应用

画个框、输入文字,面包即刻出现:AI开始在3D场景「无中生有」了
现在,通过文本提示和一个 2D 边界框,我们就能在 3D 场景中生成对象。看到下面这张图了没?一开始,盘子里是没有东西的,但当你在托盘上画个框,然后在文本框中输入文本「在托盘上添加意大利面包」,魔法就出现了:一个看起来美味可口的面包就出现在你的眼前。房间的地板上看起来太空荡了,想加个凳子,只需在你中意的地方框一下,然后输入文本「在地板上添加一个矮凳」,一张凳子就出现了:相同的操作方式,在圆桌上添加一个茶杯:玩具旁边摆放一只手提包统统都可以:我们可以从以上示例看出,新生成的目标可以插在场景中的任意位置,还能很好地与原

纪念碑谷式错觉图像都被「看穿」,港大、TikTok的Depth Anything火了
人类有两只眼睛来估计视觉环境的深度信息,但机器人和 VR 头社等设备却往往没有这样的「配置」,往往只能靠单个摄像头或单张图像来估计深度。这个任务也被称为单目深度估计(MDE)。近日,一种可有效利用大规模无标注图像的新 MDE 模型 Depth Anything 凭借强大的性能在社交网络上引起了广泛讨论,试用者无不称奇。甚至有试用者发现它还能正确处理埃舍尔(M.C.Escher)那充满错觉的绘画艺术(启发了《纪念碑谷》等游戏和艺术):从水上到水下,丝滑切换:更好的深度模型也得到了效果更好的以深度为条件的 Contr

MoE与Mamba强强联合,将状态空间模型扩展到数百亿参数
性能与 Mamba 一样,但所需训练步骤数却少 2.2 倍。状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transformer 架构的一大有力替代架构。近期也有一些研究者在探索将 SSM 和 Mamba 与其它方法组合起来创造更强大的架构,比如机器之心曾报告过《Mamba 可以替代 Transformer,但它们也能组合起来使

有了这块活地板,成为VR届的「街溜子」
给 VR 系统加了新维度。还记得电视剧《三体》里面汪淼他们用来打游戏的 V 装具吗?和最近苹果发布的 Vision Pro 相比,这套近未来的虚拟现实(VR)设备还多了感应服和「跑步机」等一些组件。很明显的是,除非脑后插管,只有进行从头到脚、所有感官全覆盖,你才能在 VR 设备里充分感受模拟世界的乐趣。然而在可预见的未来,所有此类解决方案都将存在一些不可忽视的缺点。价格是最大的挑战,单买一个 Apple Vision Pro 就要花费 2.5 万人民币,其他可以预见的问题还包括占地面积和噪音。不过在此之前,我们得先

ICLR2024 | Harvard FairSeg: 第一个研究分割算法公平性的大型医疗分割数据集
作者 | 田宇编辑 | 白菜叶近年来,人工智能模型的公平性问题受到了越来越多的关注,尤其是在医学领域,因为医学模型的公平性对人们的健康和生命至关重要。高质量的医学公平性数据集对促进公平学习研究非常必要。现有的医学公平性数据集都是针对分类任务的,而没有可用于医学分割的公平性数据集,但是医学分割与分类一样都是非常重要的医学 AI 任务,在某些场景分割甚至优于分类,因为它能够提供待临床医生评估的器官异常的详细空间信息。在最新的研究中,哈佛大学(Harvard University)的Harvard-Ophthalmolo

和特斯拉竞速、能站立、会开门...... 明星四足轮腿机器人要商业化了
机器之能报道编辑:吴昕大部分轮腿结合的机器人仍然只活跃在研究领域,目前也只有少数轮腿机器人平台,能够进入商业化阶段的更是凤毛麟角。提到四足机器人,很多人首先想到的是波士顿动力的 Spot 机器人狗。实际上,基于苏黎世联邦理工学院机器人系统实验室( Robotic Systems Lab,RSL )技术的四足机器人一直不输于波士顿动力。比如,已经商业化的 ANYmal 四足机器人。已经商业化的ANYmal 四足机器人正在某工厂执行自主检查任务。该机器人已经部署到了马来西亚国家石油公司、壳牌石油、西门子能源、巴斯夫等公

