专门适用超大模型、带来2.18倍推理加速,最新投机采样训练框架开源!
SGLang团队联合美团搜推平台、Cloudsway.AI开源SpecForge。
SGLang,当前趋势下最受青睐的推理框架之一,为DeepSeek提供了专属优化,也深受英伟达、AMD、xAI等厂商喜爱。
这一次开源,主要是针对当下超大模型趋势。
随着Kimi K2、Qwen Coder的开源,越来越多的超大型模型进入大家的视野。这些模型具有强劲的性能,但受制于模型尺寸导致推理效率较低。对于超大尺寸的模型,除了进一步优化算子之外。还有像投机采样这样的技术能加速它们的推理。
投机采样(Speculative Sampling)通过引入轻量级的辅助模型来提升推理效率,同时确保结果的质量和正确性。
目前性能强劲的投机采样技术分别有MTP和Eagle3,但MTP其需要在预训练阶段与基础模型一起训练,限制了MTP在业界的广泛应用。而Eagle3作为一种训练后而集成的技术,很适合在已开源的超大尺寸模型上继续训练,而进一步提升推理效率。
SpecForge正是基于Eagle3,它不仅是首个支持超大模型投机采样训练并开箱即用的框架,还与SGLang推理引擎深度集成。一键打通投机采样训练推理全流程。
为何推出新的Spec训练框架?
投机采样(speculative decoding)已成为大语言模型(LLM)推理加速的共识方案,但其端到端训练工具的缺失仍是明显短板。目前开源社区中,尚无能够支持超大尺寸模型训练且与SGLang深度结合的框架,而这些工具层面的不足,直接导致此类模型的部署面临巨大挑战。
SpecForge为此而来,一个专为投机采样训练而生、并与SGLang原生集成的生态系统,其核心功能包括:
- 原生支持最新开源架构:SpecForge支持主流模型,包括复杂的MoE层和Transformer变体。
