应用

第二波!2024年1月精选实用设计工具合集
大家好,这是进入 2024 年 1 月的第二波干货合集!除了精选免费图库和地图海报生成器之外,这次干货合集所推荐的其他的都是 AI 加持的设计工具,其中阿里出品的开源 AI 换装工具和基于 AI 的动画编辑器非常惊艳,而 AI 辅助 Web 组件生成平台可以说是次世代 AI 工具,值得关注。
当然,在此之前记得看看往期干货中有没有你感兴趣的素材:下面我们具体看看这一期的干货:
1、设计师精选免费图库
AI 文生图越来越多,免费图库的生存空间受到冲击,如今新出的图库很少。最近偶然看到这个名为 Designers P

低耗能高速度,EPFL和微软研究团队的新方法:深度物理神经网络的无反向传播训练
编辑 | 萝卜皮随着大规模深度神经网络(NN)和其他人工智能(AI)应用的最新发展,人们越来越担心训练和操作它们所需的能源消耗。物理神经网络可以成为这个问题的解决方案,但传统算法的直接硬件实现面临着多重困难。使用传统反向传播算法训练神经网络会面临一些挑战,例如缺乏可扩展性、训练过程中操作的复杂性以及对数字训练模型的依赖。洛桑联邦理工学院(École Polytechnique Fédérale de Lausanne,EPFL)和微软研究团队(Microsoft Research)等机构组成的合作团队提出了一种通过

灵敏度超40%、精度达90%的从头肽测序,一种深度学习驱动的串联质谱分析方法
编辑 | 萝卜皮与 DNA 和 RNA 不同,蛋白质缺乏准确和高通量的测序方法,这阻碍了蛋白质组学在序列未知的应用中的实用性,包括变体调用、新表位鉴定和宏蛋白质组学。德国慕尼黑工业大学(Technische Universität München,TUM)的研究人员推出了 Spectralis,一种用于串联质谱分析的从头肽测序方法。Spectralis 利用了多项创新,包括连接按氨基酸质量间隔的光谱峰的卷积神经网络层、提出碎片离子系列分类作为从头肽测序的关键任务,以及肽谱置信度评分。对于数据库搜索提供的真实光谱,S

OPPO Find X7 Ultra 发布,定义移动影像的终极形态
2024年1月8日,深圳——OPPO发布地表最强的封神旗舰Find X7 Ultra,定义移动影像的终极形态。Find X7 Ultra 首创的双潜望四主摄构成哈苏大师镜头群,以六个光学品质焦段提供目前手机最强大、品质最高的多摄变焦能力。首次搭载专为超光影图像引擎定制的一英寸传感器,Find X7 Ultra再次刷新移动影像天花板。通过首创哈苏回眸人像功能,Find X7 Ultra重新定义高度灵活的下一代人像拍摄体验。全新一代超光影图像引擎,以细腻的中间调表现再次定义计算摄影发展的风向标。Find X7 Ultr
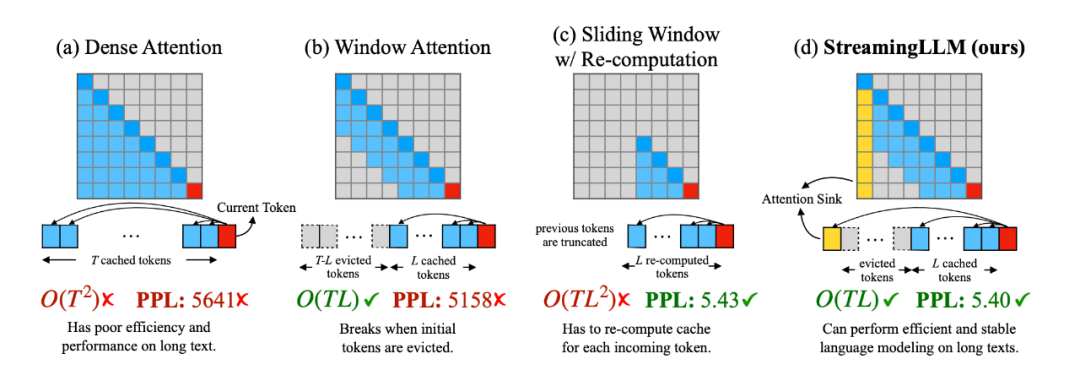
多轮对话推理速度提升46%,开源方案打破LLM多轮对话的长度限制
在大型语言模型(LLM)的世界中,处理多轮对话一直是一个挑战。前不久麻省理工 Guangxuan Xiao 等人推出的 StreamingLLM,能够在不牺牲推理速度和生成效果的前提下,可实现多轮对话总共 400 万个 token 的流式输入,22.2 倍的推理速度提升。但 StreamingLLM 使用原生 PyTorch 实现,对于多轮对话推理场景落地应用的低成本、低延迟、高吞吐等需求仍有优化空间。Colossal-AI 团队开源了 SwiftInfer,基于 TensorRT 实现了 StreamingLLM

