在AI技术加速演进与广泛落地的当下,Agent系统作为具备自主感知、推理与执行能力的智能体,正日益成为企业智能化转型的核心驱动。然而,随之而来的系统复杂性、任务自治性以及跨域协同能力,也引发了前所未有的安全挑战与治理难题。为了构建一个既高效运行又可控可信的Agent系统,亟需在架构层面引入系统性的安全防护与治理机制。本文基于调研,围绕AI Agent系统的安全能力与防护方法展开,提出“预测-防御-检测-响应-审计”的立体化防护体系,旨在为AI Agent的安全可信演进提供可落地的路径与框架支撑。
一、AI Agent应用系统的安全能力及代表性厂商
为匹配AI Agent系统的安全需求,头部安全厂商正加速布局相关能力与产品体系,积极探索适配大模型与智能体架构的新型安全方案。然而,由于大模型与Agent技术尚处于快速发展阶段,当前在传统安全厂商中,具备深度研究与产品化能力的企业仍属少数。整体市场仍处于从探索验证向体系化建设过渡的初期阶段,相关安全能力体系尚待进一步完善与沉淀。
从调研趋势来看,厂商当前主要聚焦于AIGC(生成式人工智能)安全治理领域,围绕模型行为控制与内容合规管理展开技术创新。典型的安全能力包括:人工智能安全评测、大模型安全网关、安全围栏机制。
人工智能评测
人工智能评测 对大模型与AI Agent系统在输入输出、推理过程、异常行为等方面进行安全性、稳定性和合规性评估,辅助企业实现模型上线前的风险可控。核心目标是验证模型质量、风险水平与业务适配度,为开发、部署、监管和优化提供客观依据。
应用场景:包括,大模型选型、备案合规评估、上线前能力与安全评估、行业AI应用评估、第三方AI安全审计服务、开源模型基准对比等场景。
人工智能评测,尤其是面向生成式人工智能模型的安全性与可信性评估,已成为当前业界关注的核心问题之一。当前,参与该领域建设的主体有安全厂商,也有专注于AI技术研究的专业机构。
部分机构不仅具备自主研发的测评工具,还已开展体系化的安全评估服务,代表性机构包括:绿盟科技、君同未来以及上海人工智能实验室等。这些机构在模型攻击面分析、安全基准测试、提示词风险识别、输出内容合规性评估等方面均已展开实质性探索,推动形成较为初步的行业实践标准。
(一)绿盟科技:大模型安全评估系统AI-SCAN
AI-SCAN主要用于评估AI生成内容的安全性,识别和防范潜在风险内容,包括但不限于虚假信息、恶意言论、隐私泄露、版权侵权等,确保AI生成内容的安全性、合规性和可靠性,避免因内容风险引发的法律纠纷或社会负面影响。
- 满足合规:满足大模型应用产品和服务的监管以及合规性评估要求,如 TC260-003技术标准、大模型备案、算法备案等。
- 风险识别:在整个AI生命周期中测试模型,包括训练、部署、测试等阶段,尽早预防风险,针对性开展防御加固工作。
- 模型选型:针对多个本地模型或者在线模型开展模型横向能力对比分析,输出评估分析报告,辅助客户选型模型。
(二)君同未来:评测验证系统“君合、君检”
君同未来是国内专注于人工智能生态治理的一家初创公司,公司成立于2024年6月,总部位于杭州。通过“君合、君检”(评测验证)与“君控”(防护管控)双系统协同,构成了从评测、监控、到防护的全栈AI可信治理方案。其中“君合”是生成式人工智能评测验证系统,“君检”是决策式AI评测增强系统。用于量化评估大模型在实际业务中的可信度、性能和风险控制能力。交付方式包括产品和服务两种。
(三)上海AI人工智能实验室:开源的大模型评测平台OpenCompass
