基础
瞄准化学键,大卫·贝克团队提出通用蛋白质架构设计新范式
编辑丨coisini化学键是指分子中相邻原子间的强烈相互作用。 有限的原子种类和键合几何却能产生高度复杂的可设计结构,使大量原子能以精确定义的距离、取向和可预测的相互作用强度排列。 然而,由于蛋白质复杂的序列 - 结构关系,通过相互作用实现可预测键合来构建蛋白质组装体仍具挑战。

Nature丨从基因组到田间,华中农业大学、中国科学院等提出融合生物技术与AI的育种新范式
编辑丨&农业,生民之本。 当金黄的麦浪与稻田在风中起伏,农业研究者的辛劳不知是否会因此而减轻少许。 部分研究者所采用的传统针对作物改良的方式受限于自然与植株本身的潜力,在当下还无法满足粮食安全的需要。

千寻位置免费开放时空智能三体套件,加速具身机器人全域全场景
4月9日,千寻位置正式发布机器人时空智能三体开发套件SpatiX (简称“时空智能三体套件”),助力机器人企业降低研发门槛、提升研发效率。 目前,千寻位置已与多家知名具身智能头部企业合作,共同推进具身智能等未来产业的商业化落地。 即日起,机器人研发、生产或集成应用的企业以及相关科研机构均可通过免费体验活动申请试用,获得专属服务。

从0到1玩转MCP:AI的「万能插头」,代码手把手教你!
在人工智能飞速发展的今天,LLM 的能力令人叹为观止,但其局限性也日益凸显 —— 它们往往被困于训练数据的「孤岛」,无法直接触及实时信息或外部工具。 2024 年 11 月,Anthropic 推出了开源协议 MCP(Model Context Protocol,模型上下文协议),旨在为 AI 模型与外部数据源和工具之间的交互提供一个通用、标准化的连接方式。 MCP 的开源性质也迅速吸引了开发社区的关注,许多人将其视为 AI 生态系统标准化的重要一步。

硅基战队来袭,联想中国誓师大会宣布智能体矩阵已成
联想将再一次以 AI 服务加速中国千行百业、千家万户快速踏入 AI 应用之门。

维他动力种子轮融资2亿元,今年底发布首款消费级机器人产品
明星机器人产品公司——维他动力(Vita Dynamics)近期完成了种子 轮融资,成立三个月内,累计完成2亿元种子轮融资,本轮融资由知名投资机构今日资本、凯辉基金领投,雅瑞资本参与投资,高瓴创投、元璟资本、初心资本、柏睿资本及BV百度风投等多家首轮投资方持续跟投,高鹄资本担任独家财务顾问。 此次融资将进一步加速维他动力为个人和家庭创造生活空间智能伙伴的产品研发与市场拓展。 在技术突破和应用场景的双重驱动下,机器人产业化进程已经迎来重大机遇。

不是CG?没加速?这个国产机器人跳「斧头帮」舞火了,网友:流畅到不像真的
机器之心报道,编辑:张倩、佳琳。
加速精准医疗,开源GNN实现分子精准建模,质谱识别准确率提升至49%
编辑丨&非靶向代谢组学在推进精准医学和生物标志物发现方面前景广阔。 由于谱图参比库的不完整,从串联质谱中鉴定化合物在当前仍是一项颇有挑战的任务。 为了应对这项挑战,德国联邦材料研究与测试研究所(BAM)与柏林自由大学的一支团队提出了 FIORA,这是一种旨在模拟串联质谱的开源图神经网络。

华为昇腾适配阶跃星辰Step-Video和Step-Audio开源大模型,上线魔乐社区
今日,魔乐社区(Modelers)宣布已上架由阶跃星辰自研的 Step-Video 视频生成和 Step-Audio 语音模型两款开源多模态大模型,并基于华为昇腾 CANN 异构计算架构和昇腾服务器,完成了对模型的适配。 开发者和企业用户在魔乐社区中可以直接下载并体验。 Step-Video-T2V 是目前全球参数量最大的开源视频生成模型,达到300亿参数。