轻量级模型,重量级性能,TinyLlama、LiteLlama小模型火起来了
小身板,大能量。当大家都在研究大模型(LLM)参数规模达到百亿甚至千亿级别的同时,小巧且兼具高性能的小模型开始受到研究者的关注。小模型在边缘设备上有着广泛的应用,如智能手机、物联网设备和嵌入式系统,这些边缘设备通常具有有限的计算能力和存储空间,它们无法有效地运行大型语言模型。因此,深入探究小型模型显得尤为重要。接下来我们要介绍的这两项研究,可能满足你对小模型的需求。TinyLlama-1.1B来自新加坡科技设计大学(SUTD)的研究者近日推出了 TinyLlama,该语言模型的参数量为 11 亿,在大约 3 万亿个

吃了几个原作者才能生成这么逼真的效果?文生图涉嫌视觉「抄袭」
虽然提示词只是要生成「动画版的玩具」,但结果和《玩具总动员》没有区别。不久之前,《纽约时报》指控 OpenAI 涉嫌违规使用其内容用于人工智能开发的事件引起了社区极大的关注与讨论。GPT-4 输出的许多回答中,几乎逐字逐句地抄袭了《纽约时报》的报道:图中红字是 GPT-4 与《纽约时报》报道重复的部分。对此,各个专家分别有不同的看法。机器学习领域权威学者吴恩达对 OpenAI 和微软表示了同情,他怀疑 GPT「存在抄袭」的原因并不只是模型训练集使用了未经授权的文章,而是来自类似于 RAG(检索增强生成)的机制。Ch

AI解读视频张口就来?这种「幻觉」难题Vista-LLaMA给解决了
Vista-LLaMA 在处理长视频内容方面的显著优势,为视频分析领域带来了新的解决框架。近年来,大型语言模型如 GPT、GLM 和 LLaMA 等在自然语言处理领域取得了显著进展,基于深度学习技术能够理解和生成复杂的文本内容。然而,将这些能力扩展到视频内容理解领域则是一个全新的挑战 —— 视频不仅包含丰富多变的视觉信息,还涉及时间序列的动态变化,这使得大语言模型从视频中提取信息变得更为复杂。面对这一挑战,字节跳动联合浙江大学提出了能够输出可靠视频描述的多模态大语言模型 Vista-LLaMA。Vista-LLaM

