
在人工智能领域,检索增强生成(Retrieval-Augmented Generation,RAG)一直是研究热点。它通过结合检索和生成技术,为问答系统带来了更强大的性能。然而,现有的RAG方法并非完美无缺。它们在处理多跳推理或多步骤推理问题时可能力不从心,而且往往缺乏对检索到的信息的有效利用能力。
今天,就来聊聊一种全新的方法,来自韩国科学技术院发表在2024 NAACL上的一篇工作:自适应检索增强生成(Adaptive Retrieval-Augmented Generation,Adaptive-RAG)。
1、研究动机
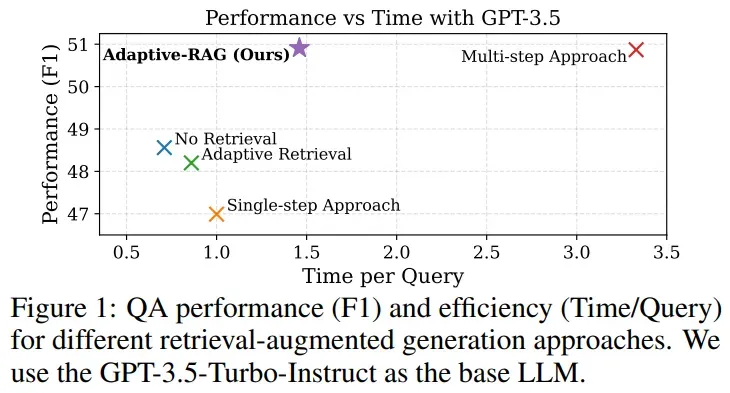
在实际应用中,不难发现,并非所有问答场景都是复杂请求。有些问题简单到直接使用语言模型(LLM)就能轻松回答,而有些问题则需要从多个文档中综合信息并进行多步推理。这就导致了一个问题:如果对所有问题都采用复杂的RAG策略,无疑会造成资源浪费;而如果对复杂问题只使用简单的LLM方法,又无法得到准确的答案。那么,如何在效率和准确性之间找到一个平衡点呢?Adaptive-RAG应运而生。
2、方法介绍
现有LLMs问答策略
在深入探讨Adaptive-RAG之前,先来了解一下现有的LLM问答策略。
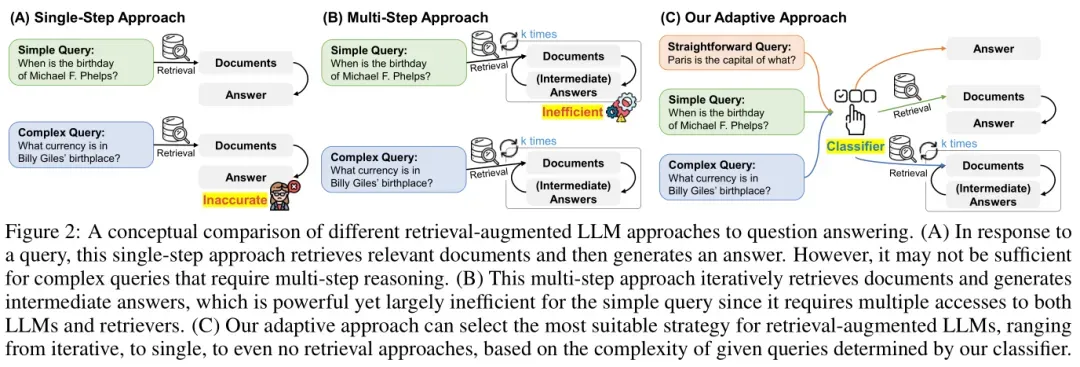
- 非检索方法(Non-Retrieval for QA):对于一些简单的查询,LLM可以直接生成答案,无需进行额外的文档检索。不过,当问题涉及到需要精确或最新的知识时,如特定人物、事件或其他超出 LLM 内部知识范围的主题,这种方法就显得有些力不从心了。
- 单步检索方法(Single-step Approach for QA):当LLM无法直接回答问题时,可以利用外部知识执行一次检索操作,然后根据检索到的信息生成答案。这种方法能够为LLM缺乏内部知识提供补充上下文,从而提升问答的准确性和时效性。
- 多步检索方法(Multi-step Approach for QA):在多步方法中,LLM与检索模型进行多轮交互,逐步完善对查询的理解,直到最终形成答案。这种方法能够为LLM构建更全面的知识基础,特别适合处理复杂的多跳查询,但是会有更大的计算和资源开销。
Adaptive-RAG
