
多语言大模型(MLLM)在面对多语言任务时,往往面临一个选择难题:是用原来的语言直接回答,还是翻译成高资源语言去推理?
实际上,不同的语言在模型内部承载着不同的「特长」。比如英语可能逻辑性强,适合科学推理;而中文或印尼语在处理特定文化背景或押韵任务时,可能比英语更具优势。
如何让模型在面对不同任务时,自动选择一条「最顺手」的推理路径?来自新加坡科技研究局(A*STAR)Nancy F. Chen 和 Ai Ti Aw 带领的研究团队,携手新加坡科技设计大学(SUTD)Roy Ka-Wei Lee 教授团队共同推出了 AdaMCoT(Adaptive Multilingual Chain-of-Thought)框架。AdaMCoT 的核心在于把 「用哪种语言思考」本身当成一个可优化的决策变量:通过自适应地在多种语言间路由并组合链式思考,再将推理结果映射回目标语言,从而显著提升跨语言的事实推理准确性与一致性。该工作已被 AAAI 2026 主轨道接收为 Oral 论文。

论文标题: AdaMCoT: Rethinking Cross-Lingual Factual Reasoning through Adaptive Multilingual Chain-of-Thought
论文链接: https://arxiv.org/abs/2501.16154
作者单位: 新加坡 A*STAR Institute for Infocomm Research(I²R)、新加坡科技设计大学(SUTD)
研究背景与痛点
现有的跨语言推理方法通常存在「路径依赖」:要么不做处理直接推理,容易导致低资源语言的幻觉;要么强制全部转换成英语推理,这在处理需要保留原语言文化韵味或特定语义的任务(如写诗、双关语)时,往往会弄巧成拙。
