
随着扩散模型(Diffusion Models)的迭代演进,图像生成已经日臻成熟。然而,在 多实例图像生成(Multi-Instance Image Generation, MIG) 这一有着大量用户场景的关键领域,现有的方法仍面临核心瓶颈:如何同时实现对多个对象的空间布局控制(Layout Control)以及身份特征的良好保持(Identity Preservation)。
主流方法往往无法做到两全其美:依赖文本和布局引导(Layout-to-Image)的模型往往难以实现高度的实例定制化,且实例遗漏、属性泄露的问题时有发生;而主流的主体驱动(Subject-driven)方法在主体数量增加时,面临着严重的身份混淆和细节丢失的问题。

ContextGen 与主流 SOTA 的对比示例,以及 ContextGen 的使用例
为解决这一制约高度定制化图像生成的难题,浙江大学 ReLER 团队发布 ContextGen,一个新型的基于 Diffusion Transformer (DiT) 的框架,旨在通过上下文学习,可靠地完成图像引导的多实例生成任务!

论文地址:https://arxiv.org/abs/2510.11000
项目地址:https://nenhang.github.io/ContextGen
开源代码:https://github.com/nenhang/ContextGen
开源模型:https://huggingface.co/ruihangxu/ContextGen
ContextGen 提出了全新的上下文生成范式,通过整合布局图像和多张参考图像,将布局控制与身份保持的挑战转化为统一的上下文建模问题。
双核驱动:实现布局与身份的双重保真
ContextGen 的双重核心机制,共同作用于统一的上下文 Token 序列上:
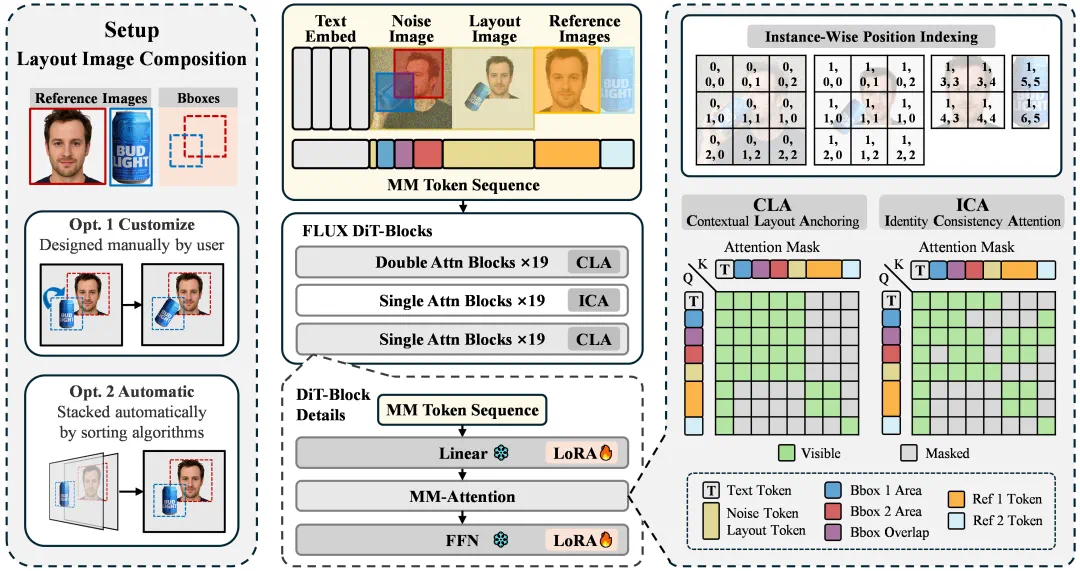
ContextGen 框架结构概览
上下文布局锚定(Contextual Layout Anchoring, CLA)
CLA 机制聚焦于全局上下文的引导,接受用户设计(或者模型自动拼合)的布局图像作为输入,以提供精确的全局布局控制和初步的身份信息。它通过在 DiT 模块的前置层和后置层部署自注意力机制,确保文本、待生成图像和布局图像三者进行充分注意力交互,对整体图像结构进行有效控制。
身份一致性注意力(Identity Consistency Attention, ICA)
ICA 机制聚焦细粒度的身份注入,利用原始高保真度的参考图像,将身份信息注入到其对应的目标位置,从而保障多个实例的身份一致性。它被部署到 DiT 模块的中间层,通过一个隔离式的注意力掩码,将参考图像的 Token 与对应待去噪区域的 Token 建立连接,旨在缓解重叠或者压缩导致的细节丢失问题,并在图像序列增长时保证身份信息的稳定注入。
这种的层次化的双重注意力策略,有效地让框架兼具了宏观的布局控制和精细的实例级身份保持。此外,ContextGen 还采用了增强的位置索引策略,系统性地区分和组织统一 Token 序列中多图像之间的关系。
数据基石:大规模详细标注的多实例数据集
针对当前领域高质量训练数据稀缺的现状,团队同时推出了 IMIG-100K 数据集。这是首个为图像引导的多实例生成任务设计的大规模、具备不同难度层级、提供详细布局和身份标注的合成数据集,其构建流程代码也已经开源,支持用户根据自身需求生成定制化数据集。