在实际应用中,并非所有用户的查询都具有相同的复杂程度,因此需要针对每个查询定制处理策略。换句话说,对于复杂查询,如果只使用最基本、不带检索的 LLM 方法(LLM(q)),则会无效;相反,对于简单查询,如果采用更复杂的多步骤方法(LLM(q, d, c)),则会导致资源浪费。因此,Adaptive-RAG 试图找到一个平衡点,以提高效率和准确性。
- 查询复杂度评估Adaptive-RAG 的关键步骤是确定给定查询的复杂度,从而选择最合适的回答策略。为了实现这一点,本文训练了一个小型的语言模型作为分类器,用来预测即将到达的查询的复杂度级别。具体来说,对于给定的查询 q,分类器可以被公式化为:o = Classifier(q),其中 Classifier 是一个小的语言模型,它被训练用来分类三个不同的复杂度等级,而 o 则是其对应的类别标签。在设计中,有三个类别标签:
a. 'A' 表示查询 q 直接且可以用 LLM(q) 自身回答。
b. 'B' 表示查询 q 具有中等复杂度,至少需要单步方法 LLM(q, d) 来解决。
c. 'C' 表示查询 q 复杂,需要最全面的方法 LLM(q, d, c) 来解决。
- 训练策略使用T5-Large(770M)模型作为查询复杂性分类器,对于分类器的训练,关键步骤是如何准确预测查询 q 的复杂度 o。然而,现实中并不存在带有查询复杂度标注的数据集。因此,本文提出了两种特定策略来自动构建训练数据集:通过这两种方式,可以在无需人工标注的情况下构造出适合训练分类器的数据集。这种自动化收集标签的方法不仅减少了人力成本,还确保了数据集的一致性和客观性,使得分类器能够学习到不同类型的查询特征,并准确地对新查询进行复杂度分类。
- 基于模型预测结果的自动标注:如果最简单的非检索方法 LLM(q) 能正确生成答案,则将对应的查询标记为 'A'。如果多步骤方法 LLM(q, d, c) 能正确生成答案,而非检索方法 LLM(q) 不能,则将查询标记为 'B' 或 'C',具体取决于是否还有更复杂的查询未被标记。
- 利用数据集中的固有归纳偏见:一些数据集本身已经设计成包含用于单步或多重推理的问题,这些信息可以作为辅助来帮助标注查询的复杂度。对于那些初次标注后仍未获得标签的查询,如果它们来自单跳数据集,则标记为 'B';如果是多跳数据集,则标记为 'C'。
3、实验配置
数据集
单跳问答数据集(Single-hop QA):用于模拟简单查询的场景,包括以下三个基准数据集:
- SQuAD v1.1:由标注者根据文档编写问题而创建的数据集。