OmniParser V2 在 Windows 系统上的详细安装与运行指南
OmniParser V2 在 Windows 系统上的详细安装与运行指南
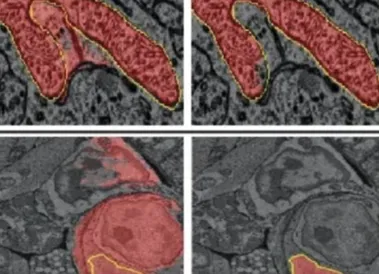
Nature子刊 | 光镜电镜通用,Meta「分割一切」模型用到显微镜图像上了
编辑丨coisini识别显微镜图像中的对象,例如光学显微镜(LM)下的细胞和细胞核是生物学图像分析中的关键任务之一。 由于显微镜成像方式的多样性和不同维度(二维 / 三维,时间维度)的存在,这些识别任务具有挑战性,目前需要采用不同的方法来解决。 基于深度学习的方法在过去几年中显著改善了 LM 下的细胞和细胞核分割,电子显微镜(EM)下的细胞、神经元和细胞器分割。
11天实现18种广谱抗菌素设计,体外验证成功率94.4%,浙大侯廷军等用LLM方法从头设计AMP
编辑 | 萝卜皮大型语言模型 (LLM) 在化学和生物医学研究中取得了显著进展,可作为各种任务的多功能基础模型。 浙江大学侯廷军、谢昌谕以及南方医科大学姜志辉等课题组组成的联合团队提出了 AMP-Designer,这是一种基于 LLM 的方法,用于快速设计具有所需特性的抗菌肽 (AMP)。 在 11 天内,AMP-Designer 实现了 18 种具有广谱抗革兰氏阴性细菌活性的 AMP 的从头设计。

多中心医学图像分析模型,VFMGL框架破解数据孤岛难题,93.4% Dice系数的卓越表现
编辑丨&在众多中下游任务中,收到广泛而多样的数据集训练的基础模型表现出的强大性能,在医疗领域表现却不甚得人心。 受到到数据量、异质性和隐私问题等问题的严重阻碍,基础模型得不到更进一步的发展。 桂林航空航天大学联合江门市中心医院等推出了 Vision Foundation Model General Lightweight(VFMGL)框架,以促进各种医疗任务的专家临床模型的去中心化构建。

DeepSeek关键RL算法GRPO,有人从头跑通了,贡献完整代码
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存? 有人给出了些破解方法》。 简单来说,GRPO 算法丢弃了 critic model,放弃了价值函数近似,转而通过组内样本的相对比较来计算策略梯度,从而有效降低了训练的不稳定性,同时提高了学习效率。

Karpathy更新AI科普视频,网友:原本周末打算结个婚,改看视频了
他是真的想教会大家。 刚刚,赛博活佛 Andrej Karpathy 更新了一个长达 2 个多小时的学习视频,主题是 ——「我是如何使用大型语言模型(LLM)的」。 这个视频是 Karpathy 面向普通观众的系列视频之一。

DeepSeek FlashMLA:大模型推理的“涡轮增压器”
FlashMLA(Flash Multi-head Latent Attention)是DeepSeek针对英伟达Hopper架构GPU(如H800/H100)设计的高效解码内核,其核心技术围绕多头潜在注意力(MLA)机制展开,通过软硬件协同优化实现性能突破

清华团队新算法玩转频域时域,压缩95%计算量实现语音分离新SOTA!
AIxiv专栏是AI在线发布学术、技术内容的栏目。 过去数年,AI在线AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。 如果您有优秀的工作想要分享,欢迎投稿或者联系报道。

字节最新OmniHuman数字人模型即将上线即梦
近期,即梦AI在官方社交媒体上发布了一条新功能上线预告片。 视频显示,采用了全新的多模态视频生成模型OmniHuman,用户仅需输入一张图片和一段音频,就可以生成一条生动的AI视频,有望大幅提升AI短片的制作效率和质量。 图片来自即梦AI视频号内容截图OmniHuman技术主页信息显示,该模型为字节跳动自研的闭源模型,可支持肖像、半身以及全身等不同尺寸的图片输入,并根据输入的音频,在视频中让人物生成与之匹配的动作,包括演讲、唱歌、乐器演奏以及移动。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