IMIG-100K 数据集概览

IMIG-100K 的布局、身份标注
性能优化:DPO 强化学习解放创造力
团队在训练过程中发现,仅仅使用监督微调容易使得模型过度参考布局图像,导致生成的图像缺乏多样性和灵活性。为此,在监督微调之外,ContextGen 还引入了基于偏好优化(DPO) 的强化学习阶段。该阶段将布局图像作为非偏好输入,鼓励模型不僵硬复制布局内容,生成更具创意和多样性的图像。
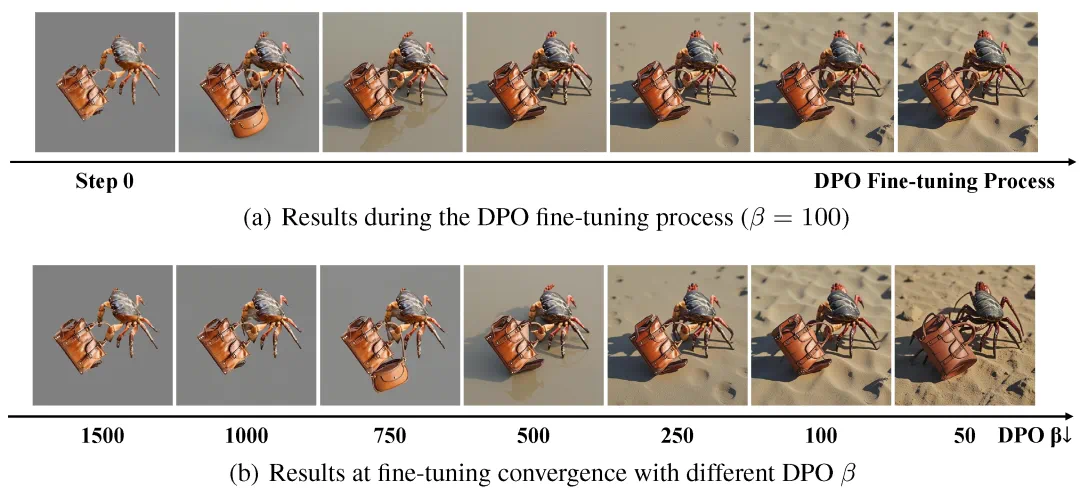
DPO 微调过程示例
实验验证:对标闭源模型,树立性能标杆
在广泛的定量和定性评估中,ContextGen 展现出卓越的 SOTA 性能。
身份保持:比肩闭源巨头
在 LAMICBench++ 基准测试中,ContextGen 不仅超越了所有开源模型(平均得分提升 +1.3%),更在身份一致性上比肩了一些闭源的商业巨头,在多实例的复杂场景中,ContextGen 在人物身份保持 (IDS) 和物体特征保持 (IPS) 上甚至可以和 GPT-4o 和 Nano Banana 一较高下。
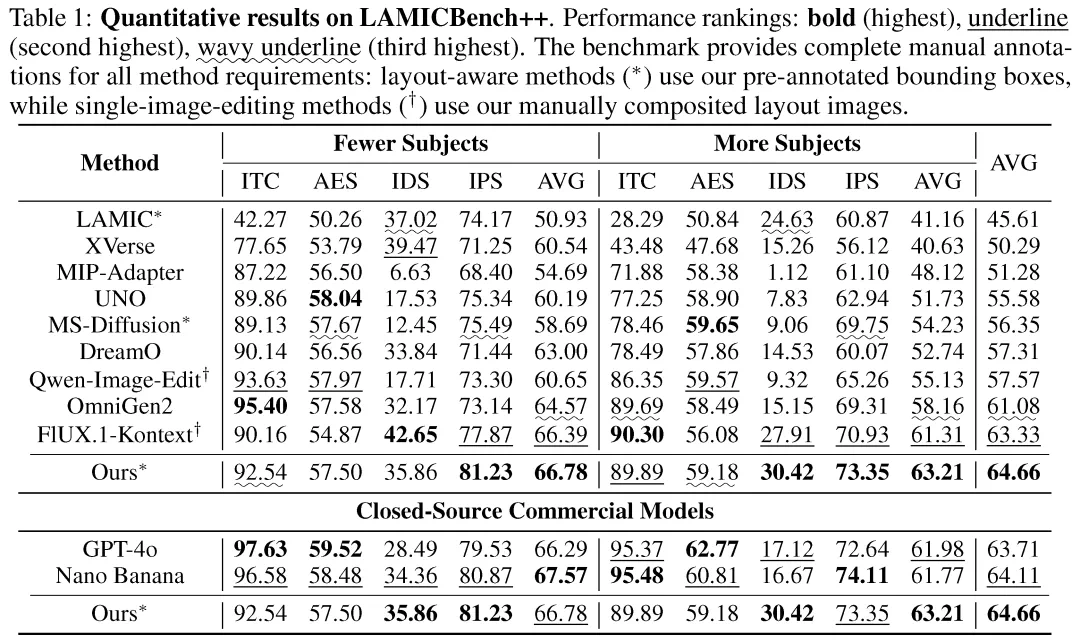
LAMICBench++ 基准的定量对比
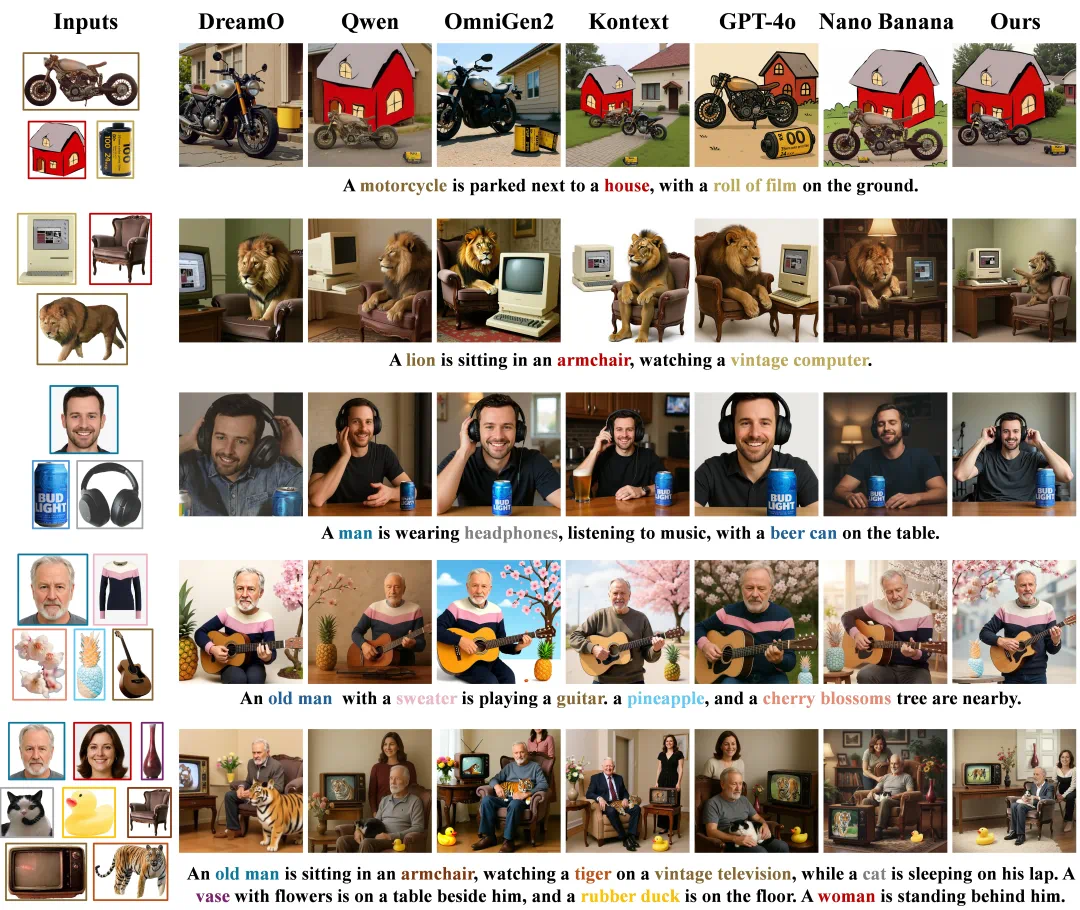
LAMICBench++ 基准的定性对比1