- Natural Questions:由Google搜索的真实用户查询构建的数据集。
- TriviaQA:包含来自各种问答网站的琐事问题。
多跳问答数据集(Multi-hop QA):用于模拟复杂查询的场景,包括以下三个基准数据集:
- MuSiQue:通过组合多个单跳查询来形成2-4跳查询的数据集。
- HotpotQA:由标注者创建的问题链接多个维基百科文章。
- 2WikiMultiHopQA:从维基百科及其相关知识图谱路径派生而来,需要2跳。
指标
- 有效性指标:F1:预测答案与真实答案之间重叠词汇的数量。EM(Exact Match):预测答案与真实答案是否完全相同。Accuracy(Acc):预测答案是否包含真实答案。
- 效率指标:Step:检索和生成步骤的数量。Time:相对于单步方法,回答每个查询所需的平均时间。
4、实验结果
主要结果
整体性能:表1展示了所有数据集的平均结果,验证了简单检索增强策略的有效性低于复杂策略,而复杂策略的计算成本显著高于简单策略。Adaptive-RAG在保持高效的同时,显著提高了问答系统的整体准确性和效率。
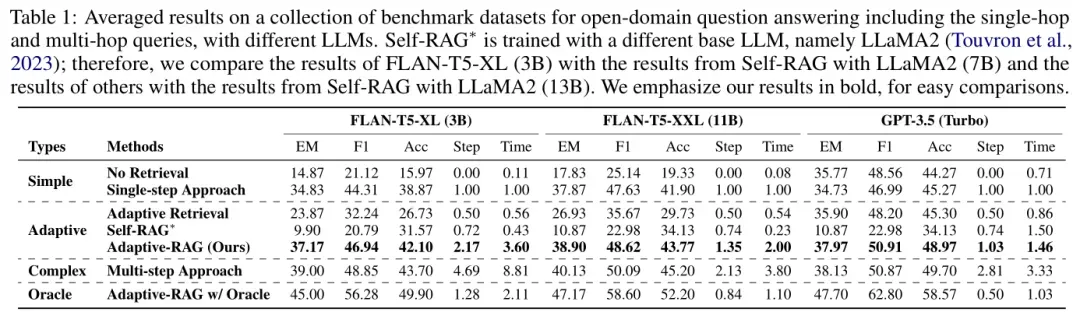
详细结果:表2提供了使用FLAN-T5-XL模型在各个单跳和多跳数据集上的更详细结果,与表1中的观察结果一致。Adaptive-RAG在处理复杂查询时表现出色,尤其是在多跳数据集上,能够有效地聚合多个文档的信息并进行推理。
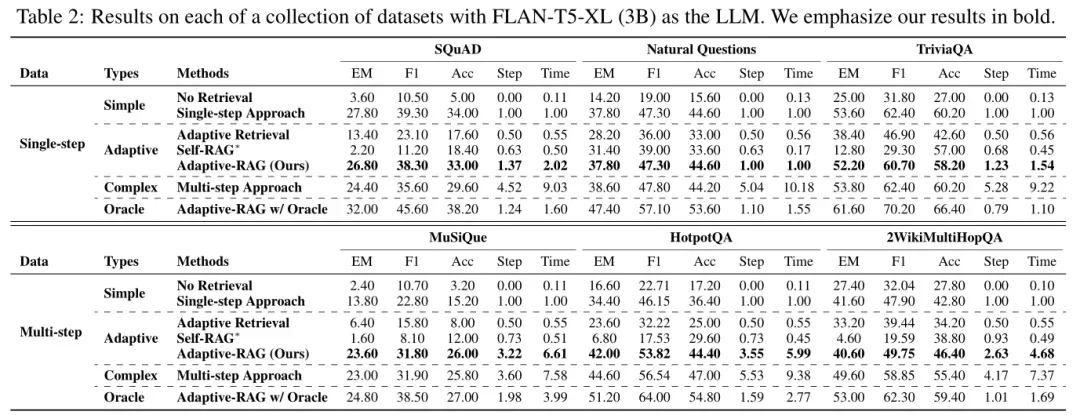
理想情况下的性能:通过使用理想分类器(Oracle)的Adaptive-RAG,展示了模型在完美分类查询复杂性情况下的性能上限。结果表明,它在效果上达到了最佳表现,同时比没有理想分类器的Adaptive-RAG更加高效。这些结果支持了根据查询复杂度自适应选择检索增强LLM策略的有效性和重要性。
分类器性能
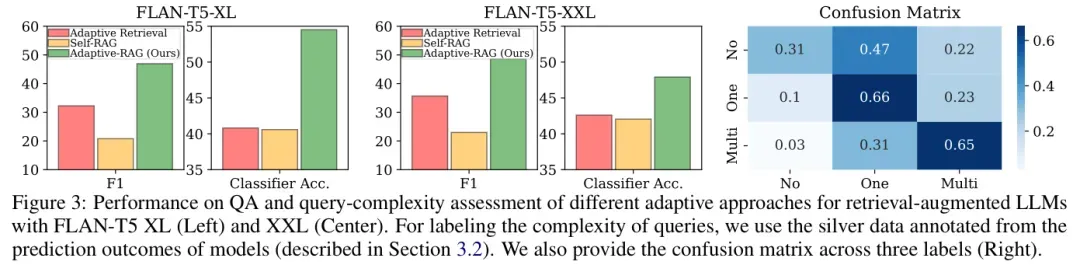
分类准确性:图3展示了Adaptive-RAG的分类器在不同复杂性标签上的性能,其分类准确性优于其他自适应检索方法。这表明Adaptive-RAG能够更准确地将查询分类为不同复杂性级别,从而为选择合适的检索策略提供依据。