顺着网线爬过来成真了,Audio2Photoreal通过对话就能生成逼真表情与动作
多模态的发展已经开始超乎我们的想象了。当你和朋友隔着冷冰冰的手机屏幕聊天时,你得猜猜对方的语气。当 Ta 发语音时,你的脑海中还能浮现出 Ta 的表情甚至动作。如果能视频通话显然是最好的,但在实际情况下并不能随时拨打视频。如果你正在与一个远程朋友聊天,不是通过冰冷的屏幕文字,也不是缺乏表情的虚拟形象,而是一个逼真、动态、充满表情的数字化虚拟人。这个虚拟人不仅能够完美地复现你朋友的微笑、眼神,甚至是细微的肢体动作。你会不会感到更加的亲切和温暖呢?真是体现了那一句「我会顺着网线爬过来找你的」。这不是科幻想象,而是在实际
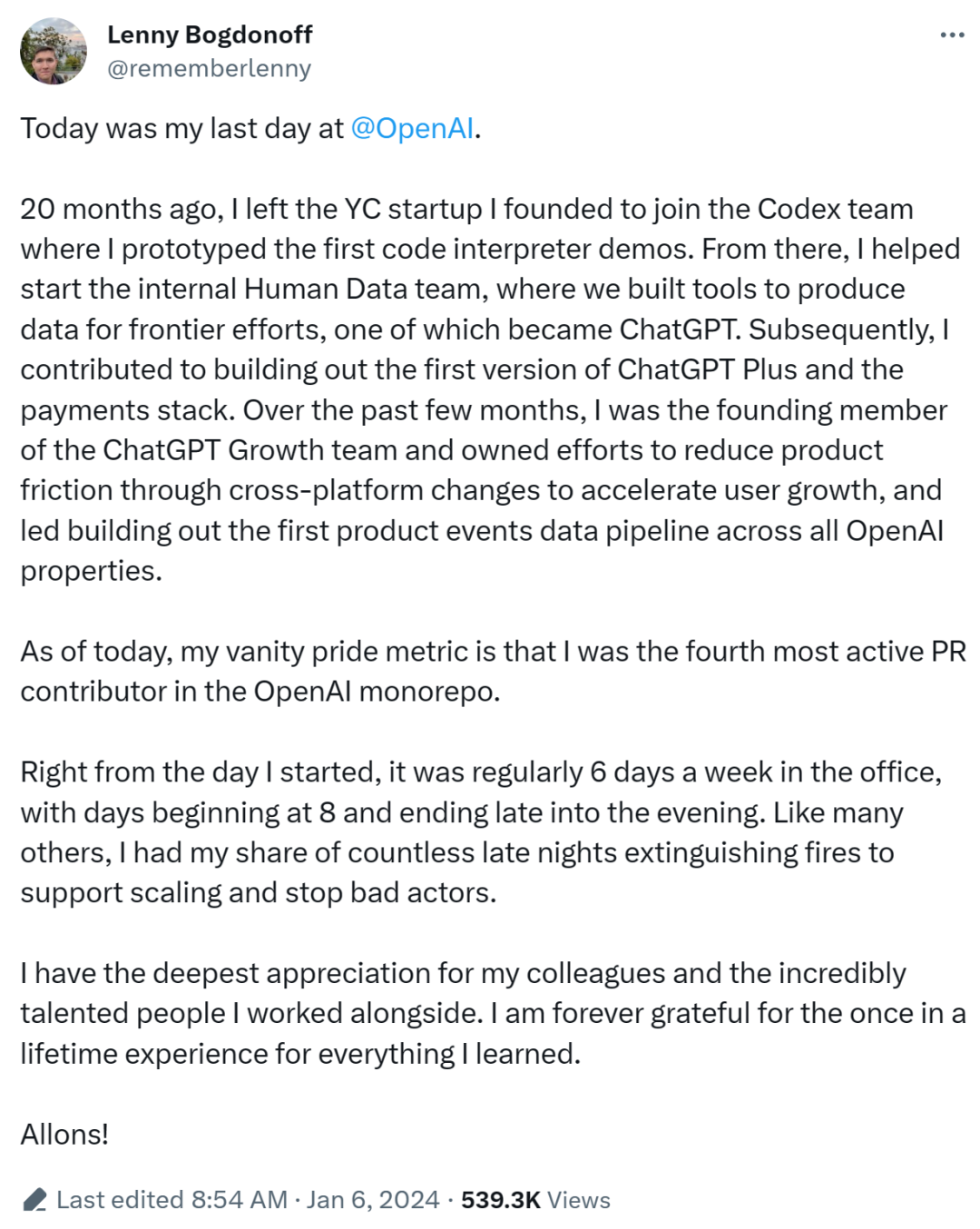
OpenAI也在996?一位离职员工自白:代码贡献第四,经常工作6天
从这位离职员工的经历来看,OpenAI 似乎比「996」还要严重一点。AI 圈的人大概都知道,OpenAI 是其中的佼佼者,技术牛、薪酬高,但很大可能工作量也大。今天,推特上一位 OpenAI 员工的离职自白获得了非常高的关注和浏览量,一定程度上让我们看到了在 OpenAI 工作的状态。来源 Lenny Bogdonoff,他在 2022 年 6 月加入 OpenAI,主要从事 AI 产品及体验相关的工作。他在自白中描述了自己的工作内容、工作时长以及对 OpenAI 的贡献。20 个月前,我离开了参与创立的公司

Midjourney文本渲染新升级,与DALL·E 3大比拼,看看谁更强
文字渲染哪家强,今天你来做裁判。如果文生图中也有「敬业」代表,那 Midjourney 绝对能够提名。从发布开始,每次更新都给我们不一样的惊艳。这不,Midjourney 现在升级到了 v6 alpha 版本,生成品质有了进一步的提升。画面美观性、连贯性、与 prompt 的一致性、图像质量以及文本渲染都有着很大的进步。此外,在风格化上 Midjourney 也有了更好的表现,图像放大修复的速度也快了两倍。有网友闻风而来,被 Midjourney 本次更新的文字渲染的能力所吸引,Midjourney 也就此回应,即

专为数据库打造:DB-GPT用私有化LLM技术定义数据库下一代交互方式
DB-GPT 简化了这些基于大型语言模型 (LLM) 和数据库的应用程序的创建。2023 年 6 月,蚂蚁集团发起了数据库领域的大模型框架 DB-GPT。DB-GPT 通过融合先进的大模型和数据库技术,能够系统化打造企业级智能知识库、自动生成商业智能(BI)报告分析系统(GBI),以及处理日常数据和报表生成等多元化应用场景。DB-GPT 开源项目发起人陈发强表示,“凭借大模型和数据库的有机结合,企业及开发者可以用更精简的代码来打造定制化的应用。我们期望 DB-GPT 能够构建大模型领域的基础设施,让围绕数据库构建大

看见这张图没有,你就照着画:谷歌图像生成AI掌握多模态指令
用图 2 的风格画图 1 的猫猫并给它戴上一顶帽子。谷歌新设计的一种图像生成模型已经能做到这一点了!通过引入指令微调技术,多模态大模型可以根据文本指令描述的目标和多张参考图像准确生成新图像,效果堪比 PS 大神抓着你的手助你 P 图。在使用大型语言模型(LLM)时,我们都已经见证过了指令微调的重要性。如果应用得当,通过指令微调,我们能让 LLM 帮助我们完成各种不同的任务,让其变成诗人、程序员、剧作家、科研助理甚至投资经理。现在,大模型已经进入了多模态时代,指令微调是否依然有效呢?比如我们能否通过多模态指令微调控制

无需文本标注,TF-T2V把AI量产视频的成本打下来了!华科阿里等联合打造
在过去短短两年内,随着诸如 LAION-5B 等大规模图文数据集的开放,Stable Diffusion、DALL-E 2、ControlNet、Composer ,效果惊人的图片生成方法层出不穷。图片生成领域可谓狂飙突进。然而,与图片生成相比,视频生成仍存在巨大挑战。首先,视频生成需要处理更高维度的数据,考虑额外时间维度带来的时序建模问题,因此需要更多的视频 - 文本对数据来驱动时序动态的学习。然而,对视频进行准确的时序标注非常昂贵。这限制了视频 - 文本数据集的规模,如现有 WebVid10M 视频数据集包含

文生视频“黑马”Morph Studio来袭:好用、1080P 、7秒时长还免费
“发光的水母从海洋中慢慢升起,”在 Morph Studio 中继续输入想看到的景象,“在夜空中变成闪闪发光的星座”。 几分钟后,Morph Studio 生成一个短视频。一只水母通体透明,闪闪发光,一边旋转着一边上升,摇曳的身姿与夜空繁星相映成趣luminescent jellyfish ascend from a mystical ocean, transforming into sparkling constellations in the night sky输入“ joker cinematic ”,曾经
AI大模型首次牵手国民级综艺,昆仑万维天工AI联合《最强大脑》加速大模型落地
1月5日周五晚21:20,由昆仑万维「天工APP」特约赞助的《最强大脑》第11季正式播出。这是AI大模型技术与国民级综艺IP的首度深度合作,在节目中,「天工APP」将发挥其能搜、能聊、能写的多项超级AI大模型能力,与嘉宾选手深度互动,参与趣味脑力竞技环节,从而进一步推动大模型技术的普适应用,降低技术门槛,让越来越多的用户能够轻松、便捷地拥抱大模型。作为一档国内影响力最广、最具代表性的国民级的大型科学竞技综艺节目,《最强大脑》在过去十年间已成功举办了10期,在372个挑战项目中,近600位中外选手齐聚舞台,参与脑力竞