- 可扩展的分布式训练:SpecForge集成了FSDP(Fully Sharded Data Parallel)和TP(Tensor Parallelism)等并行策略,可在GPU集群上实现高效扩展。
- 内存高效训练优化:显著降低了大规模模型训练时的内存开销;即使是万亿参数的基础模型,训练Eagle3也同样高效。
SpecForge核心特性
Eagle3集成
Eagle是一种最先进的投机采样方法,旨在加速大型语言模型推理。它通过训练一个专门的轻量级草稿模型来准确预测较大目标模型的token分布,从而实现高接受率和显著的性能提升。下图展示了Eagle3的端到端训练流程:
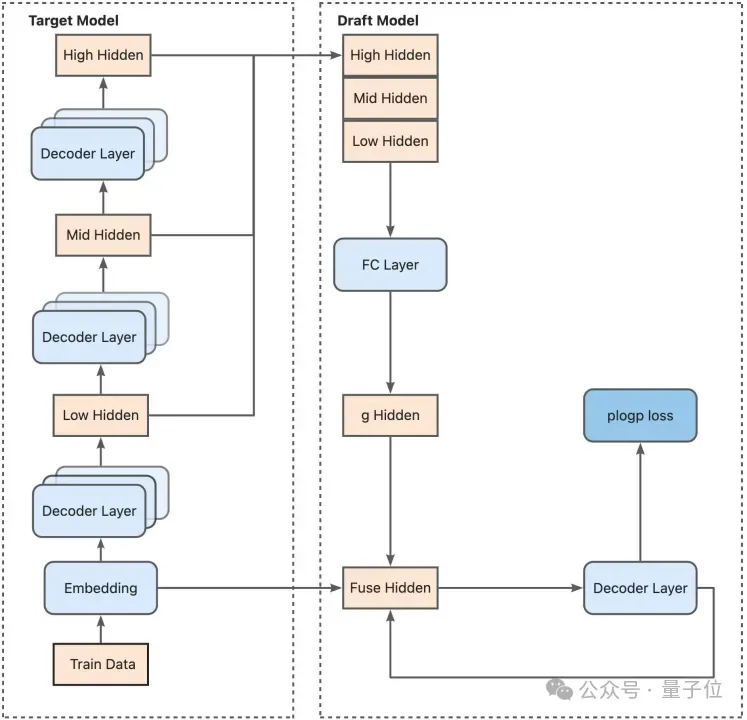
训练时测试(TTT)支持
EAGLE3的高性能提升主要来源于其创新的训练时测试(Training-Time Test)架构,该架构通过模拟多步生成来增强草稿模型的健壮性。尽管TTT性能强大,但其实现却极具有挑战性,因为它依赖于复杂的专用注意力掩码(specialized attention masks)和递归式数据循环(recursive data loops)。
SpecForge将这一复杂过程完全封装,提供了内置且经过验证的TTT支持。实现严格参照了官方Eagle3的核心逻辑,以确保其计算的正确性与性能,从而免除底层实现负担。
双重训练模式:在线与离线
SpecForge通过提供两种训练模式:在线(Online)和离线(Offline)来简化隐藏状态的收集,隐藏层的收集是Eagle类模型的特点。它通过主模型的隐藏层训练草稿模型,让草稿模型整体分布和主模型对齐。
该框架的双模式设计能让用户能找到高效的训练模式,关于在线和离线训练的优缺点如下文所示。
