
本文作者为:En Yu, Jie Lu, Kun Wang, Xiaoyu Yang, Guangquan Zhang。所有作者均来自于悉尼科技大学(UTS)澳大利亚人工智能研究院(AAII)。
在智慧城市、社交媒体、工业物联网等真实开放动态环境中,数据往往以多流(Multistream)形式并发产生。然而,现实世界并非完美的实验室,这些数据流往往存在异构性,且分布变化各不相同,伴随着复杂的异步概念漂移。
如何让模型既能 “专精” 于单一流的特性,又能 “博采众长” 利用流间相关性,同时还能自适应分布变化?
悉尼科技大学(UTS)研究团队提出了一种全新的漂移感知协作辅助混合专家学习框架 —— CAMEL (Collaborative Assistance Mixture of Experts Learning)。
CAMEL 巧妙地将混合专家模型(MoE)引入流式学习,通过 “私有专家” 与 “辅助专家” 的协作机制,以及自动化专家生命周期管理,完美解决了异构多流学习中的关键问题。该工作已被 AAAI 2026 接收为 Oral 论文。

论文标题:Drift-aware Collaborative Assistance Mixture of Experts for Heterogeneous Multistream Learning
论文链接:https://arxiv.org/abs/2508.01598
01 引言
在真实应用场景中,数据通常以连续且无限的数据流形式产生,其生成机制往往呈现显著的非平稳性,即数据的联合概率分布随时间发生不可预测的概念漂移。这一特性与经典机器学习所依赖的独立同分布(I.I.D.)假设存在根本冲突。
然而,现有研究大多聚焦于单一或同构数据流的漂移建模,难以应对真实世界中普遍存在的多源异构数据流情形。以智能城市为例,交通传感器、气象观测、公共交通记录及社交媒体等信息流在时间尺度与演化模式上彼此独立,却潜藏着重要的动态关联。若能在概念漂移过程中有效挖掘并利用这些跨流关系,将显著提升决策的准确性与鲁棒性。
现有的方法往往陷入两难:要么假设所有流是同构的,强行统一处理导致模型失配;要么采用静态模型,一旦某个流发生漂移,重新训练会导致 “灾难性遗忘”,而增量微调又可能因为流之间的不同步演化而引发 “负迁移” 。
为此,作者正式定义了异构多流学习(HML)问题,并提出 CAMEL 框架。这是一种动态的、通过协作辅助的混合专家学习框架,通过模块化设计在 “专精 — 协作 — 适应” 之间取得平衡。
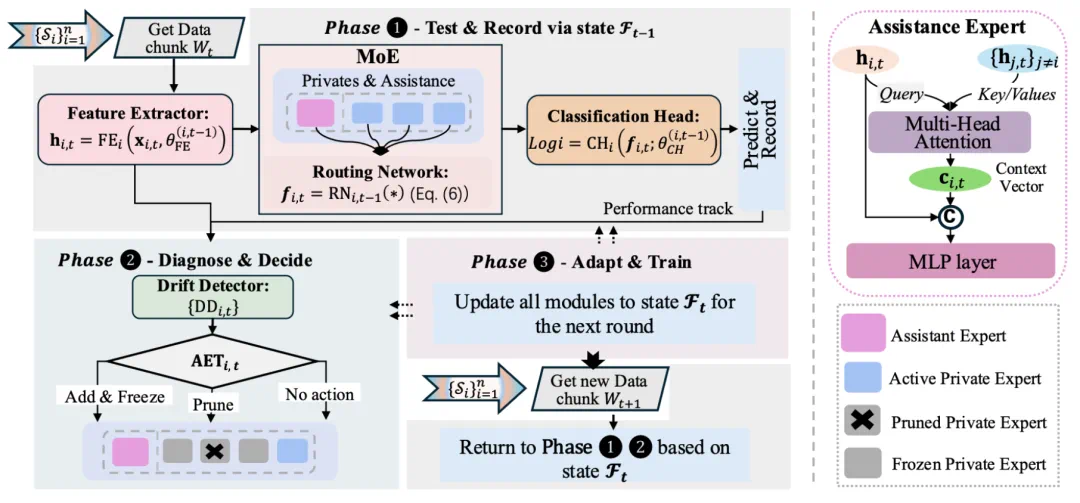
图 1:CAMEL 整体框架。每个流的 MoE 模块利用动态的私有专家库和专用的辅助专家,通过多头注意力进行协作融合。系统遵循 “测试 - 诊断 - 适应” 的循环,通过自主专家调节器动态管理专家生命周期以响应漂移信号。
02 方法论与架构设计
研究团队面向 HML 场景下的三大核心挑战:内在异构性、多流知识融合以及异步概念漂移,设计了一套模块化的漂移感知架构。
挑战一:内在异构性
传统的多流学习方法通常假设所有流共享特征空间与标签空间,但现实中不同流可能具有不同维度 (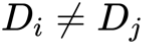 ) 与任务目标 (
) 与任务目标 (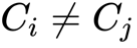 )。
)。
CAMEL 为每个流配置异构感知的 “独立系统”:
特征对齐: 为每一个数据流
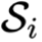 配备了专属的 特征提取器
配备了专属的 特征提取器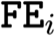 ,将不同维度的原始输入映射到一个公共的潜在空间
,将不同维度的原始输入映射到一个公共的潜在空间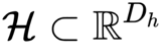 ,为后续的特征交互奠定基础。
