部2002-2010年上映的电影而产生焦虑、还提到博主的母亲和暗恋对象。想一想,如果你是AI系统,会如何解决这个多条件约束问题?是尝试一次性搜索所有条件,还是分步解决?你会如何验证找到的信息是否准确?
传统方法往往直接构建复杂查询:"anonymous blog first posted 8th grade anxiety attack movie review 2005..2013",期望一次搜索就能找到完美匹配的结果。
然而,这种策略几乎注定失败——搜索结果全是关于焦虑障碍和抑郁症的医学文章,而非实际博客内容。这种困境正是Chain-of-Agents(CoA)要解决的核心问题。CoA并不是将多个工具简单串联起来,而是让单一模型动态模拟多智能体协作过程,实现真正的端到-end复杂问题解决。下面我们一起深入理解一下CoA如何巧妙破解这类难题,并揭示其背后的技术内核。
Chain-of-Agents的"啊哈时刻":从失败到成功的思维转变
下面,我们跟随Chain-of-Agents解决这个极具挑战性的"8年级匿名博客"任务,完整体验其思维历程:


初始失败:复杂查询的陷阱
系统首先尝试使用复杂查询直接搜索(Step 3):
复制结果令人失望——返回的内容全是关于焦虑障碍和抑郁症的医学文章,而非实际博客。系统通过自我评估标记为:
复制
这时不妨想想,当搜索结果完全偏离预期时,你会如何调整策略?是稍微简化查询,还是彻底重构搜索思路?
深度反思:发现问题根源
在Step 4,系统激活了反思智能体进行深度分析:
复制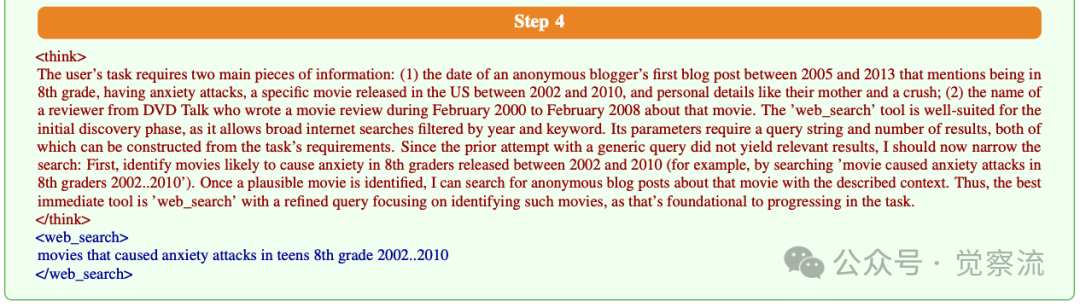

这一反思揭示了关键问题:复杂查询导致搜索结果偏离目标,需要分步重构问题。
策略重构:多步推理
基于反思,系统在Step 5激活计划智能体,制定了清晰的四步策略:
1. 搜索相关电影名称
2. 识别可能引起焦虑的电影
3. 查找博客内容
4. 验证发布日期

在Step 6-15中,系统动态切换搜索智能体和爬取智能体,逐步收集证据:
- 首先识别出《暮光之城》可能是目标电影
- 通过LiveJournal平台找到具体博客
- 确认博客发布日期为2011年10月23日
- 验证博主当时是8年级学生

最终在Step 16,系统自信地给出答案:
复制关键收获:CoA系统不是简单地执行预设流程,而是通过反思-规划-执行-验证的闭环,动态调整策略。当初始方法失败时,它能识别问题根源,重构解决方案,这正是人类专家的思维方式。
思考一下:为什么系统在Step 15选择使用suggested_answer工具而非继续搜索?这反映了CoA的什么核心能力?答案在于double_check评分机制——当系统确认已收集到所有必要信息(博客日期和影评人姓名),且信息一致性高时,它会果断停止搜索。这种"知道何时停止"的能力,避免了传统系统常见的过度搜索问题,也是推理成本降低84.6%的关键原因之一。