斯坦福开源的机器人厨子,今天又接手了所有家务
机器人忙碌的一天。这年头,机器人真的要成精了,带回家后是个做家务的小能手。烹饪几道美食手到拈来,一会儿功夫速成大餐:滑蛋虾仁、蚝油生菜、干贝烧鸡,不知道的还以为是真人厨师做成的:备菜环节也是做的有模有样,只见它熟练的拿出一颗生菜切掉根部,然后轻轻的敲打鸡蛋放入碗中:打蛋环节还知道要把蛋壳丢到一边,看样子是个讲究的机器人,再也不怕吃煎蛋时意外吃到蛋壳的惊吓了:煎炒环节机器人进行不停地翻炒,以免糊锅:还不忘给蚝油生菜注入灵魂蒜末。这次咱不用菜刀拍蒜,普通的水果刀也能切出蒜泥来,可见刀功了得:最后将做好的酱汁淋到生菜上,
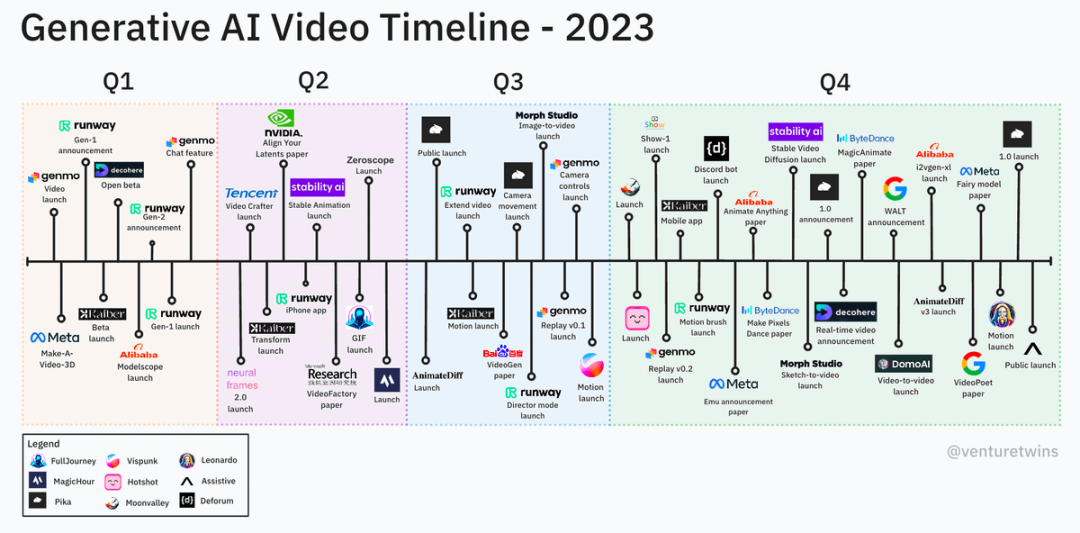
国内视频生成爆发前夕,我们组织了一场核心玩家都参与的分享交流会
近几个月来,视频生成领域陆续发布了新技术、新模型和新工具,AI 生成的视频效果也得到了肉眼可见的提升和颠覆。很多人认为,人工智能领域接下来公认的主战场,毋庸置疑是视频生成技术。图 1:2023 年 AI 视频工具概览 图片来源: Pika 1.0 全面开放、Runway 发布的 Gen-2 开始商业化探索、Meta、Moonvalley 和 Stability AI 等公司陆续发布了 AI 视频工具等,视频生成在整个 AI 领域掀起了讨论热潮。与此同时,当我们把视线聚焦在国内的 AI 视频生成领域上,同样也看到了
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