OpenCompass是上海人工智能实验室开源的大模型评测平台,也称为“司南”。它旨在为大语言模型、多模态模型等各类模型提供一站式评测服务,以纯粹技术及中立视角为产学研界提供客观的大模型能力参考。
该平台将测评方向汇总为知识、语言、理解、推理、考试5大能力维度,整合了超过70个评测数据集,提供超过40万个模型评测问题,及长文本、安全、代码3类大模型特色技术能力评测。OpenCompass平台同时会发布大模型的评分榜,包含大语言模型、多模态模型以及各个垂类领域的模型排名,为用户提供全面、客观、中立的评测参考。
大模型安全网关
大模型安全网关 作为模型调用的中间层,负责对输入提示词与输出内容进行审查、策略管控和风险拦截,防止提示注入、越权访问、违规生成等问题。核心目标是保护模型系统免受外部恶意攻击和违规内容。如,对模型的输入请求和输出响应进行内容安全分析、风险识别和策略管控,防止敏感信息泄露、越权访问、提示注入攻击等问题的发生。
适用场景:适合部署在统一入口/模型API接入前后,适用于恶意流量、合规访问、数据泄露防护等通用安全场景。
安全网关是一组相对静态的安全策略,通常独立于模型本体运行,保障模型调用链路的整体安全与合规性。目前,国内外都有一些代表性厂商在该领域展开布局。
国外大模型安全网关的代表性解决方案提供商,有:Microsoft、Prompt Security。
(一)(美国)Microsoft:Azure AI Content Safety Gateway
Azure AI Content Safety Gateway是微软推出的企业级大模型内容安全防护组件,作为Azure OpenAI Service的重要配套能力,旨在为接入GPT系列模型的企业和开发者提供输入/输出内容的安全分析、合规控制与风险拦截能力。
(二)(美国)Prompt Security:Prompt Security Gateway
Prompt Security是一家美国的安全初创公司,专注于为企业防范与生成式人工智能相关的风险,公司成立于2023年。2024年9月推出了针对 Microsoft 365 Copilot的安全和治理解决方案Prompt Security Gateway,其核心功能包括Prompt攻击检测、模型调用行为分析。交付方式支持SaaS或本地部署。
国内大模型安全网关的代表性解决方案提供商,有:字节跳动、知道创宇。
(三)字节跳动:大模型应用防火墙
火山引擎大模型应用防火墙,提供大语言模型推理服务安全防护产品,确保输入、输出内容双向的隐私、安全、可用、可信,保护大语言模型不会受到OWASP LLM Top10攻击,提供了算力消耗攻击、提示词攻击等的安全防护。
(四)知道创宇:创宇大模型网关
创宇大模型网关是知道创宇针对大模型接入安全推出的一款安全防护网关类产品。产品采用代理方式进行部署,接入方式符合OpenAI API协议的大模型接口或第三方AI网关接口,支持大模型统一接入管理,大模型可观测,以及敏感数据泄露、内容安全等多维度安全防护能力。
安全围栏
安全围栏 为AI Agent行为设置“软硬边界”,限制其在特定业务范围内的权限与能力,防止Agent越权操作、执行恶意指令或引发业务风险。通常通过预设的权限策略、行为白名单或执行路径规则,在智能系统执行过程中动态进行决策拦截,从而防止越权行为、数据泄露和意图偏移,是Agent系统安全的一道重要防护线。