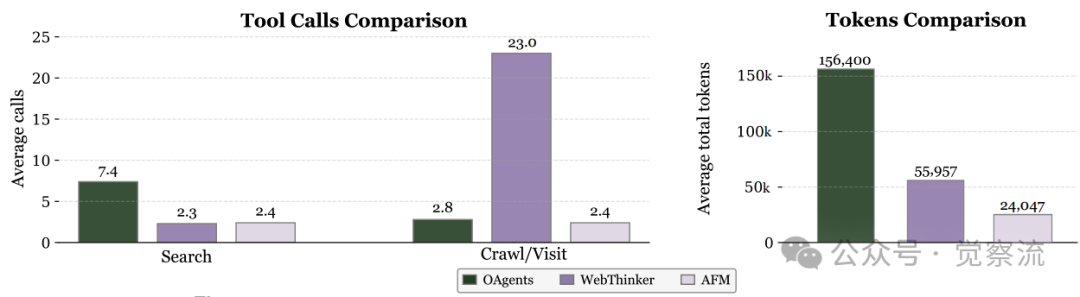
AFM与传统多智能体系统(MAS)和工具集成推理(TIR)方法的性能效率对比。AFM在显著降低推理成本的同时保持了高性能
Chain-of-Agents的临界点突破:从工程框架到可优化模型
Chain-of-Agents的真正突破不在于单个技术点,而在于它解决了智能体系统发展的"临界点"问题——如何将多智能体系统的协作优势内化到单一模型中。
1. 四大范式的对比与CoA的突破

上表:不同智能体范式的对比分析。Chain-of-Agents是唯一同时支持工具集成、端到端执行、多智能体协作和数据驱动优化的范式。
通过对比上表中的数据,我们可以清晰看到CoA的突破性优势:它不仅继承了多智能体系统的协作优势,还解决了传统多智能体系统面临的计算效率低、无法端到端优化等问题。
2. TIR与CoA的本质区别
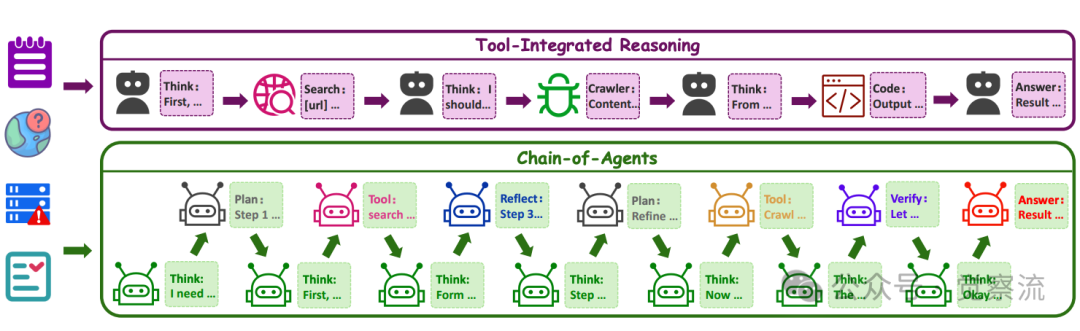
TIR与CoA范式的对比示意图。TIR采用静态的"思考-行动-观察"工作流,而CoA支持可由多智能体系统建模的任何工作流,支持更多样化的角色扮演智能体和工具智能体
在技术内核深度解析部分,我们可以看到Chain-of-Agents的状态转换模型可表示为: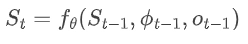
为什么这很重要? 这个看似抽象的数学表达解决了传统多智能体系统的核心痛点——上下文断裂。在传统系统中,每个智能体只能看到有限上下文,导致"工具协调困境";而CoA通过维护持久推理状态,使后续智能体能够基于完整历史进行决策,如同人类专家在解决问题时不断更新自己的"思维笔记"。
在"8年级匿名博客"案例中,当系统从Step 3的失败中学习后,状态记录了"复杂查询不可行"的关键洞察,这直接影响了Step 4的策略调整。如果没有这种状态持续性,系统可能会在每次工具调用后"忘记"之前的教训,重复同样的错误。
实际价值:这正是CoA能够将推理成本降低84.6%的关键技术基础——避免了传统多智能体系统中因上下文分割而导致的重复沟通和信息丢失。
技术内核深度解析:让单一模型学会多智能体协作
Chain-of-Agents的技术突破在于它让单一模型能够模拟多智能体协作过程,而无需依赖复杂的外部框架。让我们深入理解其技术内核,并将每个技术点与实际案例关联。
多智能体蒸馏框架
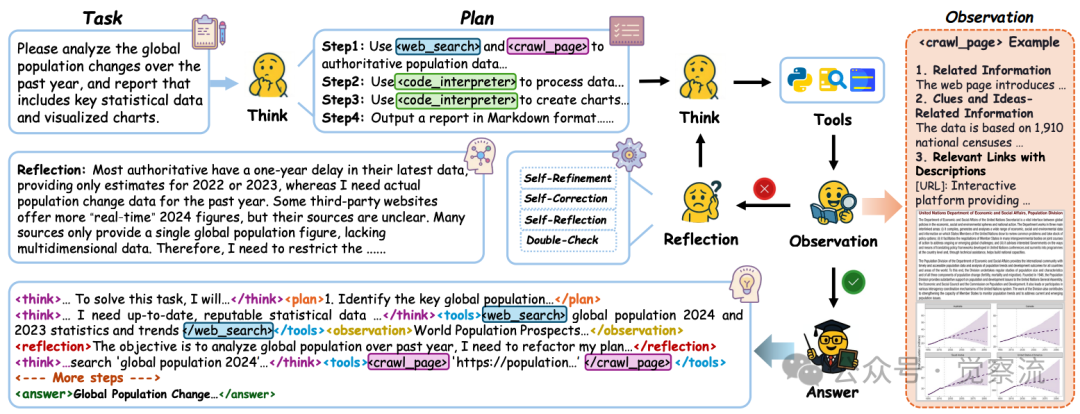