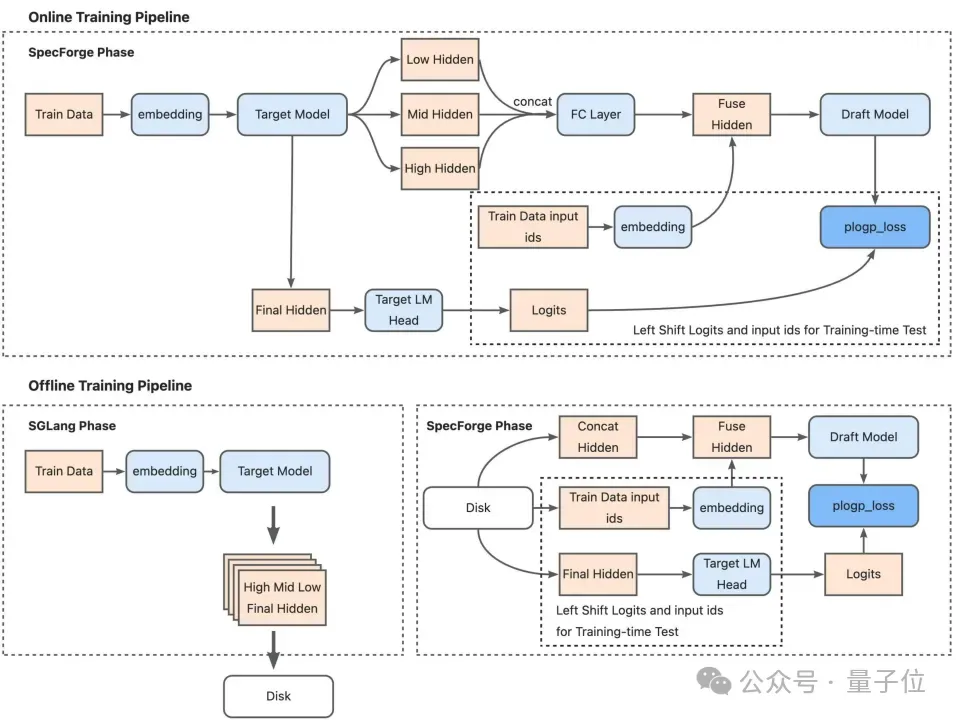
选择在线或离线模式,可以根据您的具体需求和资源调整训练过程。
- 在线模式:可实现最大速度和灵活性。它非常适合快速实验和存储有限的场景,因为它能动态生成数据,无需大量磁盘空间。
- 离线模式:适用于可复现性和数据复用至关重要的场景。通过预先计算和存储隐藏状态,此模式可保证实验之间的一致性,在存储空间充足时效率很高。
扩展性优先
SpecForge在设计时高度重视可扩展性,以满足工程生产需求。该框架使用模块化接口实现了新草稿模型和主模型的直接实现和注册。
为了实现可扩展性,团队实现了多种训练时并行策略。包括FSDP(Fully Sharded Data Parallel) 和TP并行实现,确保超大型模型的高效训练。
实验
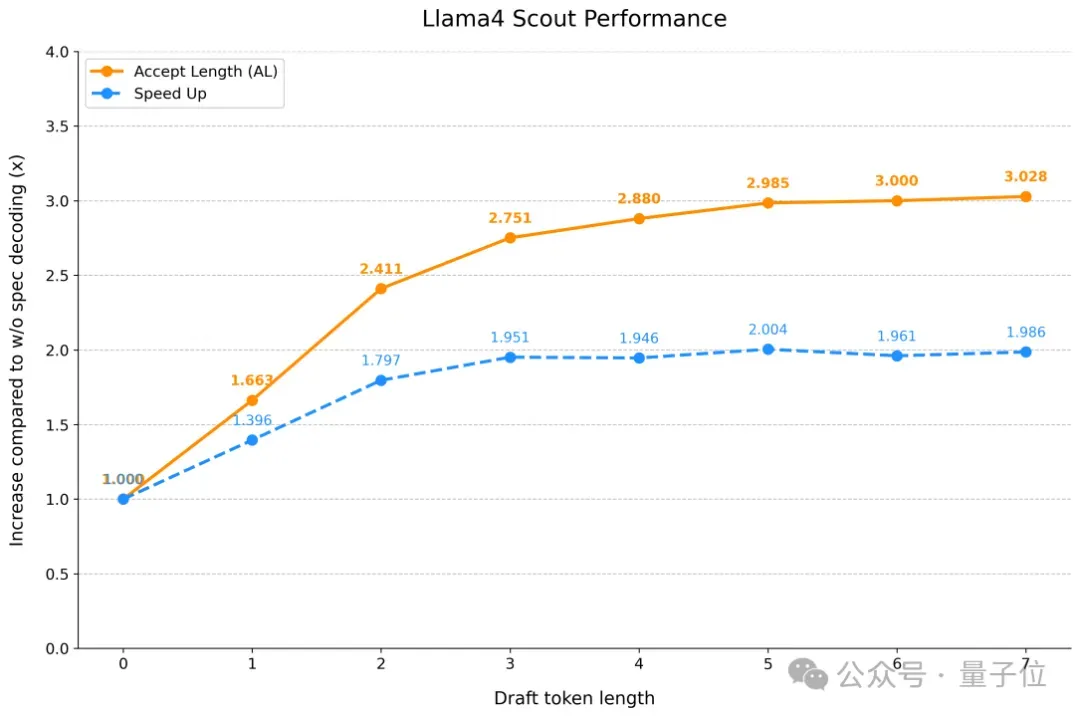
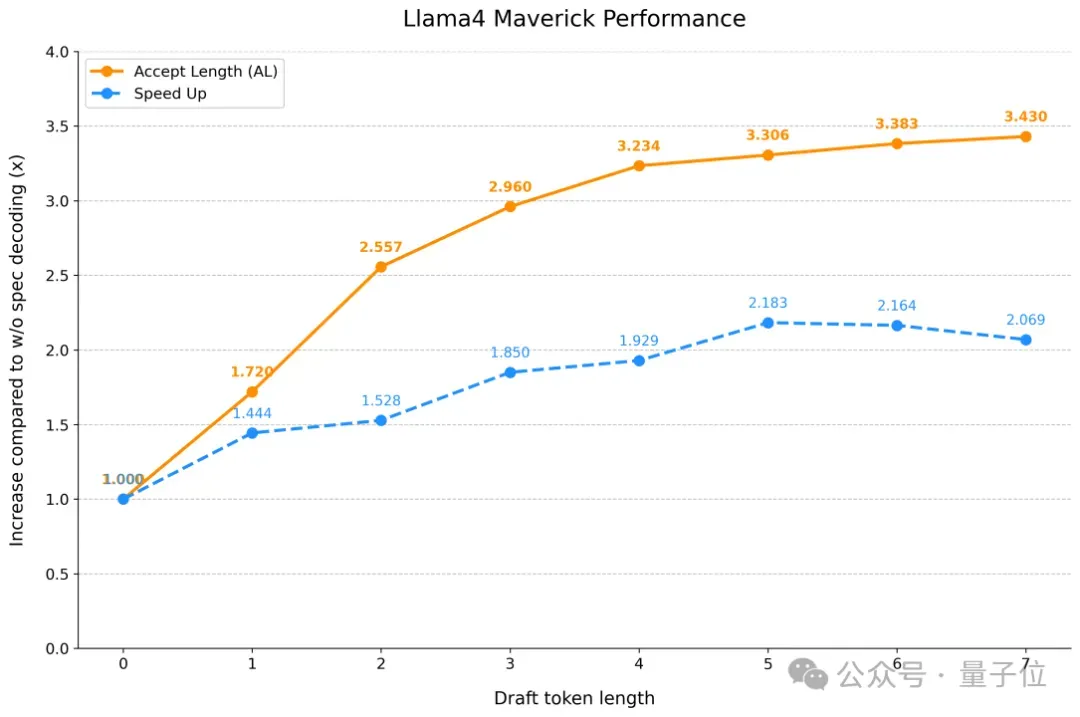
为验证SpecForge的有效性,团队利用它在包含320K样本的ShareGPT和UltraChat数据集上,为LLaMA 4训练了Scout和Maverick草稿模型。
这些模型在MT-Bench等行业标准基准上表现出色,充分证明了其模型质量以及与Eagle3架构的兼容性。特别值得一提的是,团队为Llama 4 Maverick训练的草稿模型在MT-Bench上实现了2.18倍的推理加速。
详细的实验结果与性能指标总结如下。
在下图所示的所有测试中,x轴代表投机采样步长,对应于SGLang中的speculative-num-steps。同时,将 SGLang 的speculative-eagle-topk固定为8,将speculative-num-draft-tokens固定为10,这样可以使用 tree attention达到更高的接受率。为了找到最优的投机采样参数,可以使用SGLang代码库中的bench_speculative脚本。该脚本会在不同配置下运行吞吐量基准测试,针对硬件调优出最佳性能。
最后,可以在GitHub上查看源代码,并在Hugging Face上试用已训练的模型。
GitHub仓库: 训练框架的完整源代码,包括TTT和数据处理的实现细节。https://github.com/sgl-project/SpecForge
Hugging Face模型:下载LLaMA 4 Scout(https://huggingface.co/lmsys/sglang-EAGLE3-Llama-4-Scout-17B-16E-Instruct-v1)和Maverick(https://huggingface.co/lmsys/sglang-EAGLE3-Llama-4-Maverick-17B-128E-Instruct-v1)Eagle3 heads(不含完整模型)用于您的项目。
SpecForge的Roadmap如下:
- 支持更多模型架构,包括Kimi K2和Qwen-3 MoE。
- 将视觉-语言模型 (VLM) 集成到 SpecForge 中。
- 通过更好的并行策略和kernel优化来支持更高效的训练。
Blog地址:https://lmsys.org/blog/2025-07-25-spec-forge/
团队成员
SGLang核心团队:Shenggui Li、Shuai Shi、Fan Yin、Yikai Zhu、Yi Zhang、Yingyi Huang、Yineng Zhang 及其他成员。
美团搜推平台:Chao Wang
SafeAILab团队:Yuhui Li、Hongyang Zhang及其成员