2023京东零售技术年度盘点
过去一年,围绕开放生态建设、低价心智等主要方向,京东零售技术团队持续攻坚。从百亿补贴、调整流量分配机制为用户提供低价品质好货,到简化商家进驻流程、优化商家体验,带动商家数量增长和平台生态活跃,再到将大模型结合到内部大量业务场景,探索效率提升……快速响应、助力业务的同时,京东零售技术团队继续夯实增强自身能力、探索创新。我们选取了11项有代表性的技术成果,与大家分享。供应链创新技术入围行业最高奖项 京东长期致力于通过前沿的数智化技术和算法,提高供应链效率。2023年,智能供应链团队提出并应用了端到端库存管理技术和可解释

SD WebUI 中也能用上实时绘画了!支持接入PS/Blender 等设计工具
大家好,这里是和你们一起探索 AI 绘画的花生~
之前为大家介绍过 AI 绘画工具 Krea,它可以根据手绘的草图实时生成完整的画面,可以让我们更精准地控制图像效果,对电商、产品、游戏概念等设计领域来说非常有帮助。之前为大家推荐过一种在 ComfyUI 中免费实现 AI 实时绘画的方式,今天就再为大家推荐另一种在 Stable Diffusion WebUI 中实现实时绘画的方法。一、插件简介
SD WebUI 的实时绘画功能需要借助一个插件实现,这个插件是上周由 B 站 AI 绘画博主@朱尼酱推出,支持文生图、图

IP-Adapter!让AI绘画垫图效率提高10倍的新一代神器
都是“垫图”,谁能还原你心中的图
“垫图”这个概念大家肯定都不陌生,此前当无法准确用 prompt 描述心中那副图时,最简单的办法就是找一张近似的,然后 img2img 流程启动,一切搞定。
更多垫图干货:可 img2img 简单的同时,也有它绕不过去的局限性,比如对 prompt 的还原度不足、生成画面多样性弱,特别是当需要加入 controlnet 来进行多层控制时,参考图、模型、controlnet 的搭配就需要精心挑选,不然出图效果常常让人当场裂开…
但现在,我们有了新的“垫图”神器——IP-Adapter

