作者 | Ben Dickson
编译 | 沈建苗
出品 | 51CTO技术栈(微信号:blog51cto)
近日,麻省理工学院(MIT)的研究人员已开发出一种名为自适应语言模型(SEAL)的框架,使大语言模型(LLM)能够通过更新自身的内部参数来持续学习和适应。SEAL可以教LLM生成自己的训练数据并更新指令,让LLM能够永久吸收新知识并学习新任务。
这种框架特别适用于企业应用环境,尤其适用于在动态环境中运行的AI智能体,它们必须不断处理新信息并调整其行为。
1.LLM的适应性挑战
虽然LLM已具备了卓越能力,但让它们适应特定任务、整合新信息或掌握新颖的推理技能仍然面临一大障碍。
目前面对新任务时,LLM通常通过微调或上下文学习等方法从原始数据中学习。然而,所提供的数据其格式并不总是最适合模型高效学习。现有方法无法让模型自主开发策略,以实现最佳的新信息转换和学习。
MIT博士生、论文共同作者Jyo Pari向IT媒体VentureBeat表示:“许多企业应用场景需要的不仅仅是事实回忆,而是更深层、持久的适应能力。比如说,编程助手可能需要内化(消化并吸收)一家公司的特定软件框架,或者面向客户的模型需要逐渐学习用户的独特行为或偏好。”
在这类情况下,临时检索远远不够,知识需要“融入”到模型的权重中,以便影响未来的所有响应。
2.创建自适应语言模型
MIT研究人员在论文中表示:“为了实现语言模型的可扩展高效适应,我们提议为LLM赋予生成自己的训练数据和微调指令以使用这类数据的能力。”
 图1. SEAL框架示意图图片来源:arXiv
图1. SEAL框架示意图图片来源:arXiv
研究人员提出的解决方案是SEAL,即自适应语言模型。它使用强化学习(RL)算法来训练LLM生成“自编辑”(self-edits),这是指定模型应如何更新自身权重的自然语言指令。这些自编辑可以重构新信息、创建合成训练样例,甚至定义学习过程本身的技术参数。
简单地说,SEAL可以教模型如何自行创建个性化的学习指南。模型不是仅仅阅读新文档(原始数据),而是学会将该信息重写和重新格式化为更容易吸收和内化的形式。这个过程结合了AI研究的几个关键领域,包括合成数据生成、强化学习和测试时训练(TTT)。
该框架采用双循环系统。在“内循环”(inner loop)中,模型使用自编辑对权重进行小幅临时更新。在“外循环”(out loop)中,系统评估该更新是否改善了模型处理目标任务的性能。如果确实有改善,模型获得正向奖励,强化在将来生成这种有效自编辑的能力。LLM逐渐成为自我教学方面的专家。
研究人员在研究中为整个SEAL框架使用了单一模型,然而他们也特别指出,这个过程可以分解为“教师-学生”模型。专门的教师模型经过训练后,可以为单独的学生模型生成有效的自编辑,然后更新该学生模型。这种方法可以在企业环境中实现更专业而高效的适应流程。
3.SEAL的实际应用
研究人员在两个关键领域测试了SEAL:知识整合(永久整合新事实的能力)和小样本学习(从少量样例中泛化的能力)。
 图2. 用于知识整合的SEAL 图片来源:arXiv
图2. 用于知识整合的SEAL 图片来源:arXiv
在知识整合方面,目的是测试模型是否能在问答期间无法访问文本段落的情况下回答段落的相关问题。针对原始文本微调Llama-3.2-1B仅比基础模型略有改善。