混淆矩阵:图3中的混淆矩阵揭示了一些分类趋势,例如“C(多步)”有时被错误分类为“B(单步)”,“B(单步)”有时被错误分类为“C(多步)”。这为未来改进分类器提供了方向。
分类器效率分析
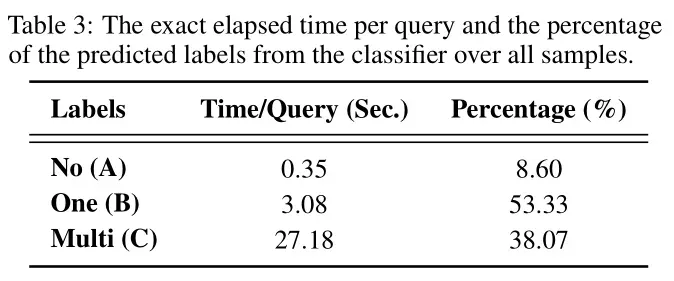
查询处理时间:表3提供了Adaptive-RAG每条查询的精确处理时间以及分类器预测标签的分布情况。结果表明,通过有效识别简单或直接的查询,可以显著提高效率。
分类器训练数据分析
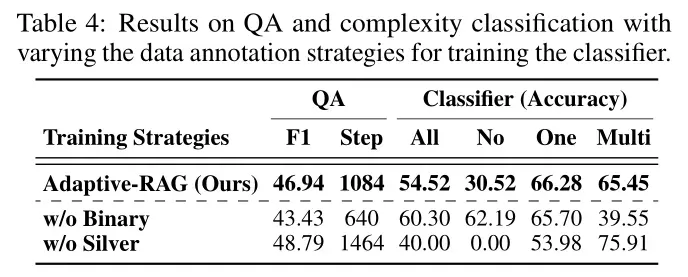
训练策略对比:表4展示了不同训练策略对分类器性能的影响。作者提出的训练策略(结合模型预测结果和数据集偏见)在效率和准确性方面均优于仅依赖数据集偏见或仅使用银标准数据的策略。这表明,结合多种信息源可以提高分类器的性能。
分类器大小分析
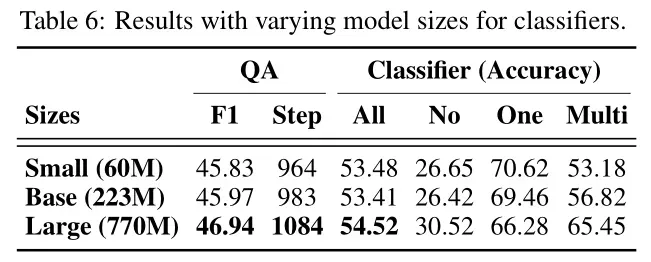
模型大小对性能的影响:表6显示了不同大小分类器的性能。结果表明,即使在分类器规模较小、复杂度较低的情况下,性能也没有显著差异。这表明Adaptive-RAG可以在资源受限的环境中使用较小的分类器,而不影响整体性能。
案例研究
简单查询处理:对于简单的单跳问题,Adaptive-RAG能够识别出仅使用LLM的参数知识即可回答,而无需检索外部文档。相比之下,其他自适应方法可能会检索额外的文档,导致处理时间延长,并可能因包含部分不相关信息而产生错误答案。
复杂查询处理:面对复杂问题时,Adaptive-RAG能够寻找相关的信息,包括LLM中可能未存储的细节,如“John Cabot的儿子是谁”,而其他自适应方法可能无法从外部源请求此类信息,从而导致不准确的答案。

5、总结
Adaptive-RAG是一种非常有意思的方法。它通过一个小模型辅助LLM判断是否需要单步检索或多步检索,相比一些直接微调LLM的方法(如Self-RAG),不仅更高效,而且性能也更优。
但是如果要在检索推理性能上扣细节的话,这种策略还是有很多优化空间,比如在2023 ACL上的一篇文章《When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories》评估了LLM检索哪些类型的知识对模型性能的提高更有益,哪些类型的知识可能会损害模型性能,这些皆是可以使用小模型辅助LLM判断的参考信息。
这种方法为普通玩家提供了一个可行的解决方案,也为RAG方法的优化提供了新的思路。