可实现稳定且大的信号响应变化,吉林大学团队开发了一种差分钙钛矿半球形光电探测器
编辑 | 萝卜皮具有智能功能的先进光电探测器,有望在未来技术中发挥重要作用。然而,在有限数量的像素内完成复杂的检测任务仍然具有挑战性。吉林大学的研究团队报告了一种差分钙钛矿半球形光电探测器,用作智能成像和位置跟踪的智能定位器。钙钛矿半球形光电探测器具有高外量子效率(~1000%)和低噪声(10^−13 A Hz^−0.5),可实现稳定且大的信号响应变化。通过计算机算法分析仅 8 个像素的差分光响应,可以在低成本、无透镜的设备几何结构中实现彩色成像的能力和 4.7 nm 的计算光谱分辨率。通过机器学习模拟不同施加偏置
优于SOTA方法,语言模型结合几何深度学习技术,望石智慧开发3D分子生成模型Lingo3DMol
编辑 | X分子生成是 AI 助力小分子新药研发的核心技术。望石智慧始终专注于分子生成技术的开发。就在前几天,望石智慧的研究团队推出了 Lingo3DMol,用于在给定口袋 3D 结构的情况下生成小分子配体的 3D 结构。方法结合了语言模型和几何深度学习技术。研究人员在传统的 SMILES 分子表征的基础上,开发了新的分子表示方法 FSMILES。此外,研究训练了一个单独的非共价相互作用预测器,为生成模型提供必要的结合模式信息。Lingo3DMol 可以有效地穿越类似药物的化学空间,防止异常结构的形成。Lingo
罗氏制药和GRCEH团队开发可解释机器学习方法,用于分析治疗性抗体的免疫突触和功能表征
编辑 | 萝卜皮治疗性抗体广泛用于治疗严重疾病。它们中的大多数会改变免疫细胞并在免疫突触内发挥作用。指导体液免疫反应的重要细胞间相互作用。尽管生成并评估了许多抗体设计,但缺乏用于系统抗体表征和功能预测的高通量工具。德国环境健康研究中心(German Research Center for Environmental Health)和罗氏制药(Roche)的研究团队,开发了一个全面的开源框架 scifAI(单细胞成像流式细胞术 AI),用于对成像流式细胞术 (IFC) 数据进行预处理、特征工程和可解释的预测机器学习。
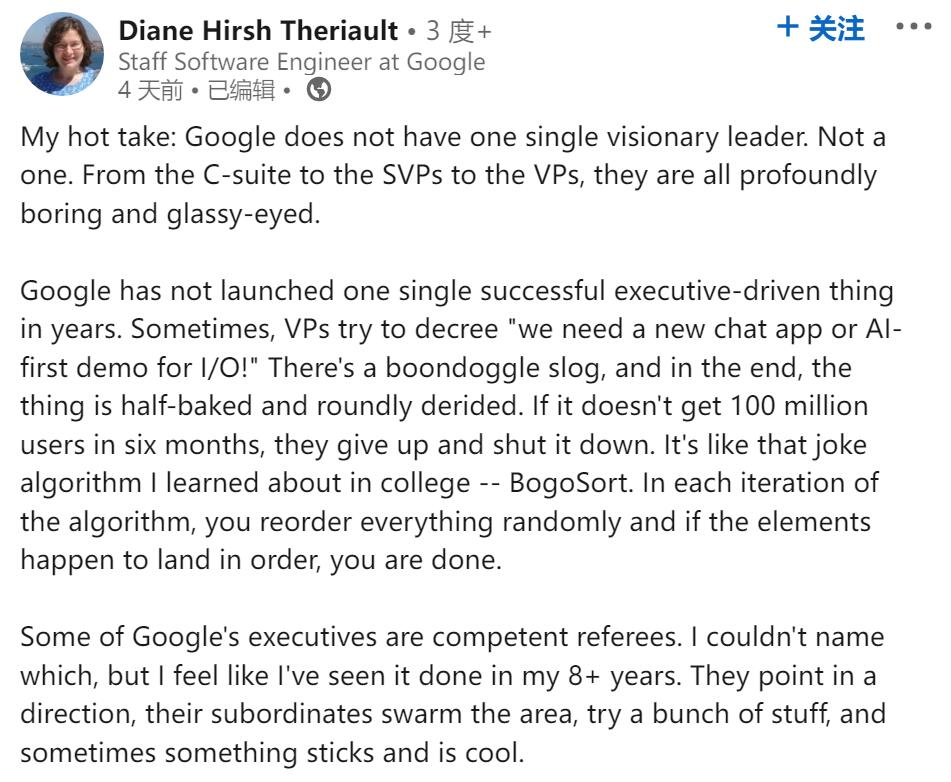
裁员靠随机?谷歌资深工程师爆大料,员工准备抗议示威
随着谷歌又一轮「裁员广进」,员工开始了对高管的炮轰。「谷歌现在没有半个有远见的领导者,从最高管理层、高级副总裁再到副总裁,他们都得过且过、目光呆滞。」最近几天,谷歌资深软件工程师 Diane Hirsh Theriault 的长篇帖子在社交网络上引起了轰动。在去年底,Theriault 带领的团队被裁员了 3/4。在领英上的一篇推文中,Theriault 对谷歌目前的管理方式和发展方向感到深深的担忧,同时也对大量员工被「随机」裁员表达了愤怒。她的文章获得了大量谷歌同事的共鸣。最近,谷歌的新一轮裁员引发了争议,这加剧
李飞飞、吴恩达开年对话:AI 寒冬、2024新突破、智能体、企业AI
李飞飞、吴恩达畅谈 2024 AI 趋势。在人工智能发展史上,2023 已经成为非常值得纪念的一年。在这一年,OpenAI 引领的 AI 大模型浪潮席卷了整个科技领域,把实用的 AI 工具送到了每个人手里。但与此同时,人工智能的发展也引起了广泛的讨论和争议,尤其在其商业应用和未来发展前景方面。著名 AI 专家 Rodney Brooks 在 2024 年初发文预言,认为 AI 可能即将进入一个新的寒冬,随着泡沫的破裂,行业可能面临严峻的挑战。他的这一言论引发了业界的广泛讨论:新的一年,AI 领域将会迎来更多的炒作,