核心问题在于:没有一种单一的语言适合所有的任务。
为了解决这一问题,研究团队提出了 AdaMCoT 框架。与其强制模型「说英语」,不如赋予模型一种自适应的元认知能力。AdaMCoT 能够根据输入问题的特性(是逻辑题、文化题还是常识题),动态地从候选语言池(Thinking Languages)中「路由」出一条最佳的思维路径。

方法与创新:让模型「换种语言思考」
AdaMCoT 并不是「先翻译再回答」,而是引入了一个自适应路由机制(Adaptive Routing):模型会根据问题特性,选择是直接用目标语言推理,还是先在英语、中文等「思考语言」中展开链式思考,再回到目标语言给出答案。
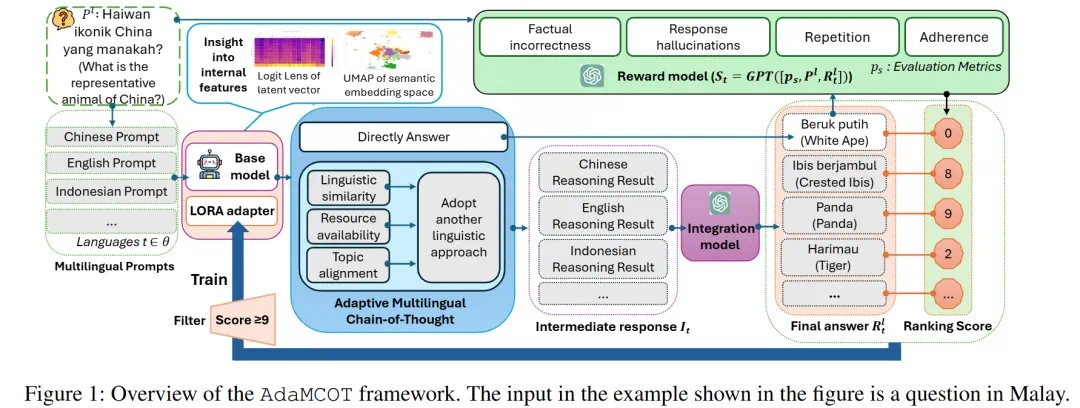
1. 双路径推理机制
AdaMCoT 设计了两条主要的推理路径:
跨语言思维链(Cross-Lingual CoT):对于与提示语言不适配的任务,模型将综合考虑主题一致性、语言知识丰富程度等因素,选取一个合适的 “思考语言”。例如面对使用马来文提问的数学题,模型可以选择英文或者中文作为思考语言,利用这些语言丰富的逻辑和知识储备完成推理步骤,最后将结果整合回目标语言。
直接生成(Direct Generation):对于模型本身擅长的语言或特定任务(如写诗、押韵),直接在源语言上进行分析且生成答案,避免跨语言带来的语义损耗。
2. 基于奖励的自适应路由
为了让模型「知道」何时该用哪种语言思考,研究团队引入了一个基于奖励的微调机制。利用 GPT-4o 作为奖励模型(Reward Model),从事实正确性、连贯性和指令遵循度等维度对不同推理路径生成的答案进行打分。
