仅需一个强化学习(RL)框架,就能实现视觉任务大统一?
现有RL对推理和感知任务只能二选一,但“大模型六小强”之一MiniMax表示:我全都要!
最新开源V-Triune(视觉三重统一强化学习系统)框架,使VLM首次能够在单个后训练流程中,联合学习和掌握视觉推理和感知任务。
通过三层组件设计和基于动态交并比(IoU)的奖励机制,弥补了传统RL方法无法兼顾多重任务的空白。

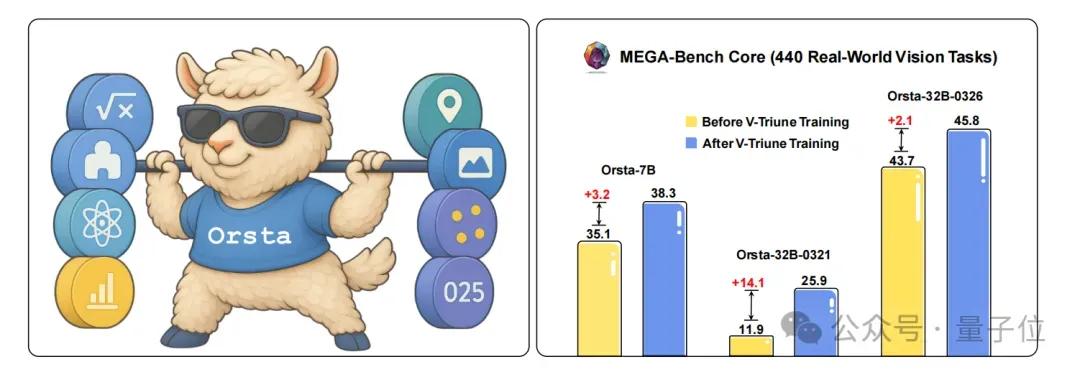
甚至基于V-Triune,MiniMax还一步到位,贴心地给大家开发了全新的Orsta(One RL to See Them All)模型系列(7B至32B),在MEGA-Bench Core基准测试中从+2.1%显著提升至+14.1%。
值得注意的是,在论文的作者一栏,MiniMax创始人兼CEO闫俊杰也参与了这项研究。