高通CEO安蒙:生成式AI将变革用户与终端交互的方式
尽管2024年才刚刚开始,但不论是从刚刚结束的CES上无处不在的生成式AI创新,还是从各大智能手机厂商最新旗舰发布会中频频提到的“大模型”来看——生成式AI正在加快脚步,真正走进人们的生活。近期,高通公司总裁兼CEO安蒙在多个采访中也展望了生成式AI在2024年的发展方向,他指出生成式AI走向终端,将变革用户与终端交互的方式。生成式AI走向终端,进入下一发展阶段在终端侧,高通已经能够打造高性能AI处理器,使得仅通过电池供电的移动终端也能随时随地运行生成式AI。同时,生成式AI模型经过训练优化,体量越来越小,效率越来
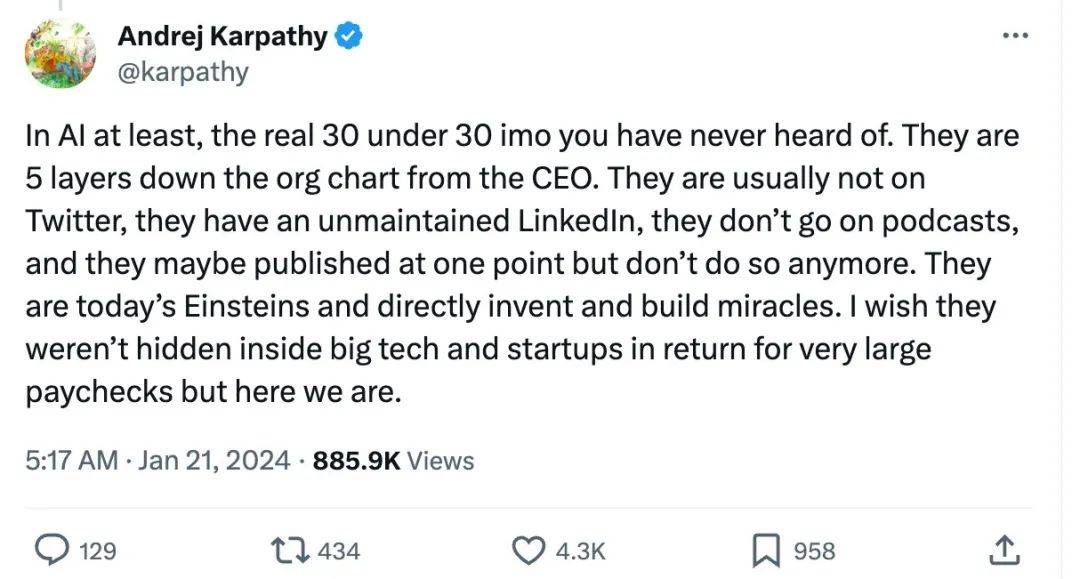
2024年,开源AI潜力更大?
开源社区为人工智能发展做了什么?开源(OS)正在驱动生成式 AI 的创新。得益于像 GitHub 和 Hugging Face 等学术研究平台,我们得以见证 AI 技术的蓬勃发展。但值得注意的是,OpenAI、Anthropic 等越来越多的科技公司选择不公开模型的代码和权重。指责大型科技公司闭源的声音从未停止,昨天,前特斯拉 AI 总监,OpenAI 的创始成员 Andrej Karpathy 发了一条推特暗指「闭源」对人才的限制:在人工智能领域,我认为你数不出来 30 个 30 岁以下的闻名者。在公司结构图里,

视觉Mamba模型的Swin时刻,中国科学院、华为等推出VMamba
Transformer 在大模型领域的地位可谓是难以撼动。不过,这个AI 大模型的主流架构在模型规模的扩展和需要处理的序列变长后,局限性也愈发凸显了。Mamba的出现,正在强力改变着这一切。它优秀的性能立刻引爆了AI圈。上周四, Vision Mamba(Vim)的提出已经展现了它成为视觉基础模型的下一代骨干的巨大潜力。仅隔一天,中国科学院、华为、鹏城实验室的研究人员提出了 VMamba:一种具有全局感受野、线性复杂度的视觉 Mamba 模型。这项工作标志着视觉 Mamba 模型 Swin 时刻的来临。论文标题:V
零一万物Yi-VL多模态大模型开源,MMMU、CMMMU两大权威榜单领先
1 月 22 日,零一万物 Yi 系列模型家族迎来新成员:Yi Vision Language(Yi-VL)多模态语言大模型正式面向全球开源。据悉,Yi-VL 模型基于 Yi 语言模型开发,包括 Yi-VL-34B 和 Yi-VL-6B 两个版本。Yi-VL 模型开源地址:,Yi-VL 模型在英文数据集 MMMU 和中文数据集 CMMMU 上取得了领先成绩,展示了在复杂跨学科任务上的强大实力。MMMU(全名 Massive Multi-discipline Multi-modal Understanding & R
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