适用场景:相对大模型安全网关,安全围栏一种更精细的、动态的策略约束机制。适用于上下文分析、行为约束、数据访问等场景。通常部署在内部Agent系统/智能体框架中,在模型运行时或Agent执行阶段,限定模型使用范围、行为边界和权限约束。
国外安全围栏代表性提供商,如,Google。
(一)(美国)Google:Vertex AI Guardrails
Vertex AI Guardrails是Google面向企业级生成式AI应用推出的系统性安全机制,覆盖从内容审查、工具调用控制、身份隔离到配置监控的多维防护。对于构建复杂Agent系统或业务敏感型AI应用的场景,Guardrails能在执行路径内直接施加策略边界。相关研究显示,在G2平台上,Vertex AI Guardrails 的内容审核规则与合规检测功能达到了约 90%的用户满意度。
国内安全围栏的代表性提供商,如:中电信人工智能科技、数美科技、绿盟科技。
(二)中电信人工智能科技:AIGC安全治理方案
中电信人工智能科技全称 中电信人工智能公司安全运营公司,成立于2023年11月,其前身是中国电信集团大数据和AI中心成立的分公司。2025年初,该公司面向基础大模型、大模型应用、智能体推出了AIGC安全治理方案。该方案聚焦于数据、模型、内容安全,提供AIGC训练语料处理、安全防护、内容标注能力、安全评测能力、深度伪造鉴别共六大核心能力。通过SaaS化方式,支持多租户、多场景定制化策略,内置30+检测引擎,能实时拦截输入/输出风险。
(三)数美科技:AIGC应用安全围栏
数美科技 成立于2015年6月,是一家专业的在线业务和内容风控解决方案提供商。针对AIGC应用面临的风险挑战,数美科技基于内容合规以及账号安全领域的积累,推出AIGC应用安全围栏解决方案。产品贯穿“数据-模型-运营”全链条,提供了发布前合规支持,运营中内容审核和账户防护等风险防控能力。
(四)绿盟科技:大模型应用安全防护WAF-SLLM
绿盟科技推出的大模型应用安全防护WAF-SLLM,从大模型的WEB应用安全及API保护出发,提供场景化的安全防护能力,覆盖大模型应用下的供应链安全场景、数据安全场景、运营安全场景,保障用户的大模型应用能够安全高效地发展。
- 内容合规:对模型输入内容进行安全校准,并确保模型输出内容满足合规要求,及内容正确性监测。
- 数据安全:对模型返回的敏感数据进行检测,规避隐私窃取场景。
- 模型安全:针对提示注入、越狱攻击等输入进行安全检测,提高大模型自身的安全性与鲁棒性。
评测、网关与围栏的区别
从评测、网关、围栏的区别来看,三者在目标定位、作用层级、部署方式、运行阶段、技术手段等多个维度有显著区别,如表所示。
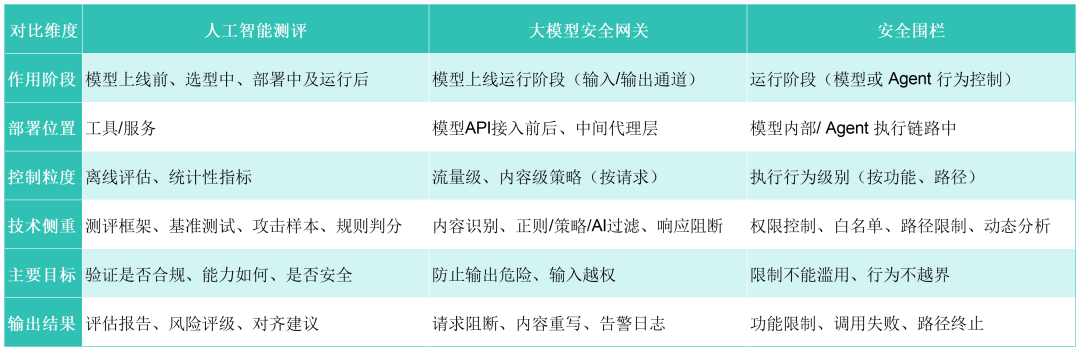 评测、网关与围栏的区别
评测、网关与围栏的区别
二、AI Agent系统可信治理的“三道防线”
随着大语言模型和多智能体系统在各行业的广泛应用,如何实现系统安全、可控、可信地运行,成为企业和机构部署AI Agent系统时必须优先考虑的问题。
本节基于AIGC安全能力的研究和调研,结合评测、网关、围栏三大安全能力之间的区别和联系,进而提出AI Agent系统可信治理的“三道防线”。
(一)第一防线:模型测评——“识别风险,建立基线”
人工智能测评是Agent系统可信治理的起点,主要在模型上线前进行,对模型本身的能力边界与潜在风险进行系统化评估。通过人工测试与自动化测评结合,可以从以下几个维度开展:
- 功能评估:包括问答准确性、逻辑推理能力、多轮对话连贯性等。