提出的多智能体蒸馏框架示意图,该框架使用最先进的多智能体系统(如OAgents)合成Chain-of-Agents轨迹
多智能体知识蒸馏是CoA的核心技术。研究团队利用OAgents(最先进的开源多智能体系统)来提取Chain-of-Agents轨迹,通过监控其执行过程,记录每个智能体的激活、推理状态和输出。这种方法将序列级知识蒸馏原则扩展到多智能体领域,捕获专家多智能体系统的完整执行轨迹,而非仅仅是单词级分布。
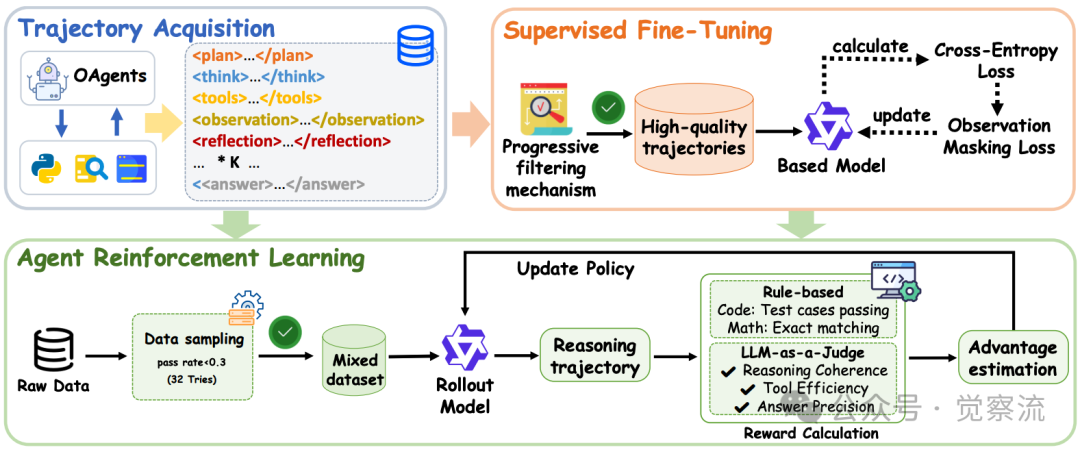
训练框架概述。(I) SFT阶段使用重新格式化的ReAct数据(包含短链和长链思维)进行冷启动。(II) RL阶段在未使用的QA对上执行工具感知rollouts并优化策略。
在"8年级匿名博客"案例中,我们看到:
- 当初始搜索失败时,系统自动激活反思智能体进行策略评估
- 确定新策略后,系统激活计划智能体生成分步执行计划
- 执行过程中,系统动态切换搜索智能体和爬取智能体
这种动态角色切换是传统单智能体系统无法实现的。"Chain-of-Agents中的多智能体协作并非简单的平等协作,而是存在明确的层次结构。思考智能体(Thinking Agent)作为'元控制器',负责整体协调;计划智能体(Plan Agent)和反思智能体(Reflection Agent)构成中层决策层;而工具智能体则位于执行层。"
观察掩码损失:从噪声中提取关键信息
观察掩码损失(Observation Masking Loss)是CoA训练中的关键技术,它使模型学会区分可靠信息与噪声。在案例中,当系统爬取LiveJournal页面时,返回了大量无关链接(如"[FAQ] (URL)"和"[Site Map] (URL)"),观察掩码损失帮助模型忽略这些噪声,专注于提取"October 23, 2011"这样的关键日期信息。
实际价值:没有这一机制,系统可能会被环境噪声误导,导致推理路径偏离。正是这种从噪声中提取信号的能力,使CoA在真实世界任务中表现出色。
性能优势的直观解读:数据背后的真相
Chain-of-Agents的优势不仅体现在理论层面,更在实证研究中得到验证。让我们深度理解一下关键性能数据,理解CoA为何是智能体技术的重要突破。
GAIA基准测试:复杂任务上的优势
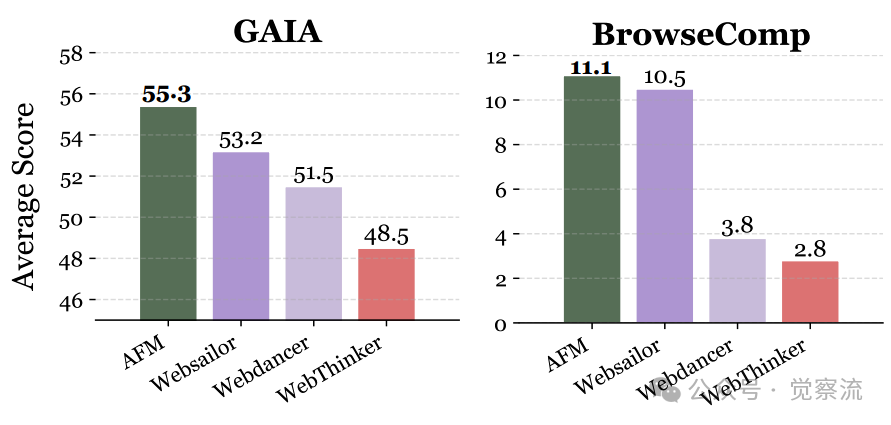
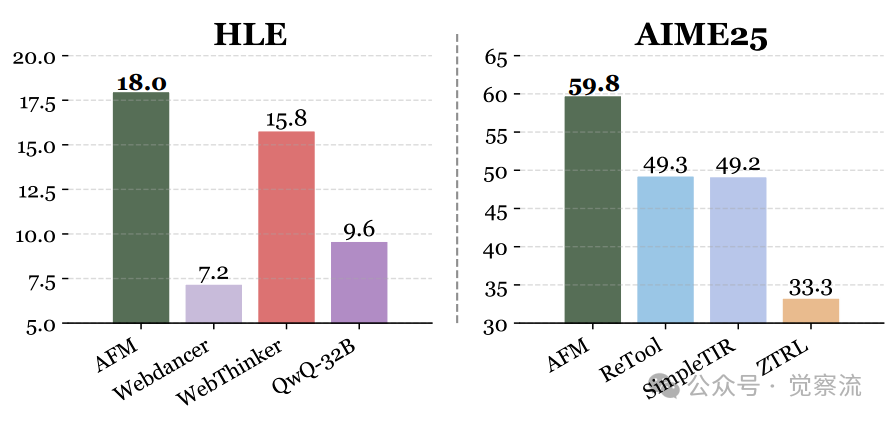
AFM与最先进的工具集成推理(TIR)方法在GAIA、BrowseComp、HLE和AIME25基准测试中的性能对比。AFM在网页智能体和代码智能体基准测试中均表现出一致的有效性