然而,当SEAL模型通过从段落中生成多个“推论”来创建“自编辑”,并使用该合成数据进行训练后,准确率跃升至47%。值得注意的是,其效果胜过使用庞大得多的GPT-4.1所生成的合成数据,表明模型学会了为自己创建优质的训练材料。
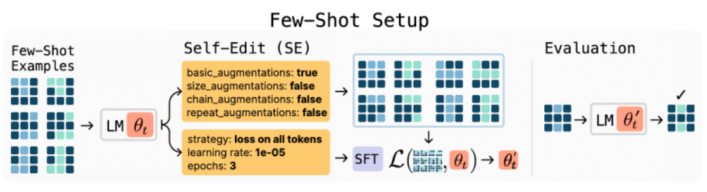 图3. 用于小样本学习的SEAL 图片来源:arXiv
图3. 用于小样本学习的SEAL 图片来源:arXiv
在小样本学习方面,研究人员针对来自抽象推理语料库(ARC)的样例测试了SEAL,模型必须解决视觉谜题。在自编辑阶段,模型不得不生成整套的适应策略,包括使用哪些数据增强和工具、运用什么样的学习率。
结果,SEAL达到了72.5%的成功率,比未经RL训练所取得的20%成功率和标准上下文学习的0%成功率有了显著的改进。
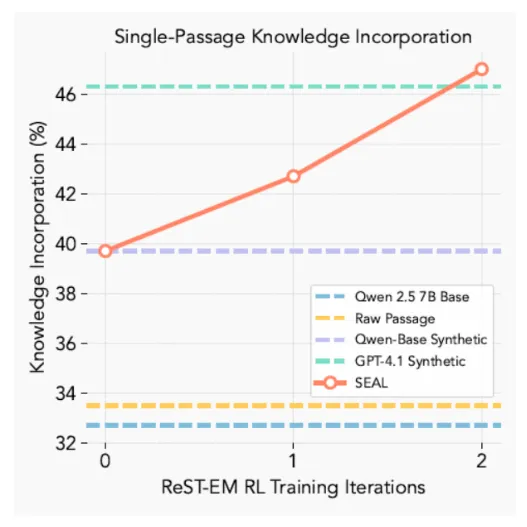 图4. SEAL(红线)在RL训练迭代期间继续改进。 图片来源:arXiv
图4. SEAL(红线)在RL训练迭代期间继续改进。 图片来源:arXiv
4.企业应用价值
一些专家预测,人工生成的高质量训练数据可能在未来几年会断供。正如研究人员所言,进步可能很快取决于“模型自行生成高效用训练信号的能力”。研究人员补充道,自然的下一步是元训练专门的SEAL合成数据生成器模型,从而生成新颖的预训练语料库,使未来模型能够扩展,并在不依赖额外人类文本的情况下实现更高的数据效率。
比如说,研究人员提议,LLM可以摄取学术论文或财务报告等复杂文档,并自主生成数千个解释和推论以加深理解。
研究人员解释,这种自我表达和自我完善的迭代循环可以让模型在甚至缺乏额外外部监督的情况下,不断地改进罕见或代表性不足的主题。
这一能力对构建AI智能体特别大有前景。智能体系统在与环境交互时必须增量获取和保留知识。SEAL为此提供了机制。交互后,智能体可以合成自编辑以触发权重更新,使其能够内化学到的经验。这使智能体得以日臻完善,基于经验改善性能,并减少对静态编程或重复人工指导的依赖。
研究人员写道,SEAL表明了LLM在预训练后无需保持静态。通过学习生成自己的合成自编辑数据,并通过轻量级权重更新加以运用,LLM可以自主整合新知识并适应新任务。
5.SEAL的局限性
话虽如此,SEAL并非万能解决方案。比如它可能存在“灾难性遗忘”,即持续的重训练周期可能导致模型学习早期知识。
Pari表示:“我们目前的做法是鼓励采用混合方法。企业应该有选择性地确定哪些知识重要到需要永久整合。”
事实性、不断变化的数据可以通过RAG保留在外部存储区中,而持久性、改变行为的知识更适合通过SEAL进行权重级更新。这种混合记忆策略确保正确的信息持久保存,又避免模型不堪重负或导致不必要的遗忘。
另外值得一提的是,SEAL需要相当长的时间来调优自编辑样例并训练模型,因此在大多数生产环境下持续的实时编辑行不通。
Pari说:“我们设想一种更实用的部署模式,即系统在一段时间内(比如几小时或一天)收集数据,然后在预定的更新间隔内执行针对性的自编辑。这种方法让企业可以控制适应成本,同时仍得益于SEAL内化新知识的能力。”
论文链接:https://arxiv.org/pdf/2506.10943
参考链接:https://venturebeat.com/ai/beyond-static-ai-mits-new-framework-lets-models-teach-themselves/