目前V-Triune框架和Orsta模型都在GitHub上实现全面开源,点击文末链接即可跳转一键获取。
那话不多说,咱们直接上细节。
推理感知“两手抓”
视觉任务可以分为推理和感知两类,在当前,RL研究主要集中于数学QA和科学QA等视觉推理任务。
而目标检测和定位等视觉感知任务,因亟需独特的奖励设计和训练稳定性保障,还没有得到一个很好的解决方案……
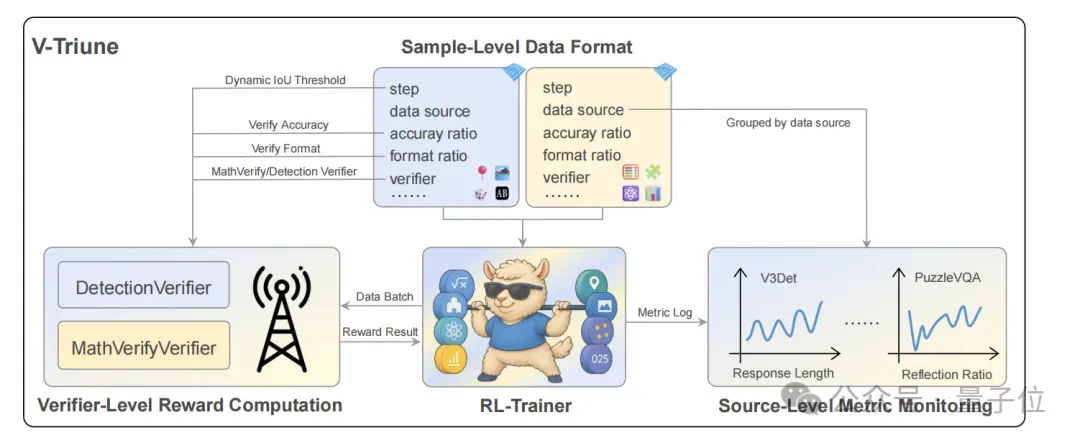
针对上述问题,MiniMax针对性地提出了新框架V-Triune,作为首个面向VLM后训练的统一RL系统,通过三个互补组件核心巧妙实现二者的平衡。
样本级数据格式化
让每个样本自定义其奖励设置和验证器,支持动态路由和权重调整,以处理多种任务需求。
数据模式基于HuggingFace数据集实现,包含以下三个字段:
- reward_model:样本级定义奖励类型、权重。
- verifier:指定验证器及其参数。
- data_source:标识样本来源。
最终实现了多样化数据集的无缝集成,同时支持高度灵活的奖励控制。
验证器级奖励计算
采用异步客户端-服务器架构,将奖励计算与主训练循环解耦。
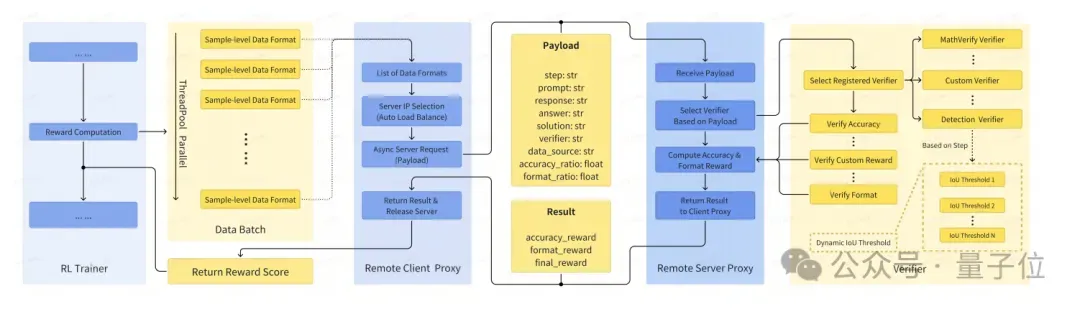
客户端通过代理工作器异步发送请求,而服务器则根据”verifier”字段路由至专用验证器。
主要使用两类验证器:
- MathVerifyVerifierr:处理推理、OCR和计数任务。
- DetectionVerifier:处理检测和定位任务,应用动态IoU奖励。
从而实现在无需修改核心训练流程的情况下,灵活扩展新任务或更新奖励逻辑。
数据源级指标监控
在多任务多源训练中,按数据源记录以下指标:
- 奖励值:追踪数据集特定稳定性。
- IoU和mAP(感知任务):记录不同阈值下的IoU和mAP。
- 响应长度和反思率:跟踪响应长度分布、截断率,以及15个预定义反思词(如“re-check”)的出现比例。
该监控机制帮助诊断模型行为(如过度思考或肤浅响应),并确保学习的稳定性。
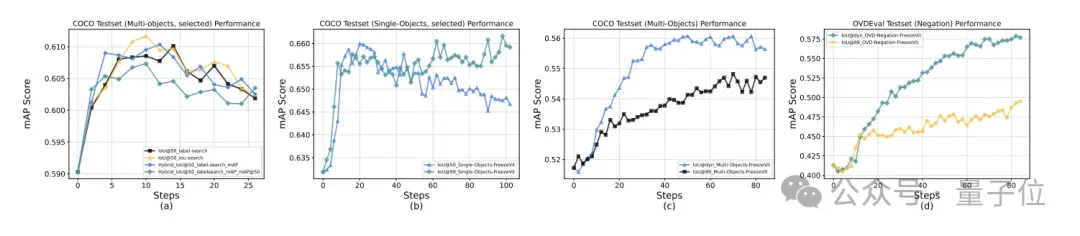
动态IoU奖励
此外针对监测和定位任务,团队还创新性地提出了动态IoU奖励,分阶段调整阈值,以缓解冷启动问题,同时引导模型逐步提升定位精度:
- 初始10%训练步骤:
- 10%-25%训练步骤:
- 剩余训练步骤:
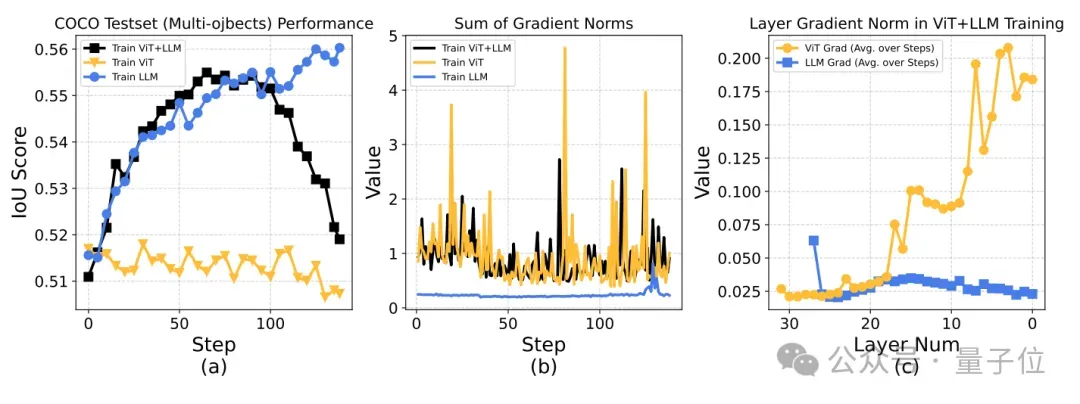
虽然V-Triune提供了可扩展的数据、任务和指标框架,但早期实验显示,联合训练可能会导致评估性能下降、梯度范数突增等不稳定现象,于是团队又通过以下调整逐步解决:
- 冻结ViT参数,防止梯度爆炸。
- 过滤伪图像特殊词元,确保输入特征对齐,提升训练稳定性。
- 构建随机化CoT提示池,降低提示依赖性。
- 由于V-Triune基于Verl框架实现,主节点内存压力较大,需解耦测试阶段与主训练循环以管理内存。
Orsta模型
另外值得一提的是,基于开源的Qwen2.5-VL模型,团队还训练出7B和32B的Orsta模型。

依据4类推理任务(数学、谜题、科学、图表分析)和4类感知任务(物体检测、目标定位、计数、OCR)的训练数据,进行规则和难度的两阶段过滤和训练优化。
最终实现在MEGA-Bench Core基准测试中,Orsta相比原始模型提升至+14.1%,尤其是在感知任务中,mAP指标显著提高,证明了该统一方法的有效性和可扩展性。

MiniMax布局多模态领域
MiniMax作为商汤背景出身的AI六小龙之一,近期在多模态领域可谓动作频频,模型横跨语言、音频、视频。

例如MiniMax的S2V-01视频模型、MiniMax-VL-01视觉多模态模型以及MiniMax-T2A-01系列语言模型等。
尤其是广受好评的MiniMax-01系列,包含基础语言模型和视觉多模态模型两种,性能上比肩DeepSeek-V3、GPT-4o等国内外顶尖模型的同时,还首次创新性实现了对新型Lightning Attention架构的大规模扩展。
最新发布的Speech-02,在AI语言生成上也是一骑绝尘,直接刷新全球权威语音基准测试榜单第一,一举打破OpenAI、ElevenLabs的行业垄断。
同时,据MiniMax高级研究总监钟怡然同量子位访谈时所说:
MiniMax将会进一步探索多模态架构创新,即原生的生成理解统一大模型的架构。
而今天这个统一视觉任务的RL架构也许仅仅是一个开始。
论文链接:https://arxiv.org/abs/2505.18129代码链接:https://github.com/MiniMax-AI/One-RL-to-See-Them-All