上图展示了Chain-of-Agents的突破性价值。观察GAIA基准测试中不同难度级别的表现:
- Level 1任务(基本任务):AFM-RL (7B) 达到53.8%,超过了WebThinker-RL (QwQ-32B)的53.8%(持平),显著优于WebDancer的46.1%
- Level 2任务(中等难度):AFM-RL (7B) 达到32.7%,虽略低于WebThinker-RL的44.2%,但优于WebDancer的30.7%
性能跃迁:AFM 在多项高难度的网页智能体基准测试中刷新 Pass@1 成绩,达到新的 SOTA:GAIA 55.3%,BrowseComp 11.1%,HLE 18.0%。与WebSailor相比,AFM在GAIA测试中高出2.1个百分点(55.3% vs 53.2%),在BrowseComp上高出0.6个百分点(11.1% vs 10.5%),在HLE上高出2.2个百分点(18.0% vs 15.8%)。这些看似微小的差距,实际上代表了智能体技术的重要进步。
从实验室到实际应用
Chain-of-Agents的出现不仅是技术上的突破,更为智能体技术的发展开辟了新方向。
1. 多智能体蒸馏的扩展与优化
当前的多智能体蒸馏框架主要关注任务执行轨迹,未来可能扩展至:
- 情感与风格蒸馏:不仅学习如何解决问题,还学习专家的表达风格和决策偏好
- 跨领域蒸馏:将特定领域的专业知识(如医学、法律)更有效地迁移到通用智能体中
- 人类反馈整合:结合人类专家的实时反馈,进一步优化蒸馏过程
研究团队将所有代码、数据和模型完全开源的决定,为智能体模型和agentic RL研究提供了坚实起点。 这一开放态度将加速这些扩展方向的研究。
2. 智能体强化学习的进阶
未来的agentic RL可能在以下方向取得突破:
- 更精细的奖励设计:针对不同任务类型设计差异化的奖励函数
- 长期规划能力:增强模型在超长推理链中的保持能力
- 不确定性感知:让模型能够识别自身知识的边界,避免过度自信
研究还提到了RL训练过程中的关键观察:在代码智能体的强化学习训练过程中,研究团队持续跟踪训练奖励与回复长度的变化趋势。随着训练步数增加,模型逐步学会更高效的解题策略:既压缩了冗余的冗长输出,又显著提升了任务完成率。
这种优化过程表明,agentic RL能够有效引导模型发展出更精炼、更有效的推理路径。
3. 未见智能体的泛化能力
AFM展示了出色的未见智能体泛化能力:尽管在训练时仅接触过Python解释器,但模型能够正确编排Web搜索等未见过的工具。在GAIA测试集上的零样本评估中,模型能够严格遵循提示指定的格式,展示了强大的泛化能力。