在训练阶段,模型只学习那些得高分(分数 ≥ 9)的推理路径。这种「优胜劣汰」的机制使得 AdaMCoT 能够根据问题类型自动切换策略。例如,处理科学问题时可能倾向于用英语思考,而处理具有文化特色的问题时则可能保留原语言。
实验结果:全面超越传统方法
研究团队在 mTruthfulQA、CrossAlpaca-Eval 2.0、Cross-MMLU 和 Cross-LogiQA 等多个多语言基准上评估了 AdaMCoT,涵盖了 LLaMA 3.1 和 Qwen 2.5 等主流开源模型。
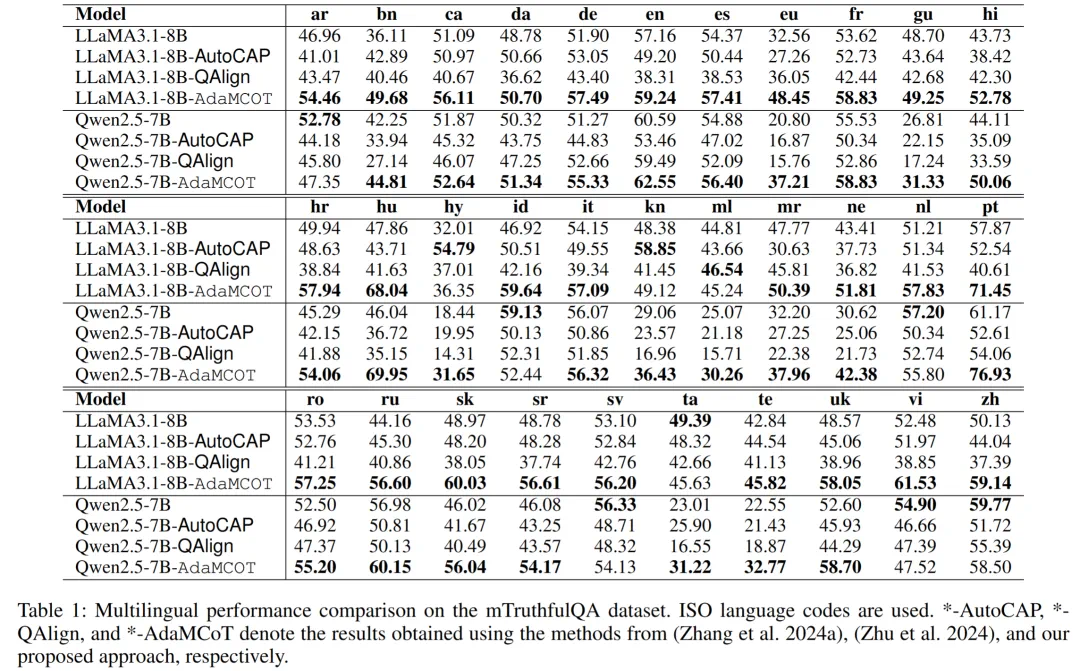
1. 事实推理能力显著提升
在 mTruthfulQA 数据集上,LLaMA3.1-8B-AdaMCoT 在 32 种语言中的 31 种上都取得了性能提升。
对于中文,准确率相对原模型提升 9.0%;
对于低资源语言如印度尼西亚语,相对提升高达 12.7%;
在匈牙利语、葡萄牙语和孟加拉语等语言上,更是实现了超过 10% 的绝对提升。
相比之下,传统的 Prompt 工程方法(如 AutoCAP)和翻译对齐方法在低资源语言上往往表现不佳,甚至出现倒退。
2. 跨语言一致性增强
实验表明,AdaMCoT 不仅提高了回答的准确率,还显著增强了跨语言的一致性。这意味着无论用户用哪种语言提问,模型都能调用其内部最一致的知识库来回答,减少了「见人说人话,见鬼说鬼话」的幻觉现象 。
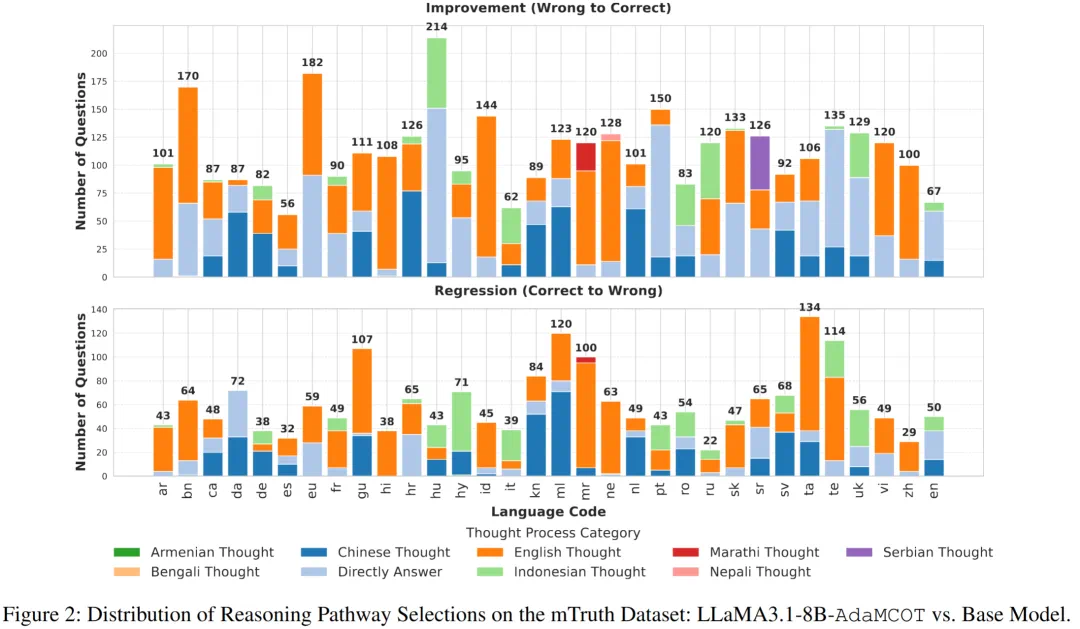
在 mTruthfulQA 数据集上的推理路径选择分布。大部分情况下,模型优先选择高资源语言(尤其是英语和中文)作为中间推理语种,从而显著降低错误率;其他语种约占 10%,主要用于提升特殊类别问题的回答准确性。
深度解读:为什么「换语言思考」有效?