LAMICBench++ 基准的定性对比2
布局与属性控制:准确率大幅提升
在 COCO-MIG 上,ContextGen 在实例级成功率 (I-SR) 上提升 +3.3%,空间准确性 (mIoU) 提升 +5.9%。 在 LayoutSAM-Eval 中,ContextGen 在颜色、材质等属性的正确率上也超过了现有的模型。
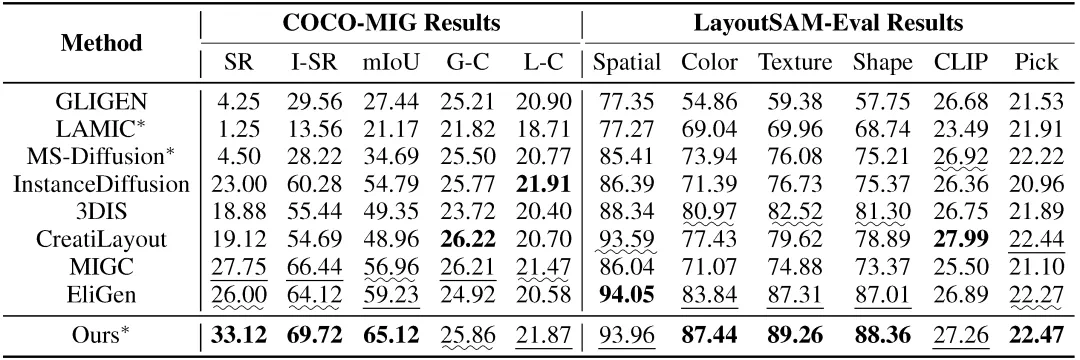
COCO-MIG 和 LayoutSAM-Eval 基准的定量比较

COCO-MIG 基准的定性比较

LayoutSam-Eval 基准的定性比较
这些结果充分证明了 ContextGen 在多实例图像生成任务中的强大能力,成功实现了对布局和身份的双重精确控制。
前端支持:便捷的用户交互
为了方便用户体验,在项目中团队增加了一个简单易用的前端界面,支持用户上传参考图像、以文本的形式添加新素材、通过拖拽方便地设计布局,生成多实例图像。
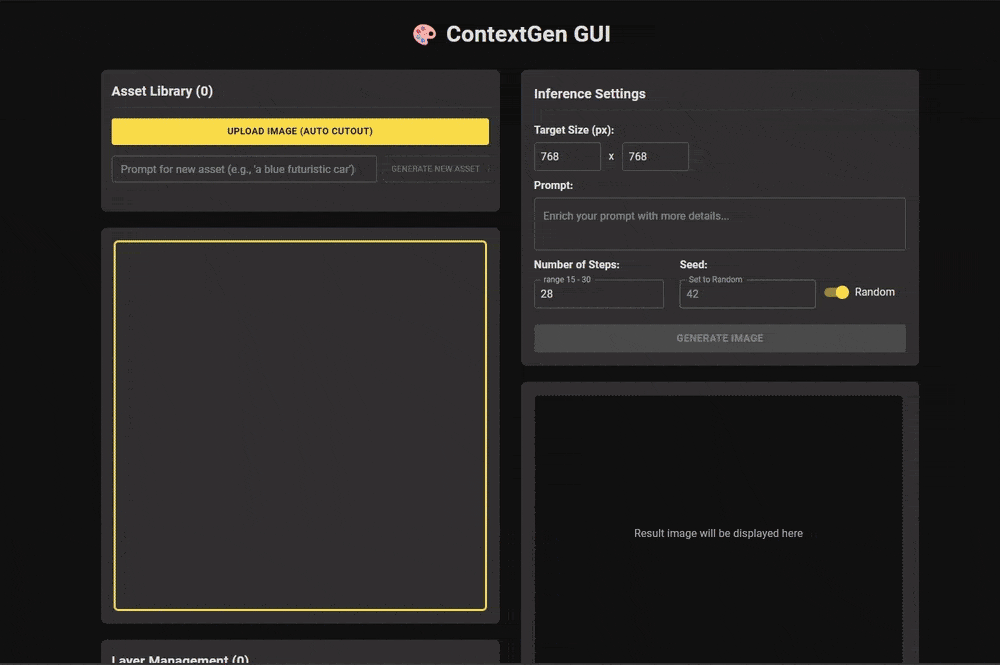
ContextGen 前端交互界面
展望与未来
ContextGen 通过带有双重注意力的上下文机制,为高度可控的多实例生成提供了一个强大且可行的 DiT 框架。ReLER 团队进一步提出,如何更智能地理解用户的文本意图与多模态参考,仍然是一个值得深入探索的课题。未来,团队计划进一步优化模型架构,提升生成效率,并探索更多样化的用户交互方式,以满足更广泛的应用需求。