在"Chain-of-Agents"框架下,研究者评估了模型的零样本智能体泛化能力。训练阶段,代码智能体模型仅接触过由 Python 解释器执行的代码与数学任务,从未见过网页搜索、视觉检测等工具智能体。推理时,将完整的工具描述和调用格式显式写进提示,并以 GAIA 测试集作为任务基准。结果显示,代码智能体严格遵循提示中的格式要求,并能够正确调用这些从未见过的工具。
这种泛化能力如何应用于实际场景?例如,在企业环境中,新工具可能随时加入系统。AFM的泛化能力意味着:
- 无需重新训练即可支持新工具
- 能够理解工具之间的逻辑关系
- 可以根据任务需求智能组合不同工具
这种能力对于构建灵活、可扩展的企业级智能体系统至关重要。
如何有效应用Chain-of-Agents
对于希望应用Agent Foundation Models(AFM)的开发者,以下是一些实用建议:
1. 系统环境配置:确保安全执行
研究中使用nsjail提供了细粒度的资源限制,对AFM模型设置了5秒CPU时间上限和5GB内存限制,以确保受控执行。这种安全机制对于防止恶意代码执行和资源滥用至关重要。
重要提示:在部署代码生成智能体时,务必实施严格的沙盒环境,限制执行时间和内存使用,避免潜在的安全风险。
2. 推理服务搭建:支持动态角色切换
API设计应充分考虑Chain-of-Agents的多智能体特性,支持动态角色切换和工具调用。性能优化方面,可以利用AFM显著降低的token消耗优势,在保持性能的同时大幅减少计算资源需求。
重要提示:设计API时,应允许客户端指定可用工具集,并提供清晰的错误反馈机制,帮助模型在工具调用失败时进行有效调整。
3. 工具协调难题解决
通过设计双向搜索与代码工具交互机制,提升复杂任务处理能力。例如,在处理需要验证的数据时,让搜索工具的结果直接作为代码工具的输入,实现工具间的无缝协作。
注意:当构建需要多工具协作的任务时,明确设计工具间的输入输出接口,确保信息能够流畅传递。例如,搜索结果应以结构化格式提供,便于代码工具直接处理。
"Chain-of-Agents的自我评估机制是其卓越性能的核心。通过information_conflict、tool_effectiveness和trajectory_monitoring三大评估指标,系统能够实时监控推理过程质量,并据此进行动态调整。"
随着研究团队将所有代码、数据和模型完全开源,我们可能会看到更多基于CoA范式的创新应用,在深度研究、vibe coding和数学推理等复杂任务中发挥更大作用。总体而言,Chain-of-Agents不仅解决了工具协调困境和多智能体转移困境,还大幅提升了系统效率和问题解决能力。这一思路可能为未来AI系统的设计提供新的灵感和方向,让智能体进化的更加高效、灵活和强大。