为了揭示 AdaMCoT 的生效机理,研究团队利用 Logit Lens 和 UMAP 技术对模型的内部状态进行了可视化分析。
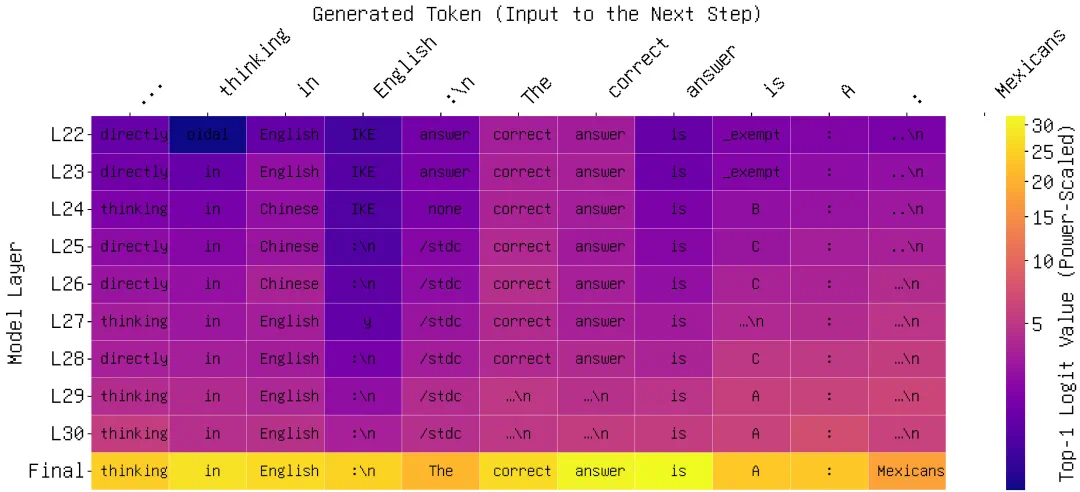
1. Logit Lens:透视模型的思考过程
通过 Logit Lens 分析发现,当模型直接用低资源语言回答复杂问题时,中间层的预测往往充满噪声和幻觉。而当 AdaMCoT 引导模型先用英语「思考」时,模型在早期层级就能锁定正确的事实路径,最终生成的答案更加自信且准确。
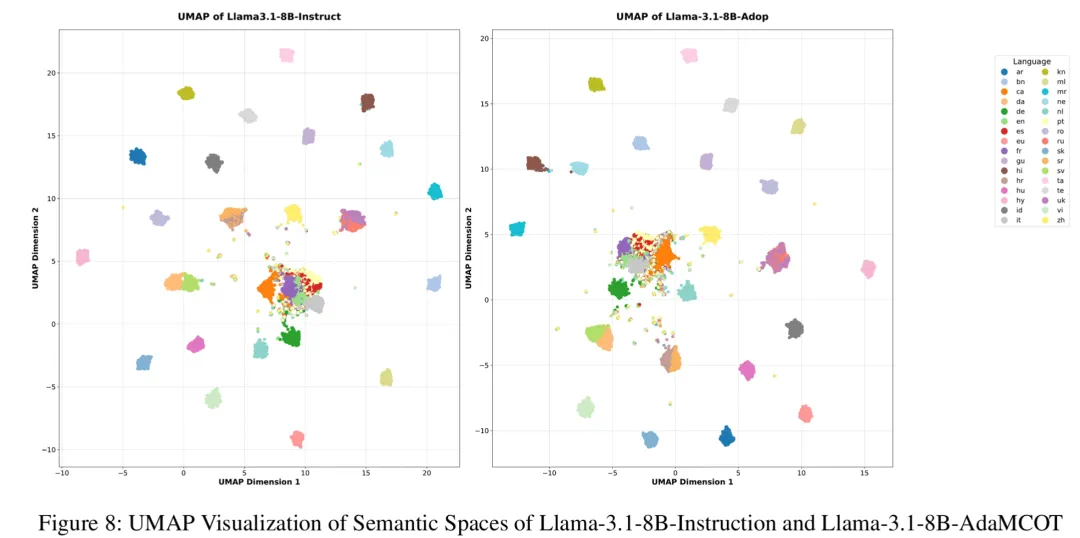
2. UMAP:语义空间的对齐
UMAP 可视化显示,AdaMCoT 成功拉近了不同语言在语义空间中的距离。经过微调后,非英语语言的嵌入向量(Embeddings)显著向英语中心靠拢。同时并没有破坏原有的语义结构,而是在保持整体分布的前提下,让多语言在同一空间中更加对齐。 这表明 AdaMCoT 促进了多语言知识在语义层面的深层融合,而非简单的表面翻译。
总结
AdaMCoT 提出了一种全新的多语言推理范式:不改变模型参数规模,不依赖海量多语言预训练数据,仅通过「学会如何选择思考语言」,就能显著释放大模型的跨语言潜能。
这项工作不仅为提升低资源语言的 AI 性能提供了低成本的高效方案,也为理解大模型的跨语言对齐机制提供了新的视角。随着 AI 全球化的推进,AdaMCoT 有望成为打破语言隔阂、实现「AI 普惠」的关键技术之一。