,为后续的特征交互奠定基础。任务专精:在输出端,配备了任务特定分类头
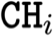 ,独立处理各自的分类任务,确保决策层与标签空间的语义对齐。
,独立处理各自的分类任务,确保决策层与标签空间的语义对齐。
挑战二:多流知识融合
多流数据的核心价值在于流之间的潜在相关性,但盲目融合所有流的信息会导致负迁移。
CAMEL 除了为每个流维护一组捕捉自身特性的私有专家库外,还引入了一个辅助专家,它利用多头注意力机制:以当前流的特征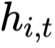 作为 Query;以所有其他并发流的特征
作为 Query;以所有其他并发流的特征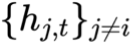 作为 Key 和 Value;生成上下文向量
作为 Key 和 Value;生成上下文向量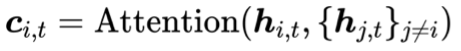 。通过这种机制,模型能够自主决定从哪些流中借力。如果其他流无帮助时,注意力权重会自然衰减,从而自适应抑制负迁移。
。通过这种机制,模型能够自主决定从哪些流中借力。如果其他流无帮助时,注意力权重会自然衰减,从而自适应抑制负迁移。
挑战三:异步概念漂移
面对数据分布的非平稳性,CAMEL 设计了自主专家调优器 ,在专家粒度上实现模型容量的在线伸缩,遵循 “测试 - 诊断 - 适应” 的闭环逻辑:
漂移检测:利用基于最大均值差异(MMD)的漂移检测器监控特征分布变化。
增量式扩展(Add & Freeze): 当检测到漂移且伴随性能显著下降时, 实例化一个新的私有专家学习新概念,并冻结旧专家以规避灾难性遗忘。
自适应剪枝(Prune): 对于长期利用率(由路由网络权重决定)低下的冗余专家,"
 " 执行剪枝操作,维持模型的稀疏性与推理效率。
" 执行剪枝操作,维持模型的稀疏性与推理效率。
由于每个流拥有独立的 ,CAMEL 能够自适应地处理多流之间的异步漂移,即只在需要的时候对相关流进行架构调整。
,CAMEL 能够自适应地处理多流之间的异步漂移,即只在需要的时候对相关流进行架构调整。
03 理论分析与实验验证
理论分析:基于多任务学习理论,论文证明了 CAMEL 的泛化误差上界。 定理 1 表明,CAMEL 的期望风险由平均经验风险、流间不相似度 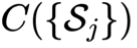 以及样本复杂度项构成。这意味着,辅助专家通过注意力机制最小化了流间的不相似度代价,而路由网络平衡了协作与专精。这为 CAMEL 在复杂环境下的鲁棒性提供了数学解释。
以及样本复杂度项构成。这意味着,辅助专家通过注意力机制最小化了流间的不相似度代价,而路由网络平衡了协作与专精。这为 CAMEL 在复杂环境下的鲁棒性提供了数学解释。

实验验证:为了验证 CAMEL 的有效性,研究团队构建了包含 12 个合成流和 4 个真实数据集(涵盖了天气、新闻、信用卡信息等)的 8 大基准场景。
表 1 中的结果表明,CAMEL 在几乎所有场景中实现了最先进的平均准确率,显著超越了单流基线(SRP、AMF、IWE)和多流方法(MCMO、OBAL、BFSRL)。CAMEL 的优越性在异构环境中尤为明显,现有的多流方法由于依赖共享特征或标签空间而失败。相比之下,CAMEL 的流特定模块能够在输入异构下实现稳健的性能。该框架还通过其协作辅助机制有效利用潜在的流间相关性,超越了单流方法。
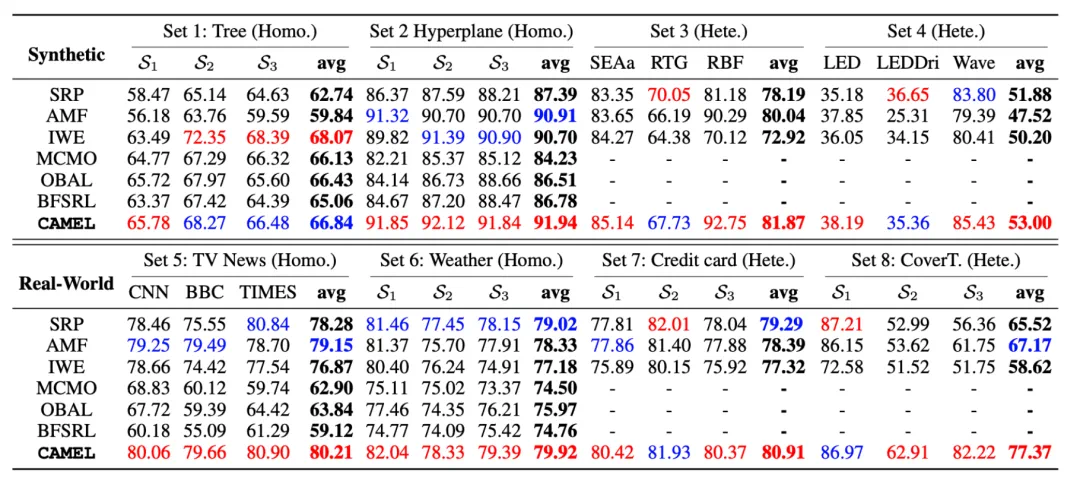
表 1:各方法在所有基准上的分类准确率(%)。红色代表最优,蓝色代表次优。
04 结语
CAMEL 的提出标志着多流学习从 “静态同构” 向 “动态异构” 迈出了关键一步。 该框架以私有专家保障流内专精,以辅助专家挖掘跨流关联,并通过自动化的专家生命周期管理在漂移下实现持续适应与效率控制,为复杂、动态演化的异构多流场景提供了一种可扩展的解决方案。