- 安全性评估:涵盖提示注入攻击(Prompt Injection)、越狱(Jailbreak)、敏感信息响应等。
- 合规性评估:检测是否违反法律法规或伦理道德边界,如虚假信息、歧视性言论、涉政内容等。
测评结果可以转化为安全策略基线,为后续网关与围栏的规则设计提供数据支撑。例如,通过测评发现某类提示注入攻击有效,则应在网关侧部署相应检测策略。
(二)第二防线:安全防护——“拦截风险,防止扩散”
安全网关与安全围栏是AI Agent系统安全防护体系中两个层次递进、侧重点不同的核心能力。尽管在功能上存在一定重叠,例如对模型输入输出的风险控制,但在系统定位、控制机制与设计目标上各有侧重。工程中,可以整合为一个产品,也可以作为两个独立模块存在,具体取决于厂商的架构设计与应用场景需求。
安全网关属于外部防护层,特别适用于多访问用户、API开放或大规模使用场景,是确保模型可控性的核心组件。大模型安全网关主要部署在Agent系统的输入输出接口处,作为运行时的安全守门员,承担内容审查、风险识别、访问控制等功能。
- 输入拦截:识别危险Prompt、恶意用户输入、越权访问请求等,提前阻断潜在攻击。
- 输出过滤:对模型生成内容进行实时监测,避免泄露PII(个人身份信息)、涉敏输出或违法内容。
- 策略控制与日志审计:支持定制策略规则,记录所有风险行为以供追溯与合规审计。
安全围栏机制面向AI Agent系统的内部运行阶段,聚焦于对模型调用行为和功能边界的限制与治理。通常与Agent框架(如LangChain、AutoGen、企业自研平台)深度集成。
- 功能调用限制:通过角色权限管理(RBAC)、白名单控制、调用频次限制等手段,规范模型对外部工具/插件/数据库等的访问能力。
- 执行路径设定:预设任务执行流程,限制非预期的跳转、嵌套或越权操作。
- 行为策略监控:在系统内部追踪模型行为路径,对敏感操作进行事前拦截或事中确认。
(三)第三防线:安全审计——合规溯源保障
在AI Agent系统高度自主化、复杂化的运行环境下,安全审计不仅是传统意义上的日志记录工具,更是支撑整个系统可信治理、安全响应与合规保障的基础能力,具有不可替代的重要作用。承担着对系统运行全流程进行记录、追溯、取证与问责的关键职责,是实现可解释、可监管、可溯源的核心保障机制。
- 行为可追溯 记录AI Agent在任务执行过程中的关键行为轨迹,包括感知输入、内部推理、决策路径、输出内容及交互对象;支持“谁发起、调用了什么、如何推理、最终结果为何”全过程追踪。
- 提示词与响应日志留存 审计AI Agent与大模型之间的提示词交互内容,可用于检测提示注入、越权意图、敏感生成等风险;为Prompt安全管控、内容合规稽核提供数据基础。
- 策略执行验证 审计各类安全策略(如访问控制、输出过滤、安全围栏)是否生效,是否被绕过,辅助策略优化。
- 异常行为识别与溯源 结合日志分析和行为画像技术,可对“Agent越权行为”“模型输出异常”“系统调用违规”等事件进行实时检测与反向追溯。
- 支持合规与问责要求 满足国家数据安全、内容合规、算法备案等监管要求,建立清晰的审计责任链;为后续责任认定、事故处理提供取证依据。
AI Agent系统的智能化水平越高,其潜在的不确定性与风险也越大。三道防线在AI Agent整体架构中构成“预测-防御-检测-响应-审计”的完整闭环,是保障AI Agent系统稳定、安全、合规运行的必由之路。未来,随着大模型能力演进与业务复杂性提升,三道防线之间的联动机制将更加关键,值得所有AI系统建设者深度关注与持续优化。


